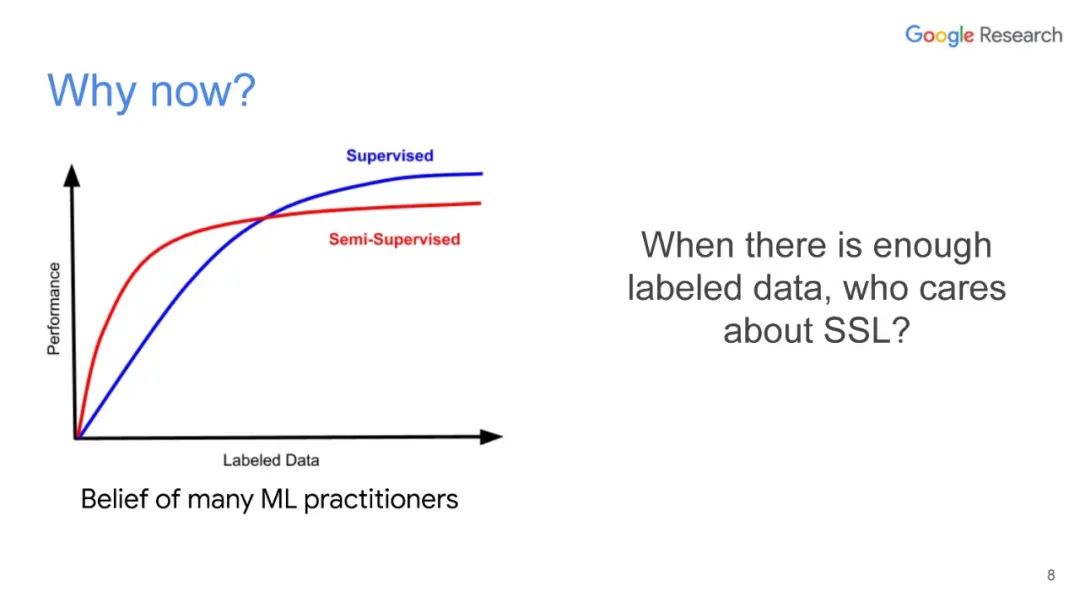
【Google AI-Luong】无标记数据学习, 83ppt, 一致性学习与自监督学习是什么?
【导读】如何利用未标记数据进行机器学习是当下研究的热点。最近自监督学习、对比学习等提出用于解决该问题。最近来自Google大脑团队的Luong博士介绍了无标记数据学习的进展,半监督学习以及他们最近重要的两个工作:无监督数据增强和自训练学习,是非常好的前沿材料。

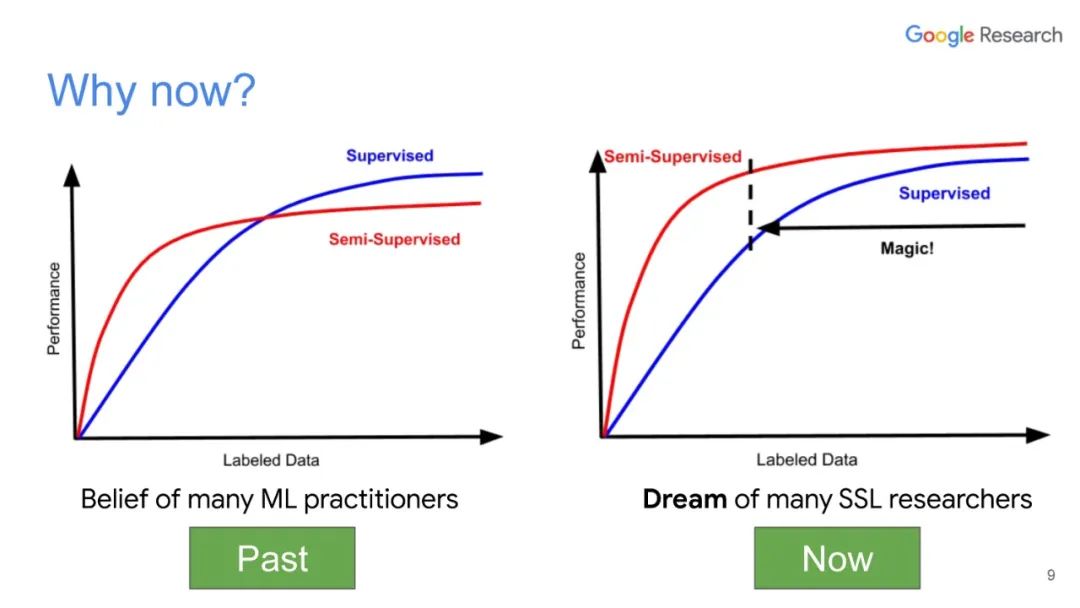
