这个赛车AI不再只图一时爽,学会了考虑长远策略
博雯 发自 凹非寺
量子位 | 公众号 QbitAI
玩赛车游戏的AI们现在已经不仅仅是图快图爽了。
他们开始考虑战术规划,甚至有了自己的行车风格和“偏科”项目。
比如这位只擅长转弯的“偏科”选手,面对急弯我重拳出击,惊险漂移,面对直线我唯唯诺诺,摇晃不停:

还有具备长远目光,学会了战术规划的AI,也就是这两位正在竞速的中的绿色赛车,看似在转弯处减缓了速度,却得以顺利通过急弯,免于直接GG的下场。

还有面对不管是多新的地图,都能举一反三,跑完全程的AI。
看起来就像是真的在赛车道上学会了思考一样。
(甚至上面所说的那位偏科选手还在不懈努力后成功逆袭了
这项训练结果一经公布,便吸引了大批网友的围观:
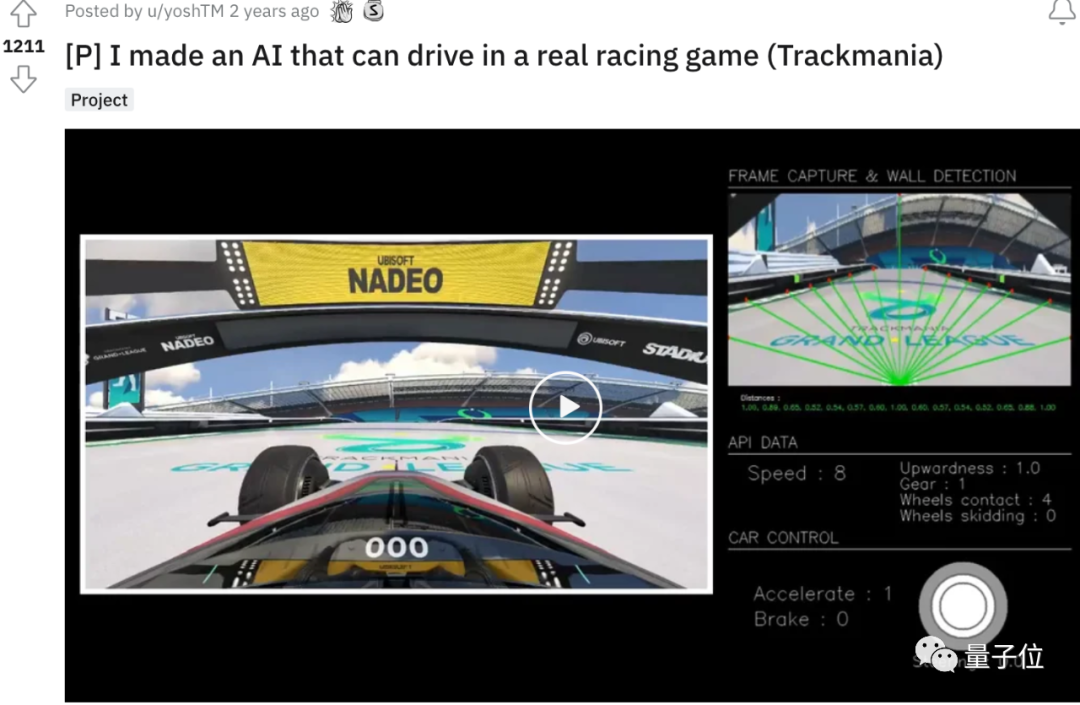
强化学习让AI学会“长远考虑”
训练赛道来自一款叫做《赛道狂飙》(Trackmania)的游戏,以可深度定制的赛道编辑器闻名于玩家群体。
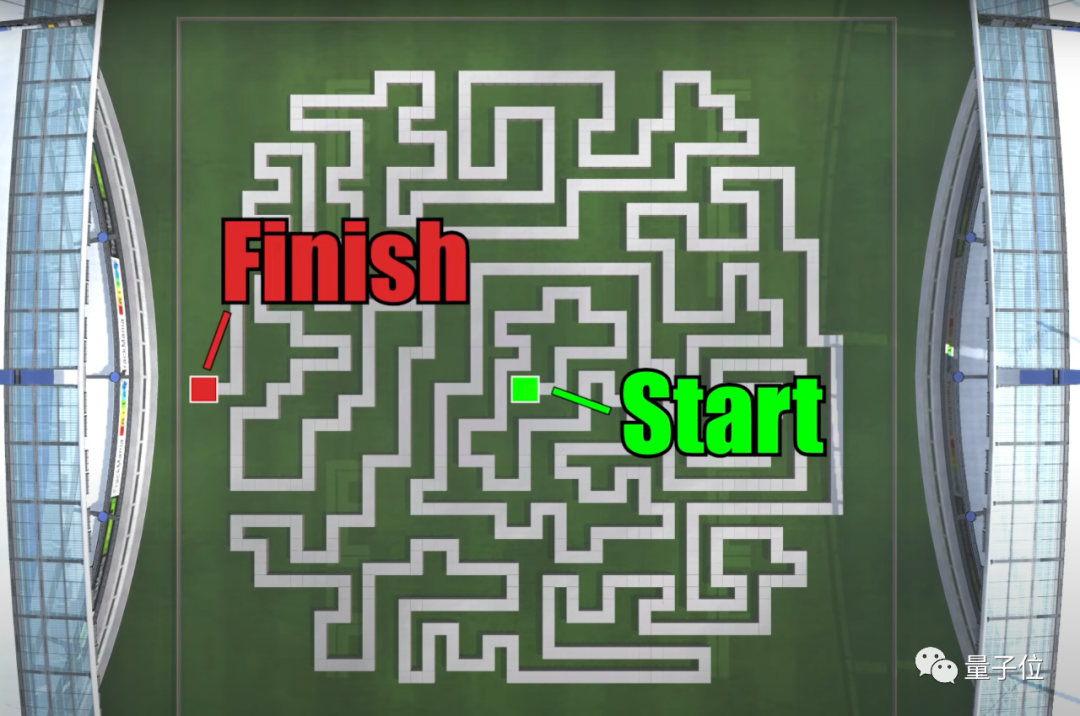
