本文来自百度研究院被亚洲计算机视觉会议 ACCV 2020 接收的一篇论文《Speech2Video Synthesis with 3D Skeleton Regularization and Expressive Body Poses》。
Speech2Video 是一种从语音音频输入合成人体全身运动(包括头、口、臂等)视频的任务,其产生的视频应该在视觉上是自然的,并且与给定的语音一致。传统的 Speech2Video 方法一般会使用专用设备和专业操作员进行性能捕获,且大多数语音和渲染任务是由动画师完成的,定制使用的成本通常比较昂贵。
近年来,随着深度神经网络的成功应用,数据驱动的方法已经成为现实。例如,SythesisObama 或 MouthEditing 通过使用 RNN 通过语音驱动嘴部运动来合成说话的嘴部。泰勒 [3] 提出使用音频来驱动高保真图形模型,该模型不仅可以将嘴部动画化,而且还可以对面部的其他部分进行动画处理以获得更丰富的语音表达。
然而,嘴部运动的合成大部分是确定性的:给定发音,在不同的人和环境中嘴部的运动或形状是相似的。但现实生活中,相同情况下的全身手势运动具有更高的生成力和更多的变异性,这些手势高度依赖于当前的上下文和正在执行语音的人类。传递重要信息时,个性化的手势会在特定时刻出现。因此,有用的信息仅稀疏地存在于视频中,这为简单的端到端学习算法 [1、3] 从有限的录制视频中捕获这种多样性带来了困难。
近日,百度提出了一种新的方法,将给定文字或音频转换为具有同步、逼真、富表现力的肢体语言的实感视频。该方法首先使用递归神经网络(recursive neural network,RNN)从音频序列生成 3D 骨骼运动,然后通过条件生成对抗网络(GAN)合成输出视频。
![]()
论文地址:https://arxiv.org/pdf/2007.09198.pdf
为了使骨骼运动逼真并富有表现力,研究者将关节 3D 人体骨骼的知识和学习过的个性化语音手势字典嵌入到学习和测试过程中。前者可以防止产生不合理的身体变形,而后者通过一些有意义的身体运动视频帮助模型快速学习。为了制作富有运动细节的逼真高分辨率视频,研究者提出一种有条件的 GAN,其中每个细节部分,例如头和手,是自动放大过的以拥有自己的判别器。该方法与以前处理类似任务的 SOTA 方法相比效果更好。
![]()
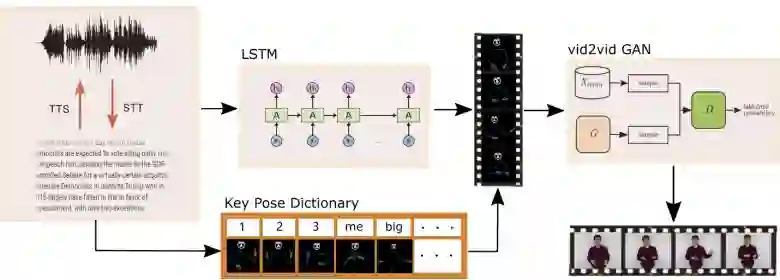
图 1:Speech2Video 系统 pipeline
如图 1 所示,根据用于训练 LSTM 网络的内容,系统的输入是音频或文本。考虑到文本到语音(TTS)和语音到文本(STT)技术都已经成熟并且可商用,此处假定音频和 text 是可互换的。即使从最先进的 STT 引擎中得到一些错误识别的单词 / 字符,系统也可以容忍这些错误,LSTM 网络的主要目的是将文本 / 音频映射到身体形状。错误的 STT 输出通常是与真实发音相似的单词,这意味着它们的拼写也很可能是相似的。因此,它们最终将映射的身体形状或多或少相似。
LSTM 的输出是由 SMPL-X 参数化的一系列人体姿势 [9]。SMPL-X 是一个人体、面部和手部的 3D 联合模型,这一动态关节 3D 模型是由一个 2D 彩色骨架图像序列可视化的。这些 2D 图像被进一步输入到 vid2vid 生成网络[17] 中,以生成最终的现实人物图像。
在成功同步语音和动作的同时,LSTM 大部分时间只能学习重复的人类动作,这会使视频看起来很无聊。为了使人体动作更具表现力和变化性,研究者在一些关键词出现时将特定姿势加入 LSTM 的输出动作中,例如,巨大、微小、高、低等。研究者建立了一个字典,将这些关键词映射到它们相应的姿势。
![]()
![]()
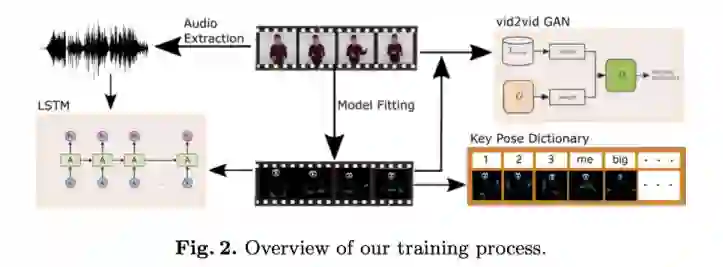
图 3 显示了数据采集环境。模特站在相机和屏幕的前面,当他 / 她在屏幕上阅读脚本时,研究者会捕获这些视频。最后再要求模特摆一些关键词的动作,例如巨大、微小、向上、向下、我、你等等。
研究者首先将这些 2D 关键点作为人体模型的表示,并训练了 LSTM 网络,但结果不能令人满意(如图 4 所示)。
![]()
最后采用了 SMPL-X,这是一种关节式 3D 人体模型。SMPL-X 使用运动学骨架模型对人体动力学进行建模,具有 54 个关节,包括脖子、手指、手臂、腿和脚。
![]()
如图 5 所示,研究者从录制的视频中手动选择关键姿势,并建立一个单词 - 姿势查询字典。同样,该姿势表示为 106 个 SMPL-X 参数。关键姿势可以是静止的单帧姿势或多帧运动,可以通过相同的方法将两者插入到现有的人体骨骼视频中。
研究者采用 vid2vid 提出的生成网络,将骨架图像转换为真实的人像。
![]()
图 7:用于训练 vid2vid 的示例图像对。双手均带有特殊的色环标记。
运行时间和硬件方面,系统中最耗时和最耗内存的阶段是训练 vid2vid 网络。在 8 个 NVIDIA Tesla M40 24G GPU 集群上完成 20 个时期的训练大约需要一周;测试阶段要快得多,在单个 GPU 上生成一帧仅需约 0.5 秒。