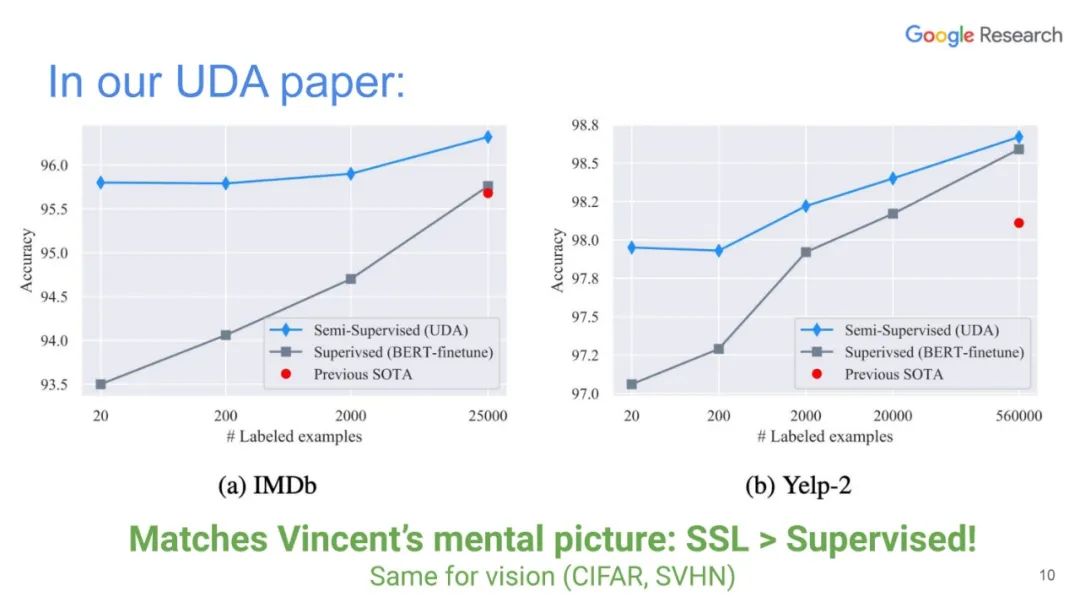
深度学习尽管取得了很大成功,但通常在小标签训练集中表现不佳。利用未标记数据改善深度学习一直是一个重要的研究方向,其中半监督学习是最有前途的方法之一。在本次演讲中,Luong博士将介绍无监督数据增强(UDA),这是我们最近的半监督学习技术,适用于语言和视觉任务。使用UDA,我们仅使用一个或两个数量级标记较少的数据即可获得最先进的性能。
在本次演讲中,Luong博士首先解释了基本的监督机器学习。在机器学习中,计算机视觉的基本功能是利用图像分类来识别和标记图像数据。监督学习需要输入和标签才能与输入相关联。