为了更大程度上激发赛车AI的潜力,开发者自制了这样一张九曲十八弯的魔鬼地图:
这位开发者名叫yoshtm,之间就已经用AI玩过这款游戏,一度引发热议:
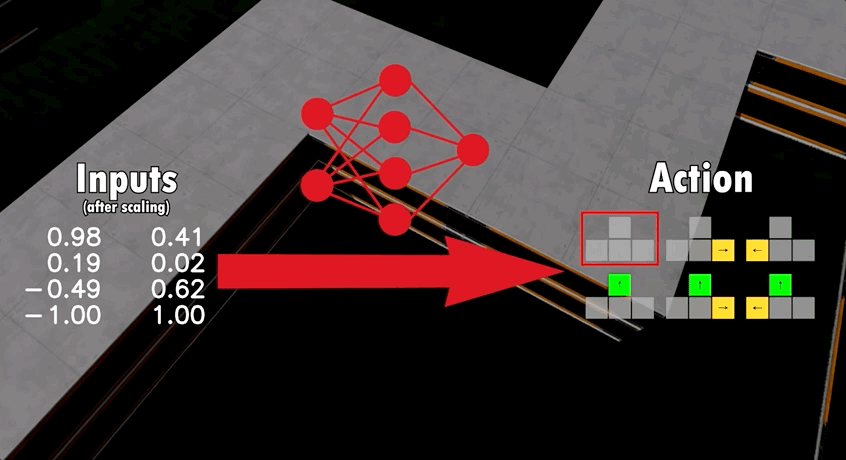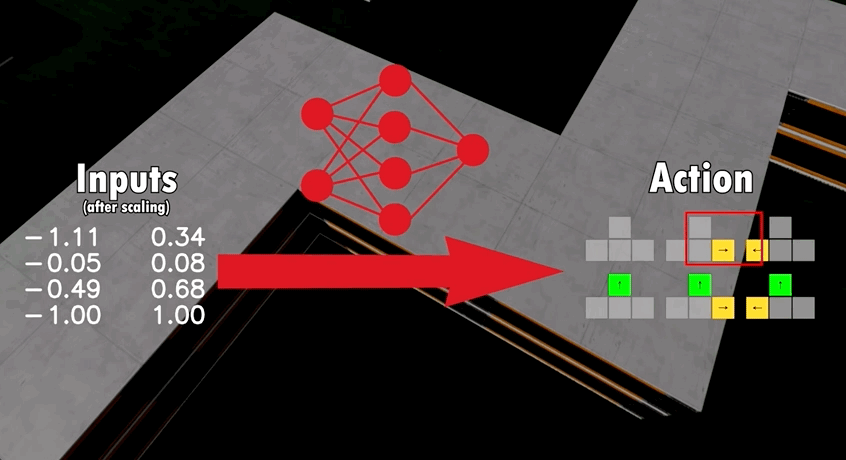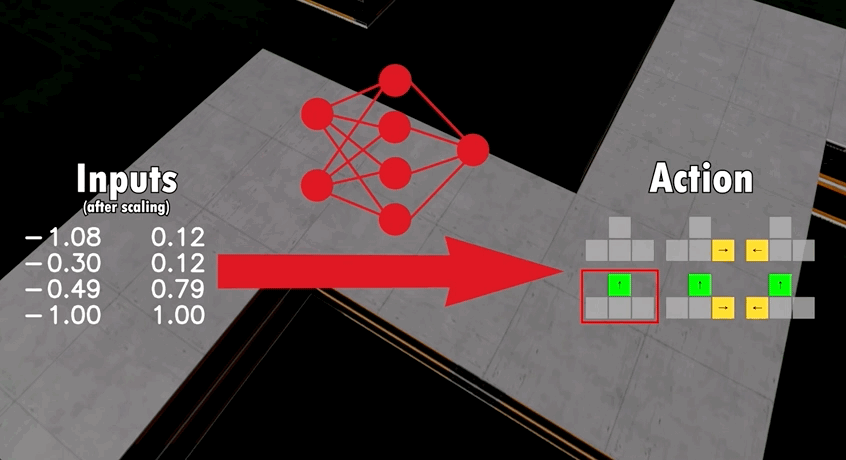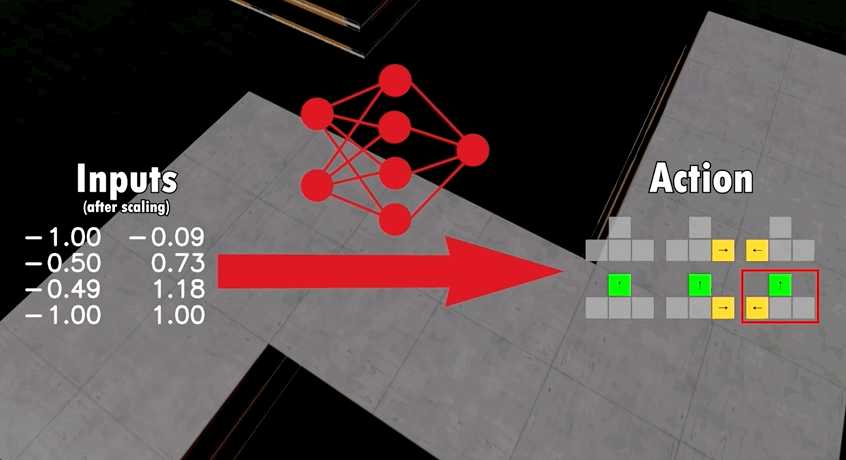
一开始,yoshtm采用的是一种监督学习模型,拥有2个隐藏层。
模型包含了16个输入,包括如汽车当前速度、加速度、路段位置等等,再通过神经网络对输入参数进行分析,最终输出6种动作中的一种:
基于这一模型架构,开发者让多只AI在同一张地图上竞争。
通过多次迭代,不同AI的神经网络会出现细微的差别,结果最好的AI将最终脱颖而出。
这种方法确实能让AI学会驾驶,不过也带来了一个问题:
