【泡泡一分钟】基于语义分割的级联光流法三维重建(3dv-39)
每天一分钟,带你读遍机器人顶级会议文章
标题:Cascaded Scene Flow Prediction using Semantic Segmentation
作者:Zhile Ren ;Deqing Sun ;Jan Kautz
来源:3dv 2017 ( International Conference on 3D Vision)
播音员:水蘸墨
编译:刘田
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

光流法进行三维重建的一般思路为:给定一对立体相机的两个连续帧,同时估计所观察到的场景的三维几何和运动。许多现有的方法采用将图片将观察到的像素进行亚像素并,对其正则化,但是这种发放预测的位姿在刚性运动物体的形状和运动会产生不一致的结果。
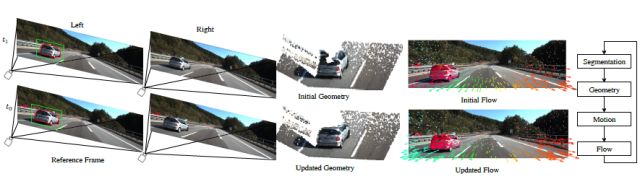
本文中设计一种假设场景由前景对象在静态背景前面严格移动,并使用语义线索生成像素精确的场景流估计。

文中设计了一种级联分类框架通过迭代细化语义分割掩模、立体对应、三维刚体运动估计和光流场精确地模拟三维场景。

最终在KITTI数据集上进行了测试,结果显示本文提出的方法进行场景重建的效果是现有方法中最为精确的。
如果想对SLAM光流法进行更加深入的学习,请参考以下文章:
【1】:http://blog.csdn.net/u014568921/article/details/46638557
【2】:视觉SLAM十四讲-第八讲
【3】:https://www.cnblogs.com/gnuhpc/archive/2012/12/04/2802124.html
Abstract
Given two consecutive frames from a pair of stereo cameras, 3D scene flow methods simultaneously estimate the 3D geometry and motion of the observed scene. Many existing approaches use superpixels for regularization, but may predict inconsistent shapes and motions inside rigidly moving objects. We instead assume that scenes consist of foreground objects rigidly moving in front of a static background, and use semantic cues to produce pixel-accuratescene flow estimates. Our cascaded classification framework accurately models 3D scenes by iteratively refining semantic segmentation masks, stereo correspondences, 3D rigid motion estimates, and optical flow fields. We evaluateour method on the challenging KITTI autonomous driving benchmark, and show that accounting for the motion of segmented vehicles leads to state-of-the-art performance.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
在【泡泡机器人SLAM】公众号(paopaorobot_slam)中回复关键字“3dv-39”,即可获取本文下载链接。


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