通过这样做,您可以教AI识别图像是什么,无论是对象,人类,动物等。Luong博士继续进一步解释神经网络是什么,以及它们如何用于深度学习。这些网络旨在模仿人类大脑的功能,并允许AI自己学习和解决问题。
https://t.co/DBTQH2xHHL?amp=1

https://nlp.stanford.edu/~lmthang/
Google Brain高级科学家, learning /w unlabeled data (NoisyStudent, ELECTRA). PhD @StanfordNLP
文章地址:
https://arxiv.org/pdf/1904.12848v2.pdf
代码地址
https://github.com/google-research/ud
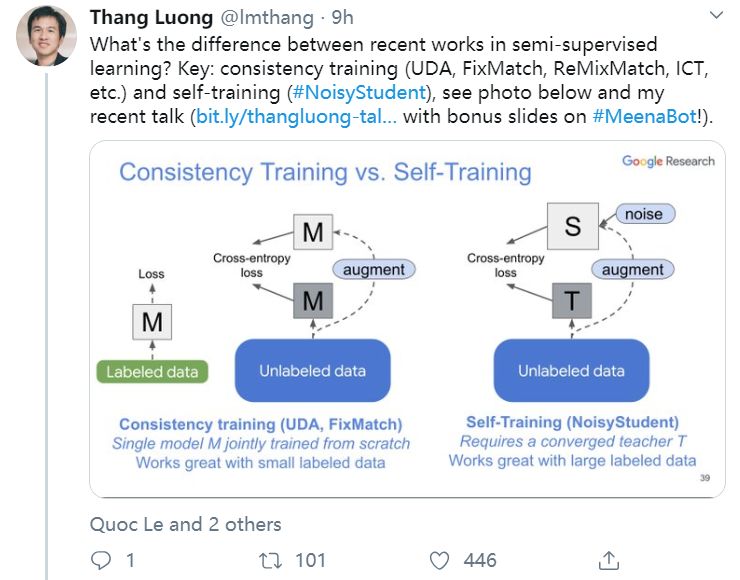
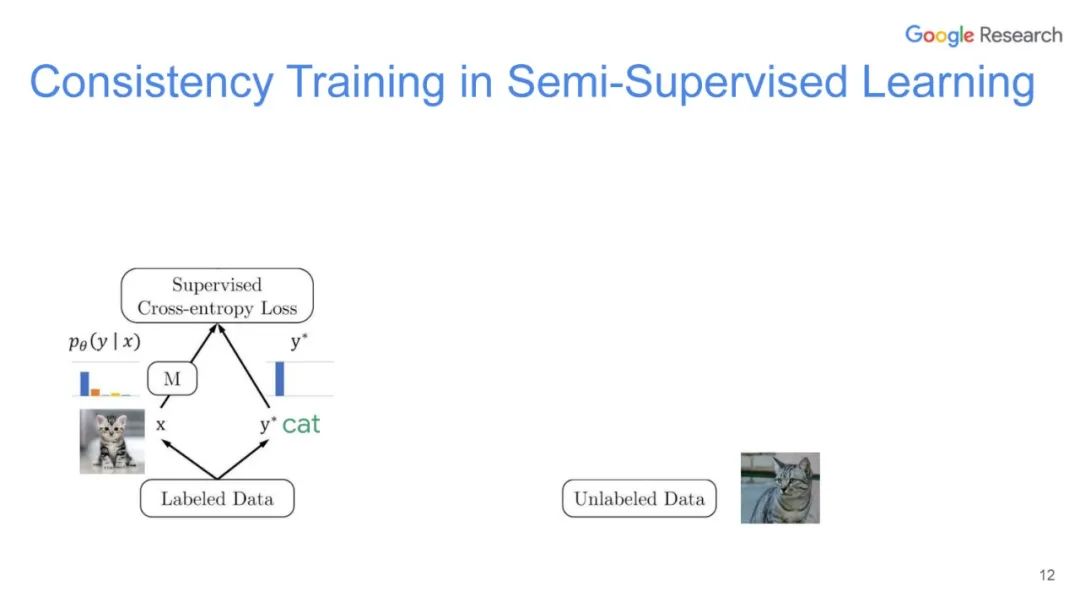
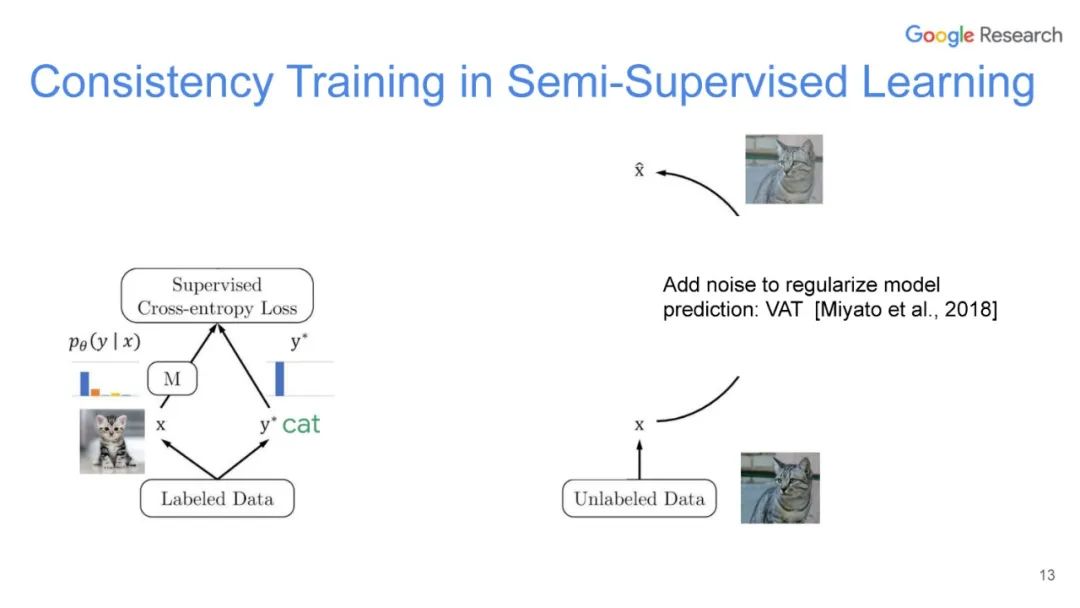
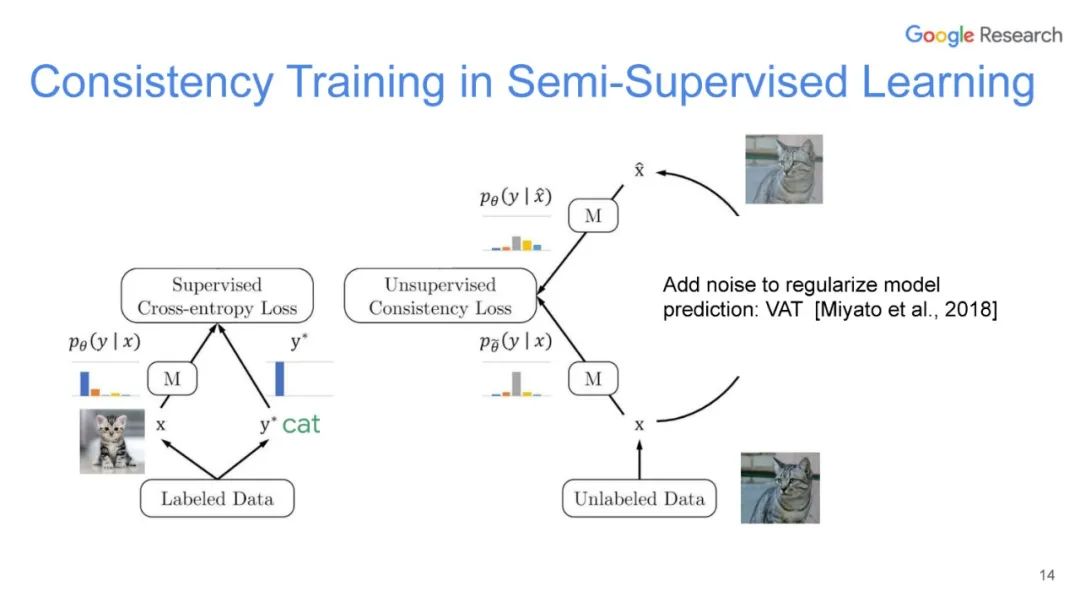
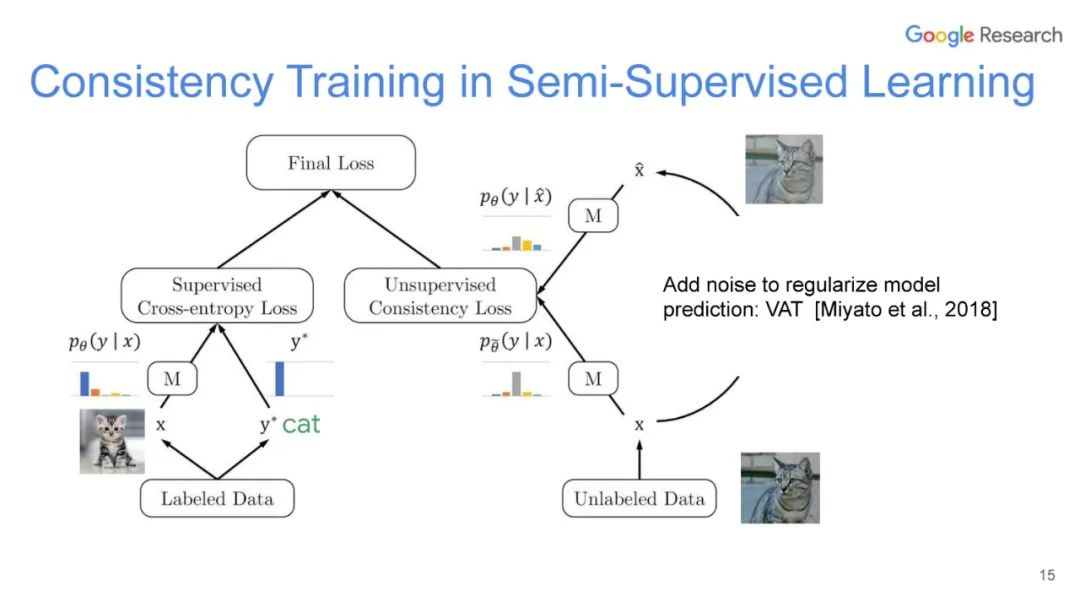