AI常常只能以速度或最终冲线的时间等单一指标来评估自己,难以更进一步。
这次,时隔两年后的赛车AI,不仅学会了从长远出发制定策略(比如在急弯时对速度作出调整),还大幅提高了对新地图的适应性。
主要原因就来自于开发者这次引入的新方法,强化学习。
这种方法的核心概念是“奖励”,即通过选择带来更多奖励的行为,来不断优化最终效果。
在训练赛车游戏中的AI时,yoshtm定义的奖励很常规:速度越快奖励越多,走错路或掉下赛道就会惩罚。

但问题是,一些行动,比如在临近转弯时的加速或许能导致短期的正面奖励,但从长远来看却可能会产生负面的后果。
于是,yoshtm采用了一种叫做Deep Q Learning的方法。
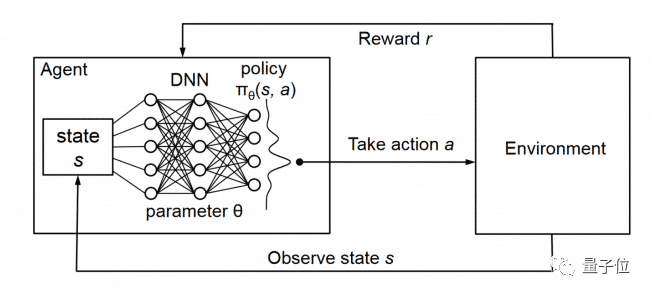
这是一种无模型的强化学习技术,对于给定状态,它能够比较可用操作的预期效用,同时还不需要环境模型。
Deep Q Learning会通过深度网络参数 的学习不断提高Q值预测的准确性,也就是说,能够使AI在赛车游戏中预测每个可能的行动的预期累积奖励,从而“具备一种长远的策略目光”。
