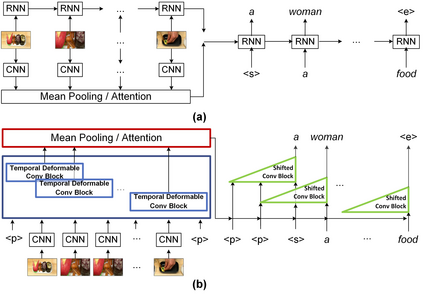
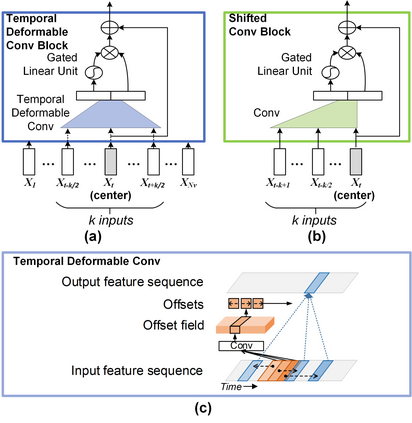
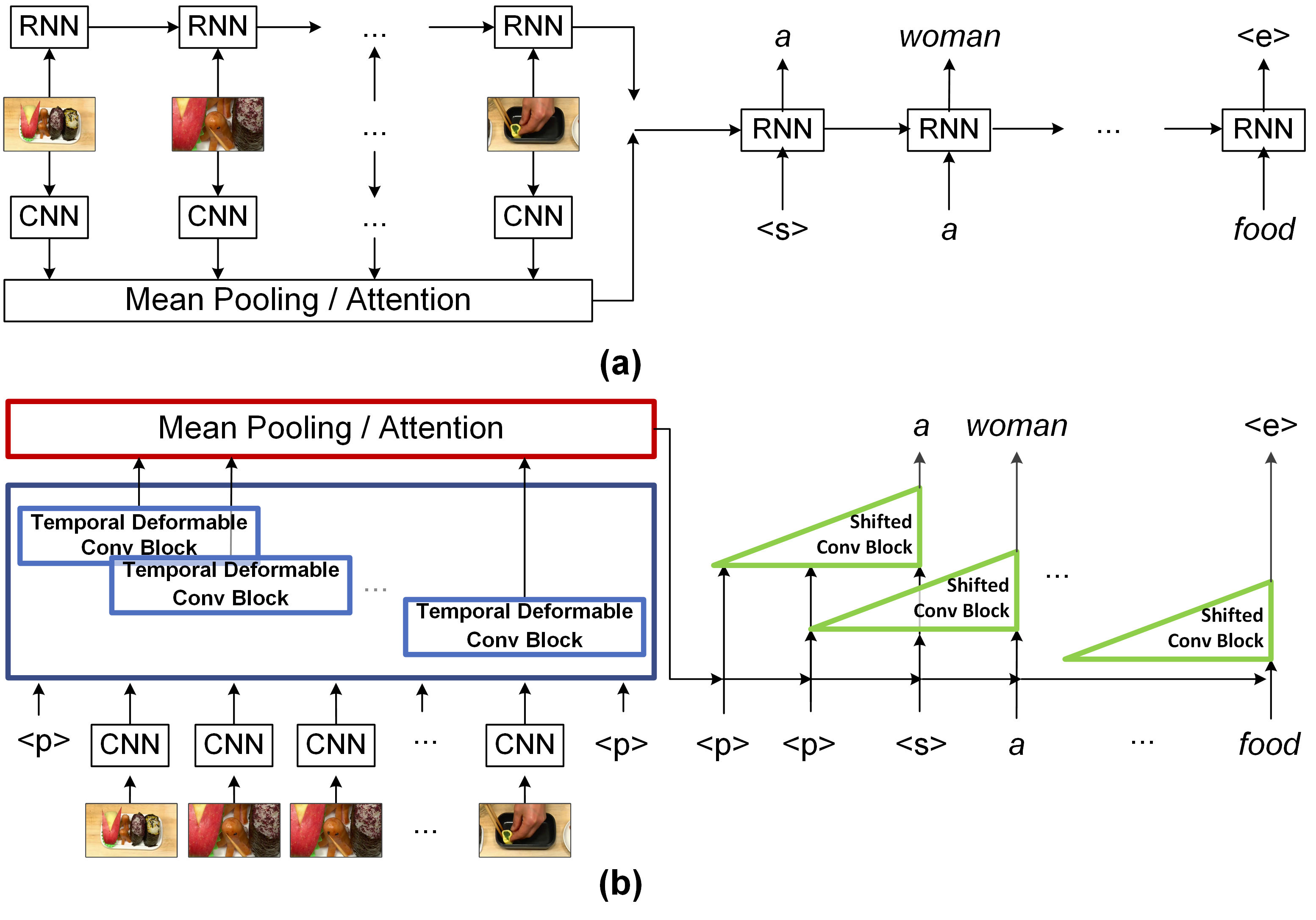
It is well believed that video captioning is a fundamental but challenging task in both computer vision and artificial intelligence fields. The prevalent approach is to map an input video to a variable-length output sentence in a sequence to sequence manner via Recurrent Neural Network (RNN). Nevertheless, the training of RNN still suffers to some degree from vanishing/exploding gradient problem, making the optimization difficult. Moreover, the inherently recurrent dependency in RNN prevents parallelization within a sequence during training and therefore limits the computations. In this paper, we present a novel design --- Temporal Deformable Convolutional Encoder-Decoder Networks (dubbed as TDConvED) that fully employ convolutions in both encoder and decoder networks for video captioning. Technically, we exploit convolutional block structures that compute intermediate states of a fixed number of inputs and stack several blocks to capture long-term relationships. The structure in encoder is further equipped with temporal deformable convolution to enable free-form deformation of temporal sampling. Our model also capitalizes on temporal attention mechanism for sentence generation. Extensive experiments are conducted on both MSVD and MSR-VTT video captioning datasets, and superior results are reported when comparing to conventional RNN-based encoder-decoder techniques. More remarkably, TDConvED increases CIDEr-D performance from 58.8% to 67.2% on MSVD.
翻译:人们普遍认为,视频字幕在计算机视野和人工智能领域是一项根本性但具有挑战性的任务,在计算机视觉和人工智能领域,视频字幕是一项根本性但具有挑战性的任务。流行的做法是通过常任神经网络(NNN),按顺序顺序绘制一个可变长输出句子的输入视频。然而,对RNN的培训仍然在某种程度上受到脱去/爆炸梯度问题的困扰,使优化变得困难。此外,RNN的内在经常性依赖性阻碍了在培训序列中的平行化,从而限制了计算。在本文中,我们提出了一个新型设计 -- -- 时变变变变变变变变变变变变变的Concoder-Decoder网络(以TDConvED为标签),在编码和解变变变变变变的网络中,充分利用了编码和变变变变的组合,在将MSVD的成绩和MSR的成绩上进行了广泛的实验,在将RVDVD的成绩上比了RVD的成绩。