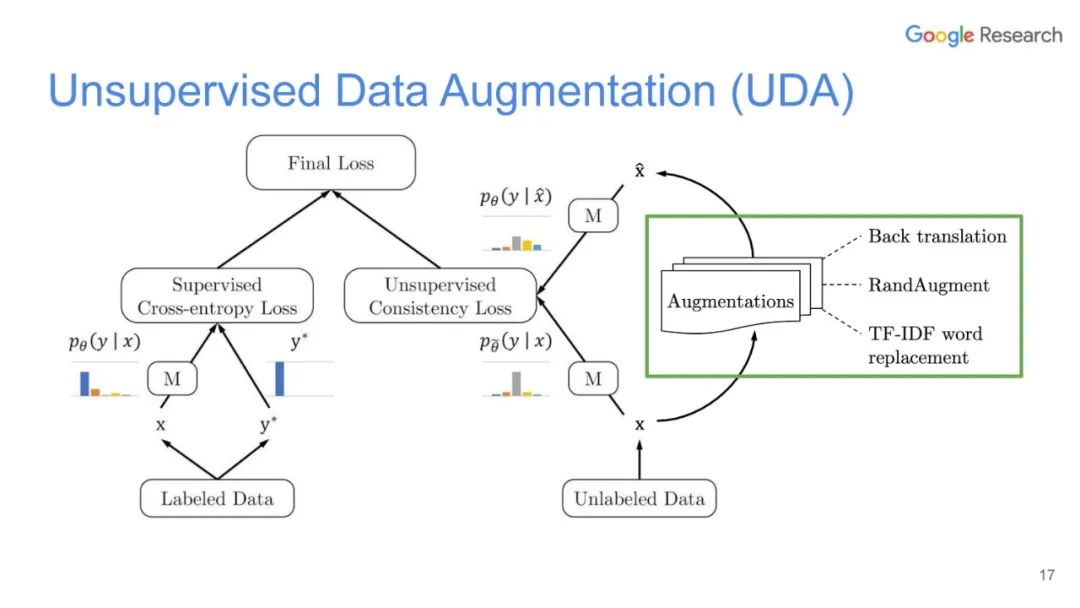
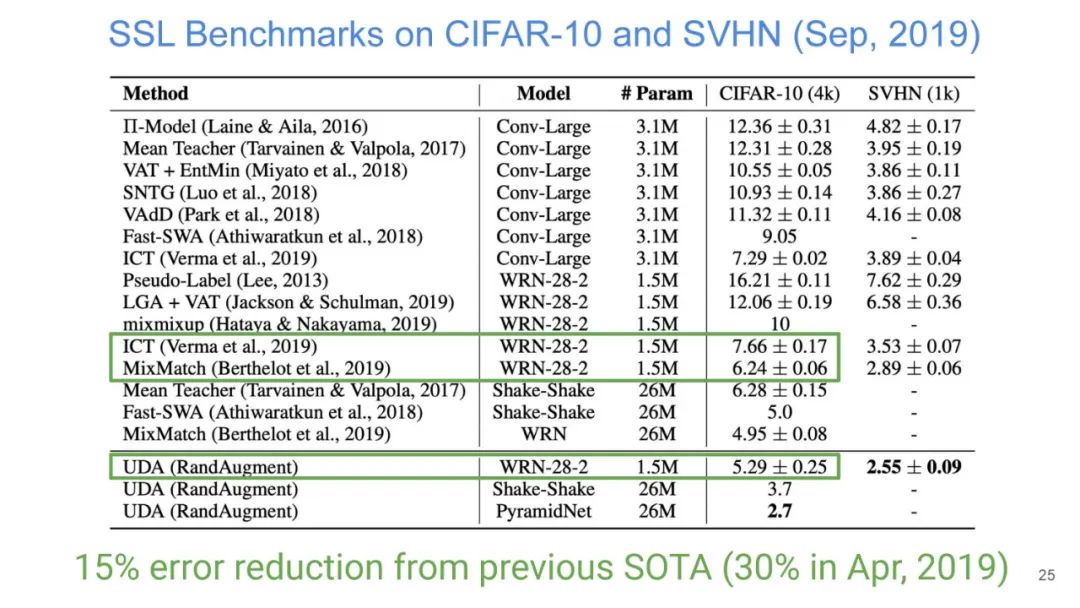
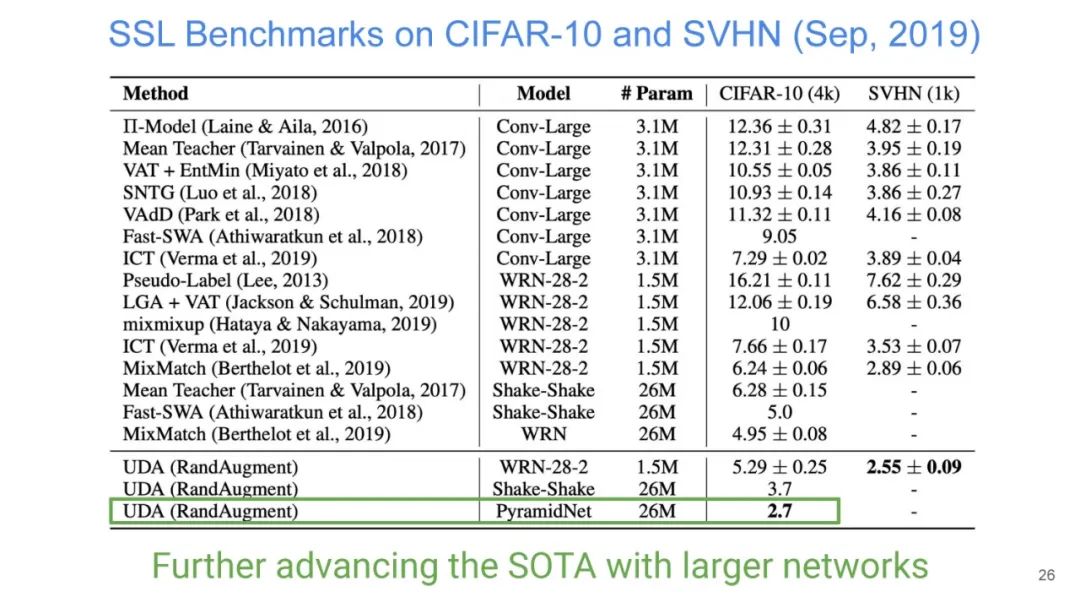
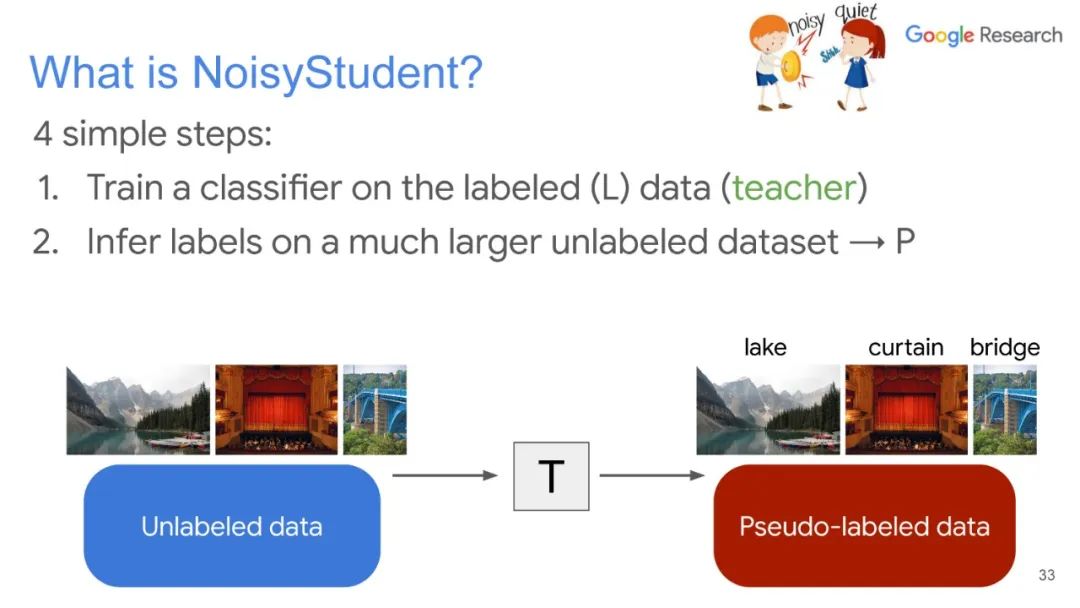
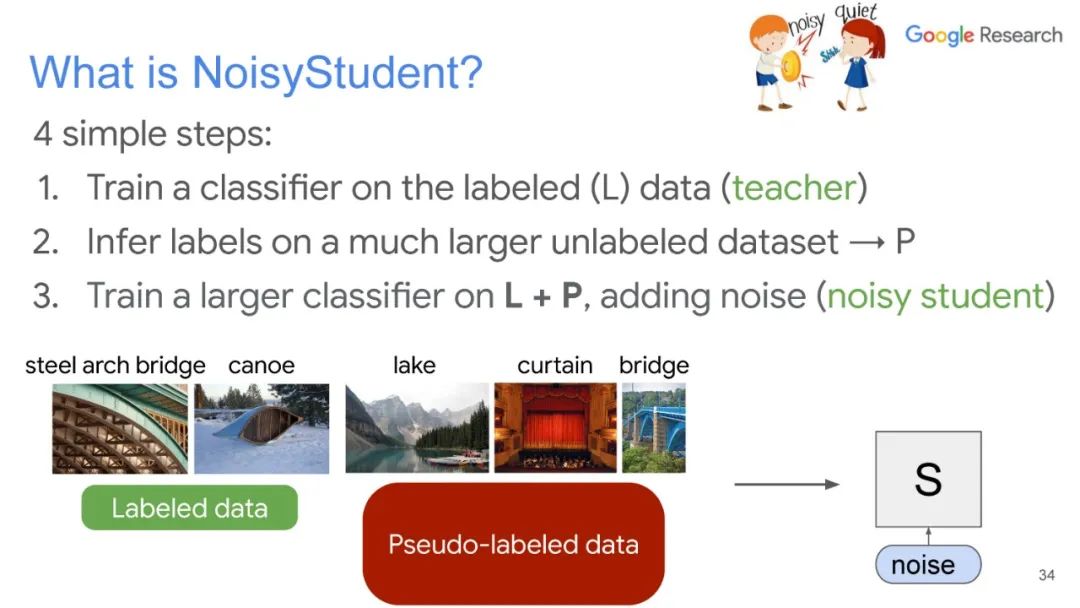
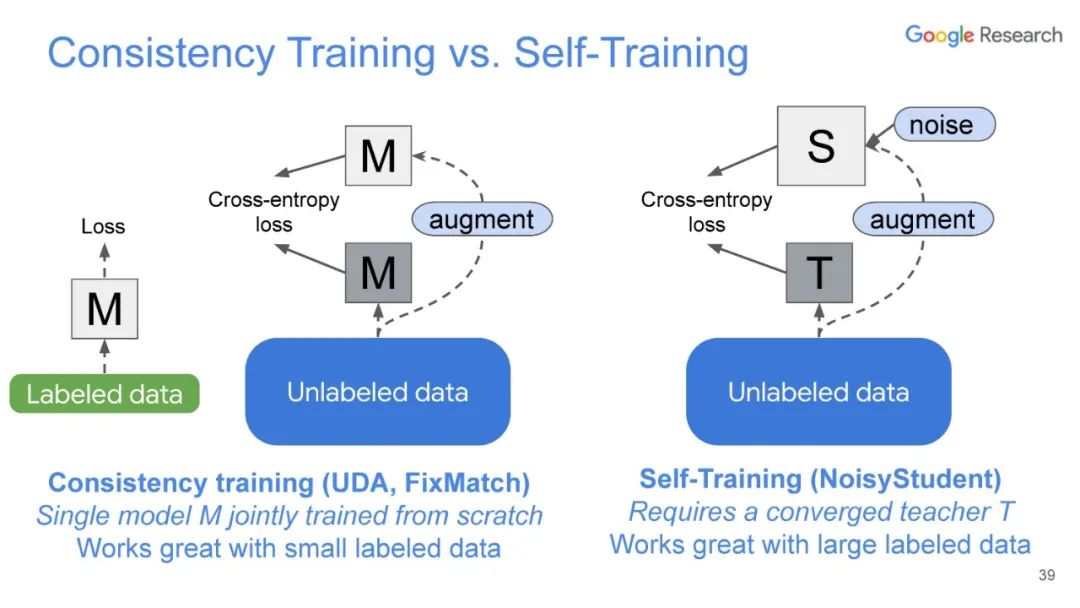
UDA方法主要利用了上述半监督方法中的第一种,即自洽正则化。其训练框架图如图所示。