随机出生点帮AI改正“偏科”
接下来开始进行正式训练。
yoshtm的思路是,AI会先通过随机探索来尽可能多地收集地图数据,他将这一行为称之为探索。
探索的比例越高,随机性也就越强,而随着比例降低,AI则会更加专注于赢取上述设置的奖励,也即专注于跑图。

不过,在训练了近3万次,探索比例降低到5%时,AI“卡关”了:

核心问题是AI出现了“偏科”。
由于前期经历了多个弯道的跑图,所以AI出现了过拟合现象,面对长直线跑道这种新的赛道类型,一度车身不稳,摇摇晃晃,最终甚至选择了“自杀”:
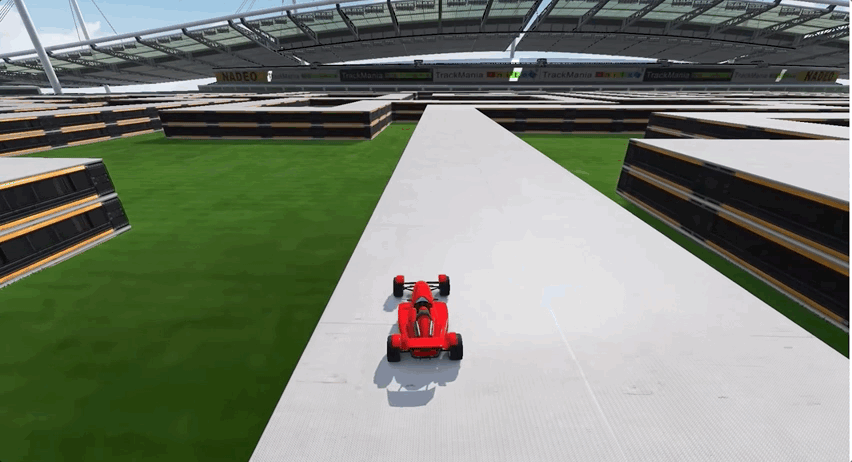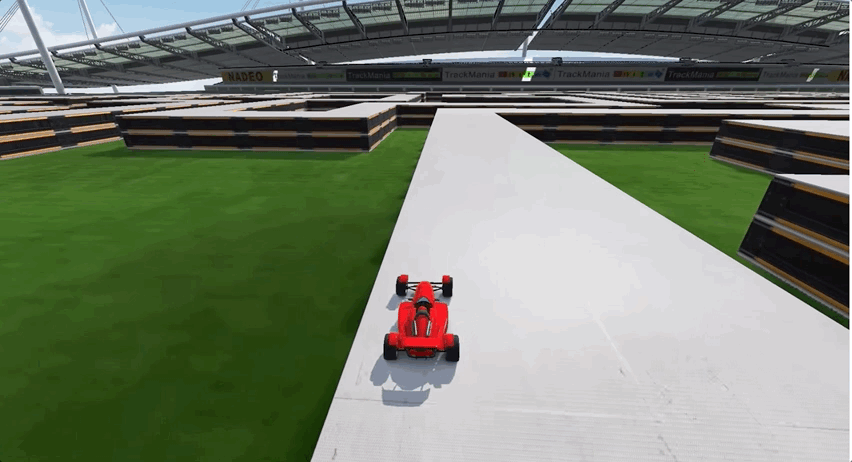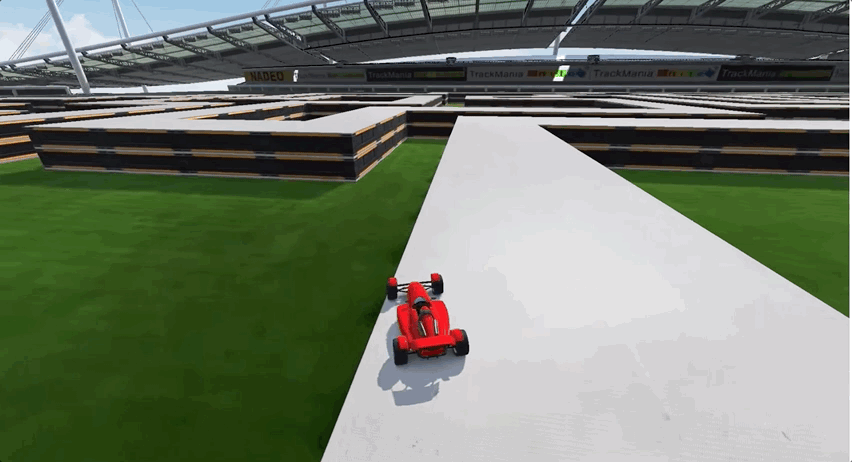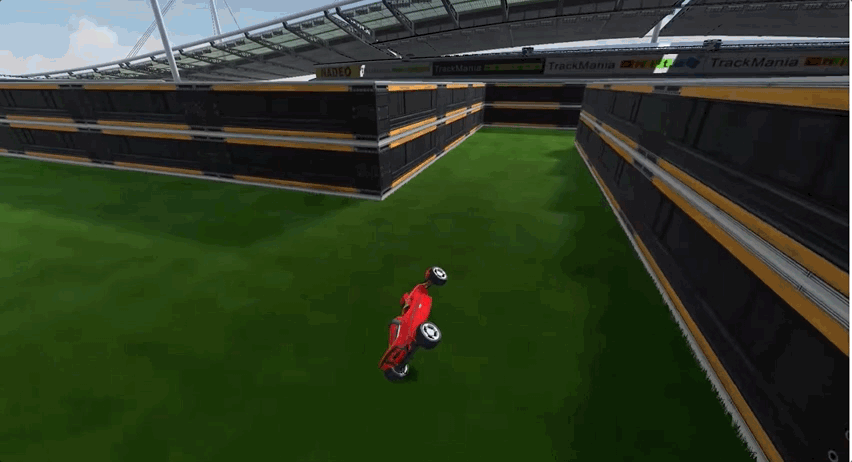
要如何解决这个问题呢?
yoshtm并没有选择重新制作地图,而是选择修改AI的出生点:
每次开始训练时,AI的出发点都将在地图上的一个随机位置生成,同时速度和方向也会随机。

这一办法立竿见影,AI终于开始能够完整跑完一条赛道了。
接下来就是进行不断训练,最终,开发者yoshtm和AI比了一场,AI在这次跑到了最好成绩:6分20秒。

虽然还是没有真人操控的赛车跑得快,不过AI表现出了较强的场地适应性,对草地还是泥地都能立马举一反三。
yoshtm最后这样说道:
《赛车狂飙》本来就是一个需要大量训练的游戏,AI当然也如此。
至少我现在很确定,这个AI可以打败大量的初学者。
参考链接:
[1]https://www.youtube.com/watch?v=SX08NT55YhA
[2]https://www.reddit.com/r/Games/comments/tcj32m/ai_learns_to_drive_from_scratch_in_trackmania/
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~





