GPT-3回答问题不靠谱?OpenAI找来人类“调教师”,终于给教明白了
晓查 发自 凹非寺
量子位 | 公众号 QbitAI
如何用几句话向6岁儿童解释登月?
GPT-3给出的答案实在离谱:
向孩子解释引力理论、相对论、大爆炸、进化论……

为了修正这样的“bug”,OpenAI在今天推出了全新的“指导版GPT”——InstructGPT模型。
InstructGPT甚至不用出全力,只要13亿参数,就能比1750亿参数的模型效果更好。
来看看InstructGPT是怎么回答的吧:
人类去月球,拍摄他们所看到的,然后返回地球,我们就看到了他们。
(People went to the moon, and they took pictures of what they saw, and sent them back to the earth so we could all see them.)
这一下子就合理多了,6岁孩子肯定能懂。
我们再看一个例子,GPT-3再次被InstructGPT无情碾压,不过这次换上了完全版,也就是1750亿参数的。
请问:以下这段C代码的用途是什么?
def binomial_coefficient(n, r):C = [0 for i in range(r + 1)];C[0] = 1;for i in range(1, n + 1):j = min(i, r);while j > 0:C[j] += C[j - 1];j -= 1;return C[r]
GPT-3的回答俨然是一台“复读机”:(叫你回答问题,没让你出题啊!)
A. to store the value of C[0]
B. to store the value of C[1]
C. to store the value of C[i]
D. to store the value of C[i - 1]
如果这玩意给GitHub的自动编码工具Copliot用,真的会把程序员带到沟里。
InstructGPT的回答简直就是计算机考试标准答案:
这段代码中的数组C是用来存储二项式系数值的。它用于计算给定n和r值的二项式系数,并将结果存储在函数的最终返回值中。
除了以上的案例外,还能避免将“淘气”和“女性”关联,或者将“犹太人”和“金钱”关联,避免触及性别种族歧视话题。
从人类反馈中学习
OpenAI是如何升级GPT-3的?