如表 1 所示,研究者将使用用户研究的结果与 4 种 SOTA 方法进行比较,结果显示,本文方法获得了最佳的总体质量得分。
![]()
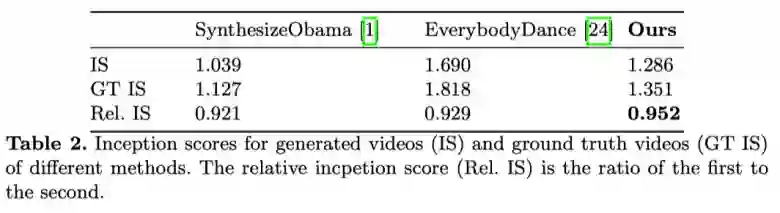
此外,研究者使用 Inception 分数评估图像生成结果,包括两个方面:图像质量和图像多样性。
![]()
为了评估最终输出的视频,研究者在 Amazon Mechanical Turk(AMT)上进行了人类主观测试,共有 112 名参与者。研究者向参与者展示了总共五个视频,其中四个是合成视频,两个由真实人的音频生成,两个由 TTS 音频生成;剩下的是一个真实人物的短片。参与者以李克特量表(从 1(强烈不同意)到 5(强烈同意))对这些视频的质量进行评分。其中包括:1)人体的完整性(没有遗漏的身体部位或手指);2)视频中人脸清晰;3)视频中的人体动作(手臂,手,身体手势)看起来自然流畅。4)身体的动作和手势与声音同步;5)视频的整体视觉质量。
Speech2Video 是一种新颖的框架,可以使用 3D 驱动的方法生成逼真的语音视频,同时避免构建 3D 网格模型。作者在框架内建立了个性化关键手势表,以处理数据稀疏性和多样性的问题。更重要的是,作者利用 3D 骨骼约束来生成身体动力学,从而保证其姿势在物理上是合理的。
1. Suwajanakorn, S., Seitz, S.M., Kemelmacher-Shlizerman, I.: Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics (TOG) 36 (2017) 95
2. Fried, O., Tewari, A., Zollh¨ofer, M., Finkelstein, A., Shechtman, E., Goldman, D.B., Genova, K., Jin, Z., Theobalt, C., Agrawala, M.: Text-based editing of talking-head video. arXiv preprint arXiv:1906.01524 (2019)
3. Taylor, S., Kim, T., Yue, Y., Mahler, M., Krahe, J., Rodriguez, A.G., Hodgins, J., Matthews, I.: A deep learning approach for generalized speech animation. ACM Transactions on Graphics (TOG) 36 (2017) 93
4. Kim, B.H., Ganapathi, V.: Lumi \ erenet: Lecture video synthesis from audio. arXiv preprint arXiv:1907.02253 (2019)
5. Pavllo, D., Feichtenhofer, C., Grangier, D., Auli, M.: 3d human pose estimation in video with temporal convolutions and semi-supervised training. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2019) 77537762
6. Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields. In: arXiv preprint arXiv:1812.08008. (2018)
7. Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single image. In: Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). (2019)
8. Wang, T.C., Liu, M.Y., Zhu, J.Y., Liu, G., Tao, A., Kautz, J., Catanzaro, B.:Video-to-video synthesis. In: Advances in Neural Information Processing Systems (NeurIPS). (2018)
9. Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. ACM Transactions on Graphics (ToG) 36 (2017) 245
Amazon SageMaker 1000元大礼包
ML训练成本降90%,被全球上万家公司使用,Amazon SageMaker是全托管机器学习平台,支持绝大多数机器学习框架与算法,并且用 IDE 写代码、可视化、Debug一气呵成。
现在,我们准备了
1000元
的免费额度,开发者可以亲自上手体验,让开发高质量模型变得更加轻松。
点击阅读原文,填写表单后我们将与你联系,为你完成礼包充值。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com