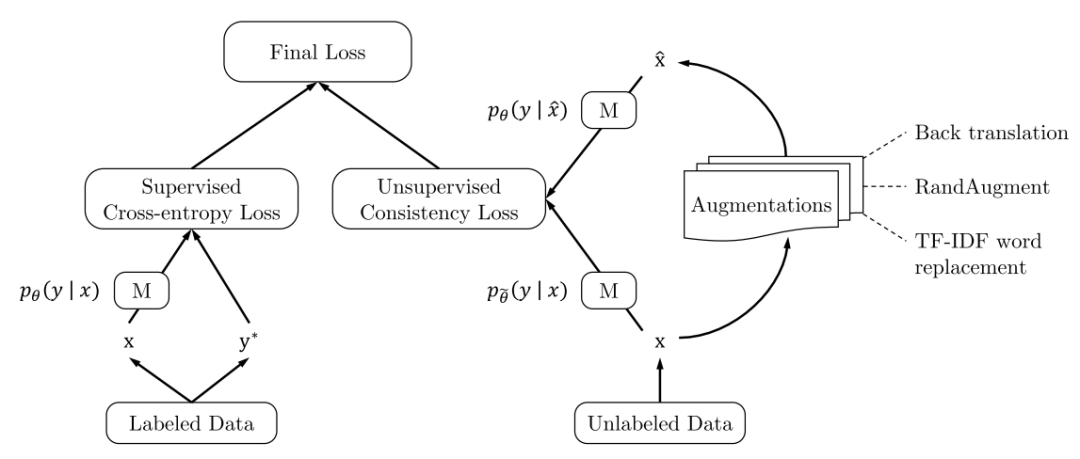
该方法思路也比较简单:对于带标签数据,直接计算分类损失;对不带标签的增广后的数据,计算模型当前对其的预测值与原始数据的预测的KL散度损失,最终两种损失按一定比例相加得到最终损失。
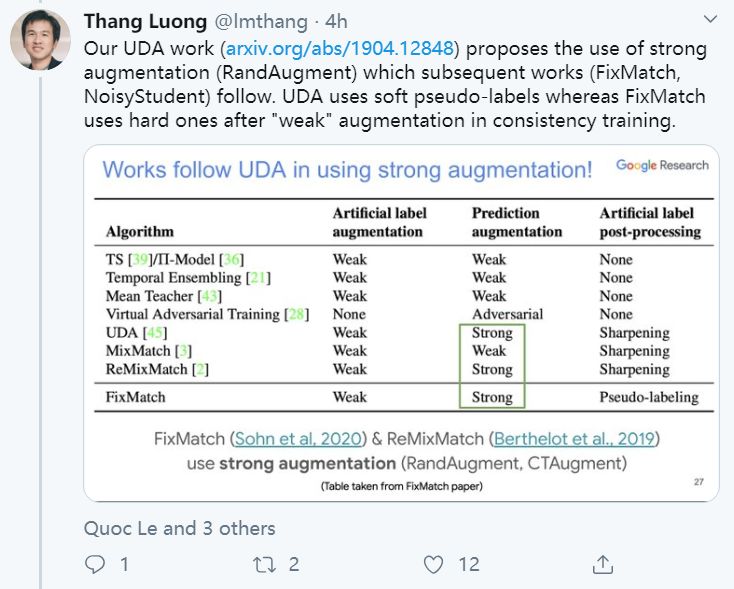
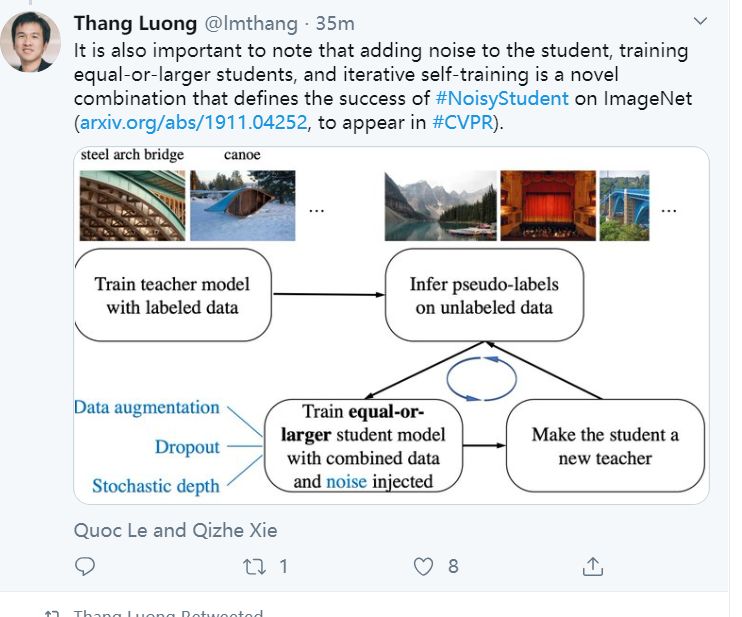
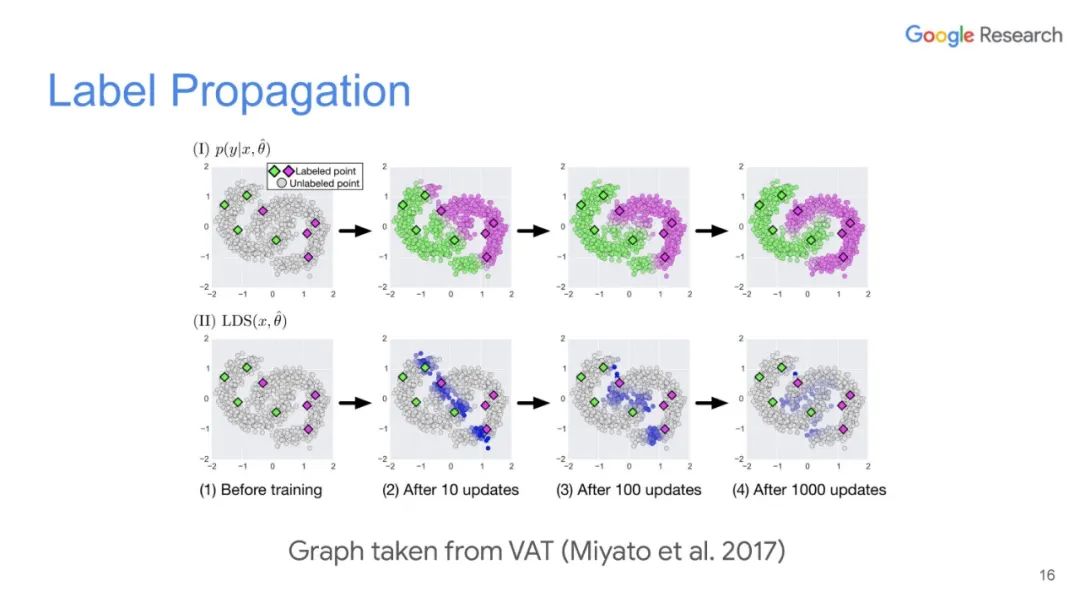
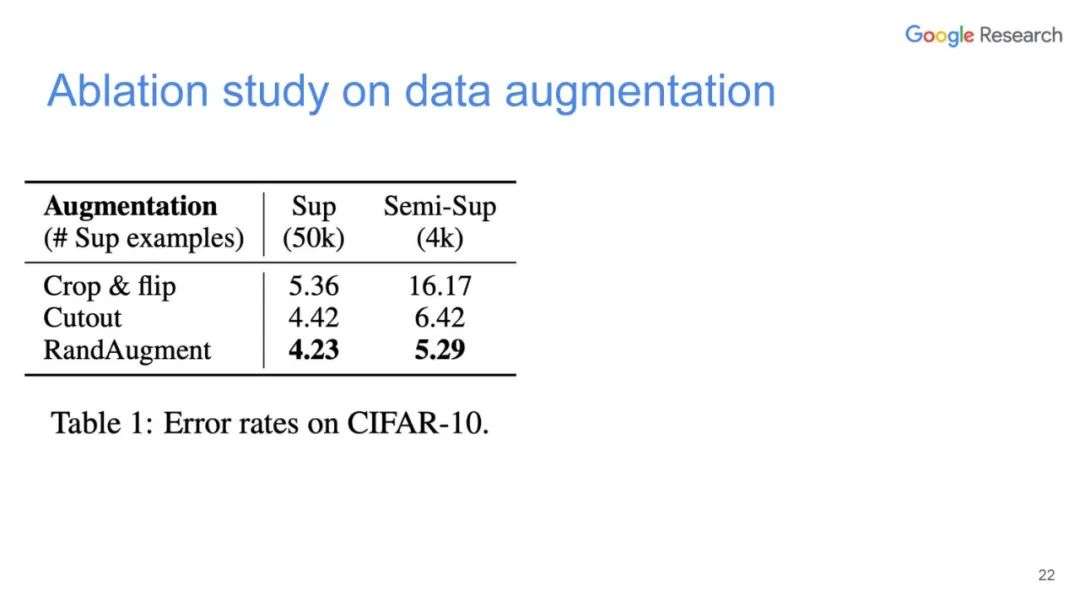