InstructGPT背后的研究人员使用“从人类反馈中强化学习”(RLHF),让GPT-3的输出更准确,并且有害性更低。
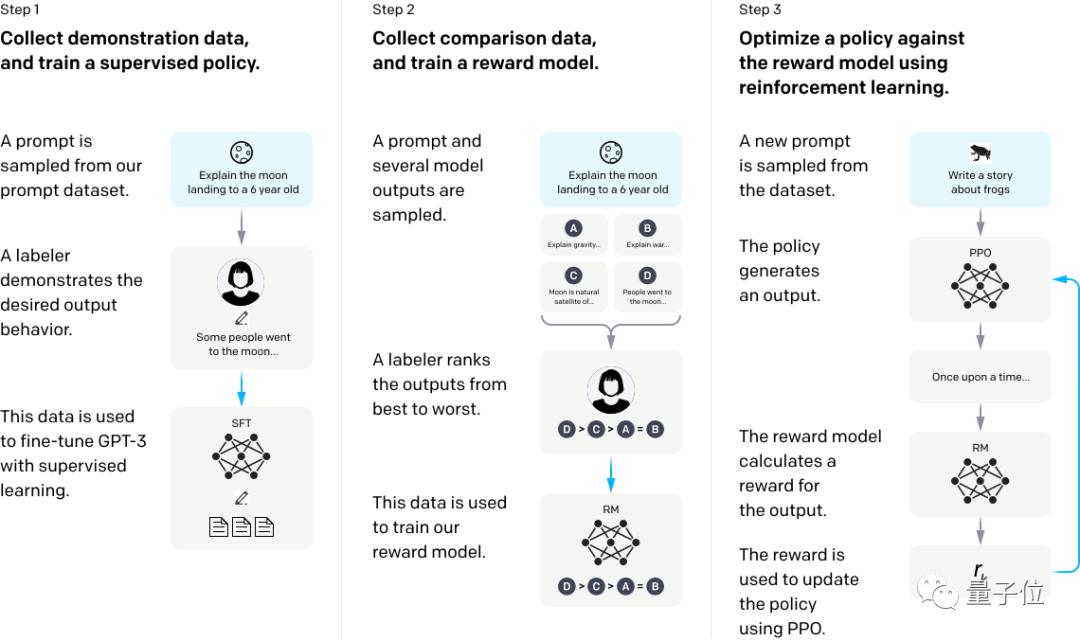
RLHF总共分三步:
第一步,找一些人写下示范答案,来微调GPT-3模型,训练监督模型baseline。
第二步,收集某个问题的几组不同输出数据,由人类对几组答案进行排序,在此数据集上训练奖励模型。
第三步,使用RM作为奖励函数,近端策略优化(PPO)算法微调GPT-3策略,以强化学习方法最大化奖励。
这种方法存在一个局限性在于它引入了“对齐问题”,因为模型仅根据对齐客户的NLP任务,那么可能会在学术NLP任务上的表现更糟。
OpenAI发现了一个简单的算法更改,可以最大限度地减少该问题:在强化学习微调期间,混合用于训练GPT-3原始数据的一小部分,并使用正态似然对最大化(normal log likelihood maximization)来训练这些数据。
这大致能保持内容安全和符合人类偏好,同时缓解学术任务上的效率下降,在某些情况下甚至超过了GPT-3 baseline。
实验结果
在公开数据集上,InstructGPT与GPT-3相比产生的模仿假象更少、有害性更低。而且InstructGPT编造事实的频率较低。
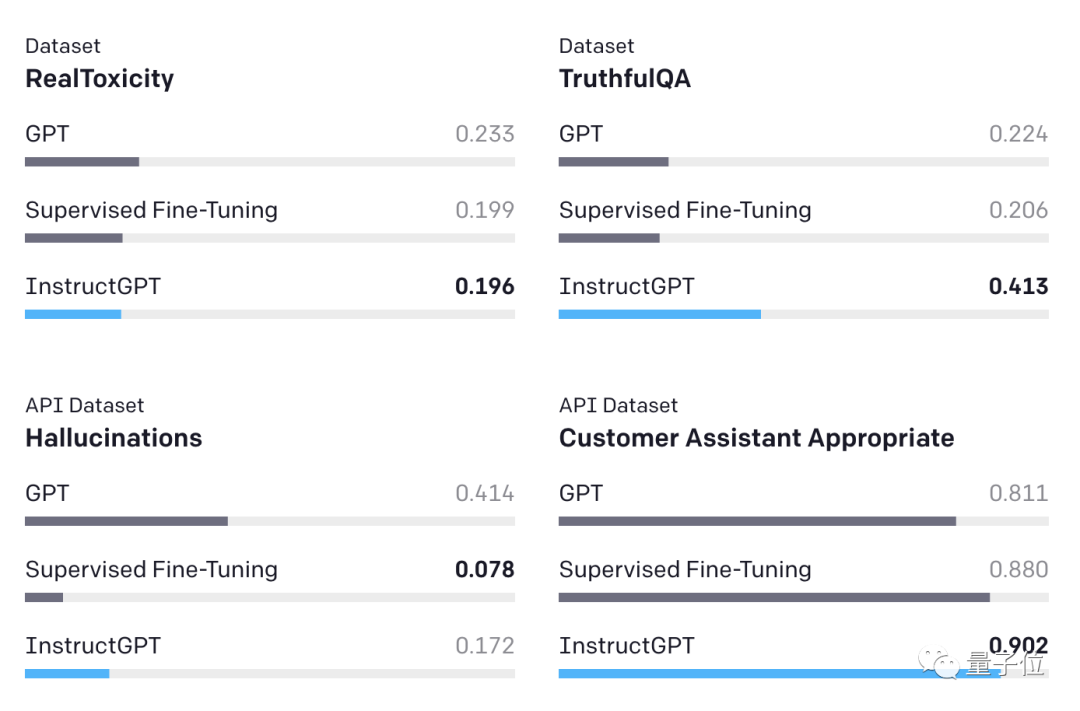
而且人类实际感受中也给InstructGPT打分更高。
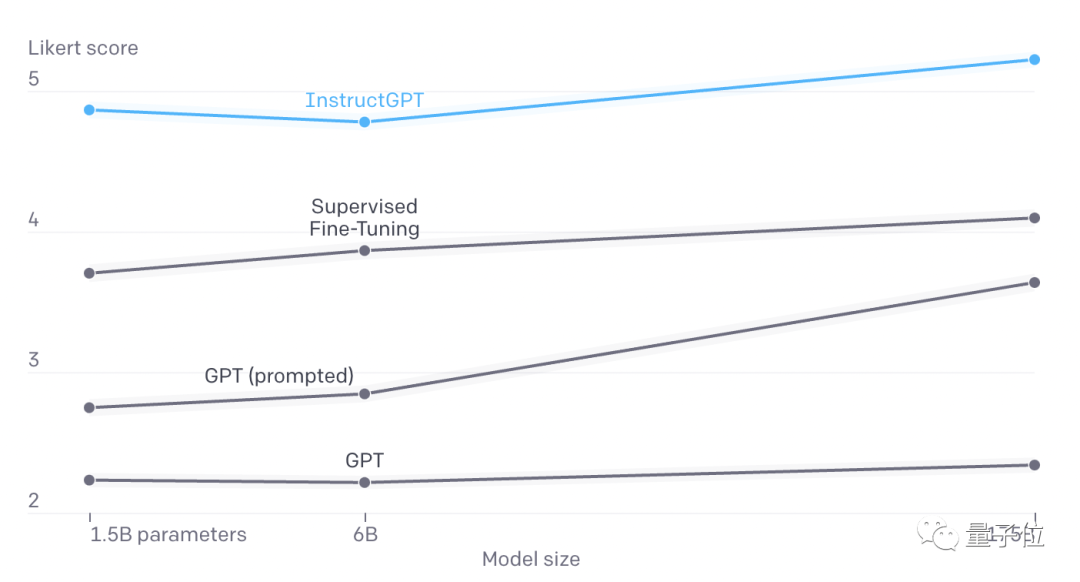
但OpenAI表示InstructGPT仍有许多要改进的地方,比如接受的都是英语的训练,因此偏向于英语文化价值观,给语句标注的人的偏好,也会影响GPT-3的“价值观”。
总之,纠正GPT-3的三观,还有很长的路要走。
参考链接:
[1]https://openai.com/blog/instruction-following/
[2]https://github.com/openai/following-instructions-human-feedback
[3]https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf
— 完 —
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