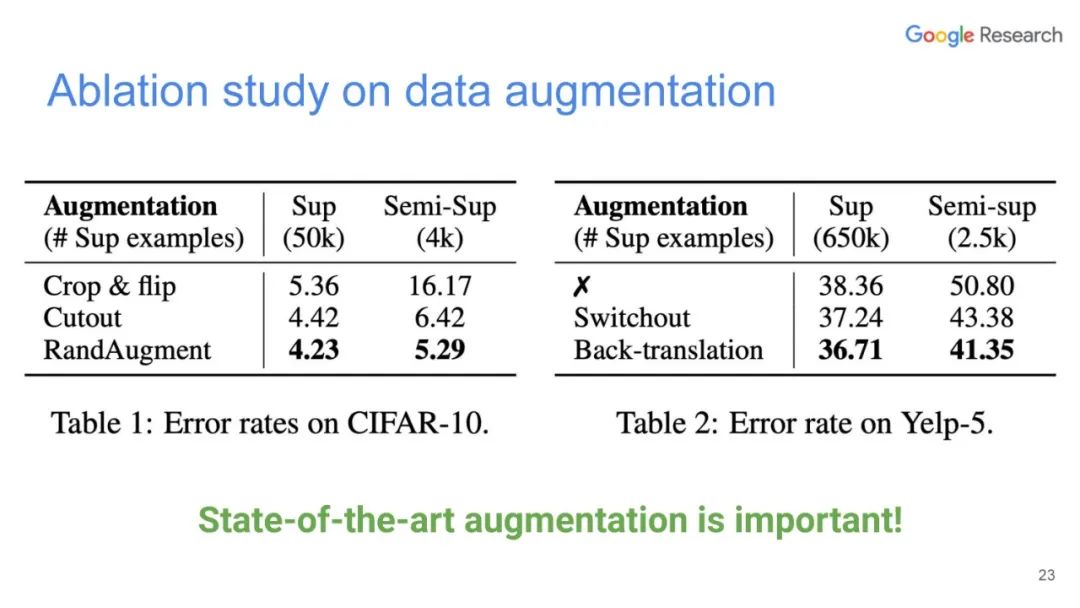
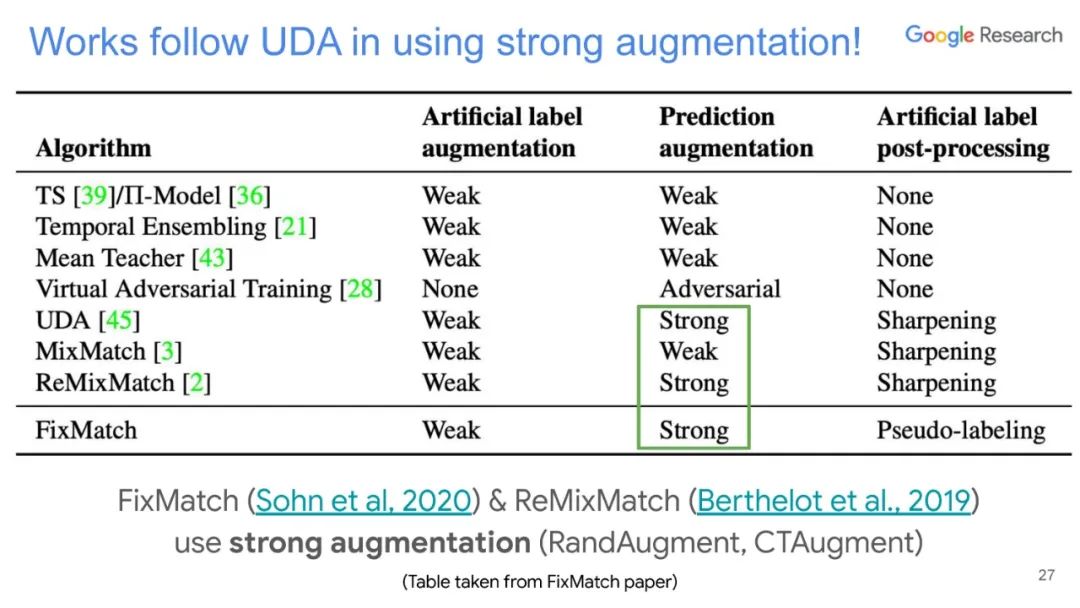
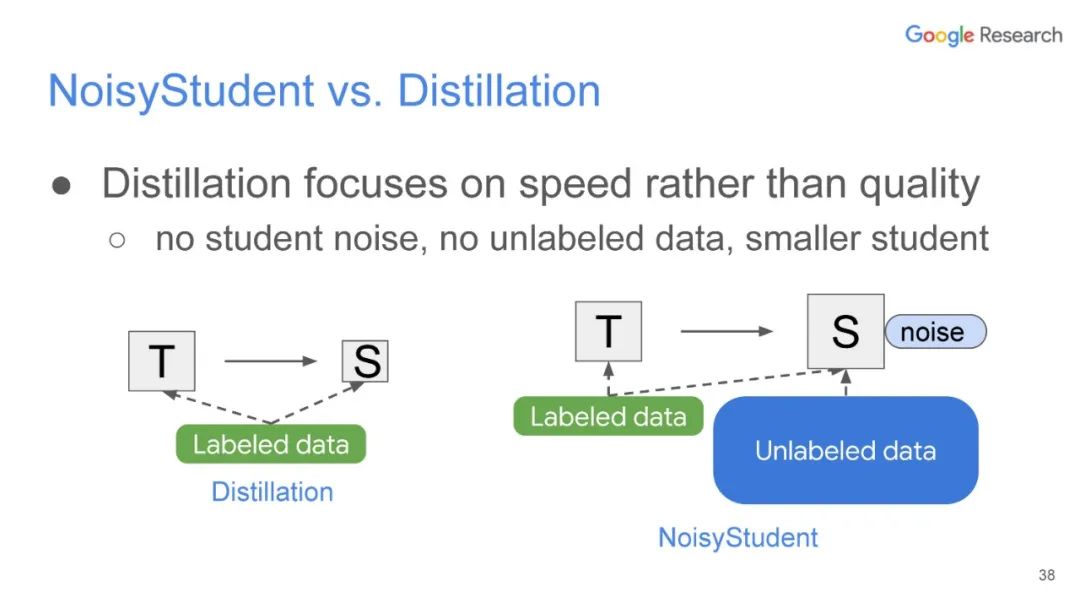
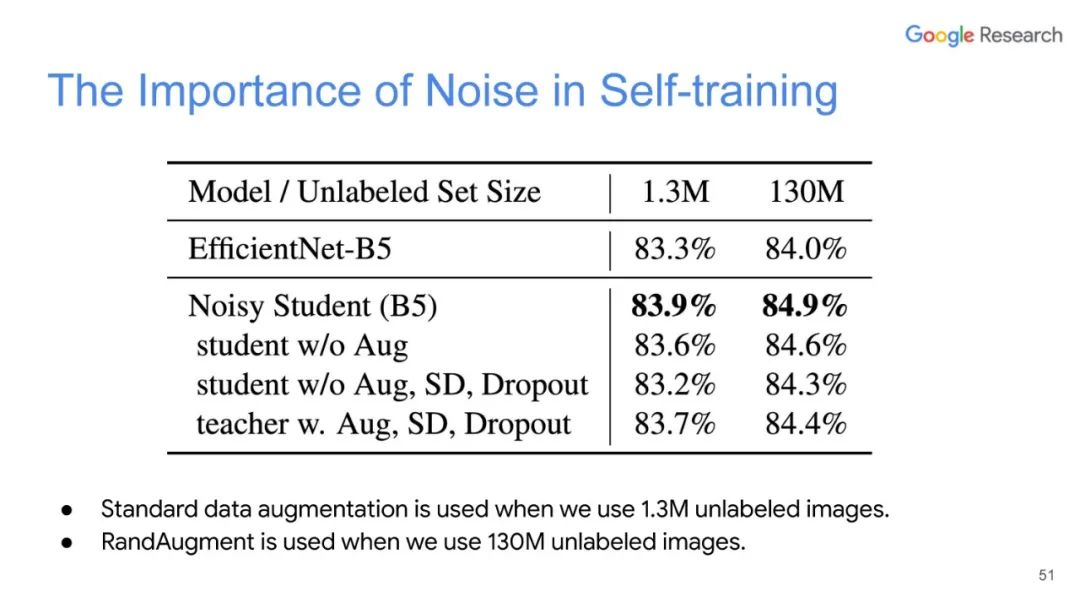
本篇文章探索了多种增广数据的方法,除了图像领域的旋转、扭曲方法等,也包括NLP领域的反向翻译(Back-translation)和TF-IDF词替换,对比它们对于半监督学习效果的影响,证明了有针对性的数据增强效果明显优于无针对性的数据增强。同时,本文章还提出了一种训练技巧——TSA“数据退火算法”,用于解决对于少量的有标签数据,模型前期快速过拟合的问题。
作者:Qizhe Xie、Eduard Hovy、Minh-Thang Luong、Quoc V. Le
论文链接:https://arxiv.org/pdf/1911.04252.pdf



















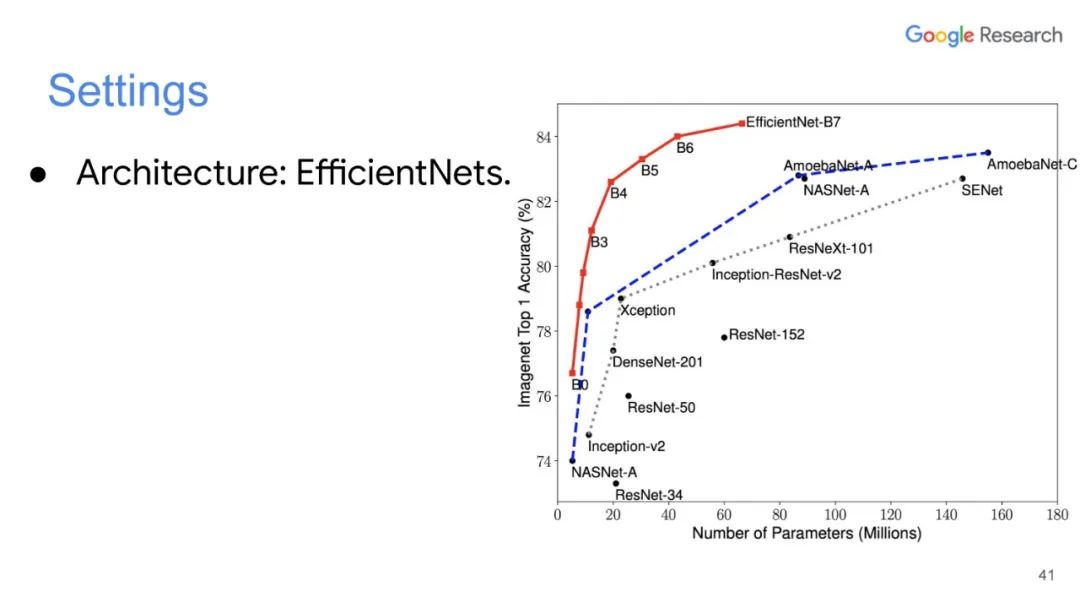

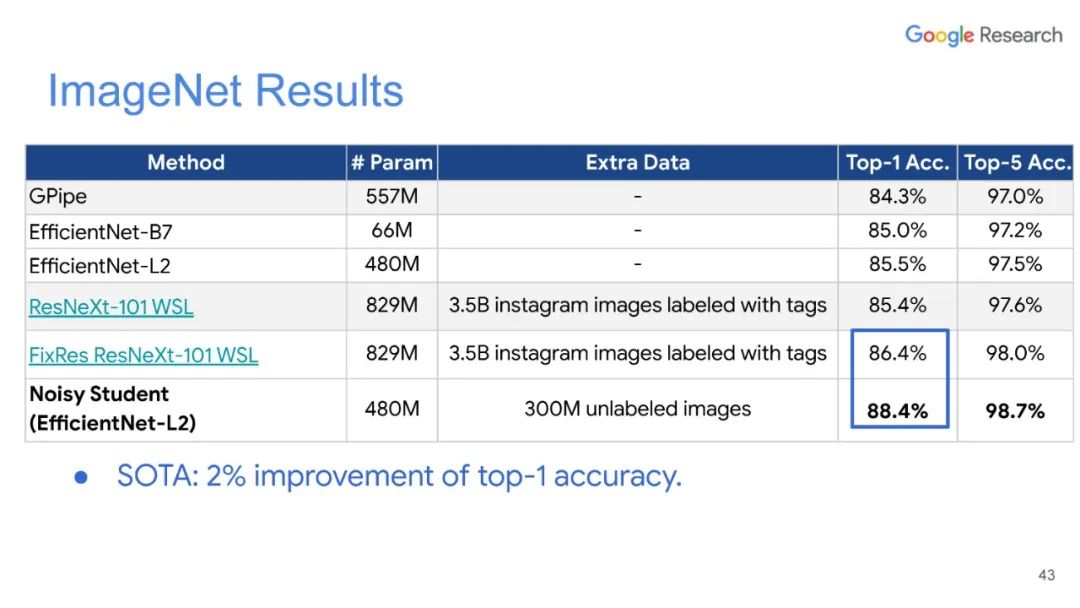

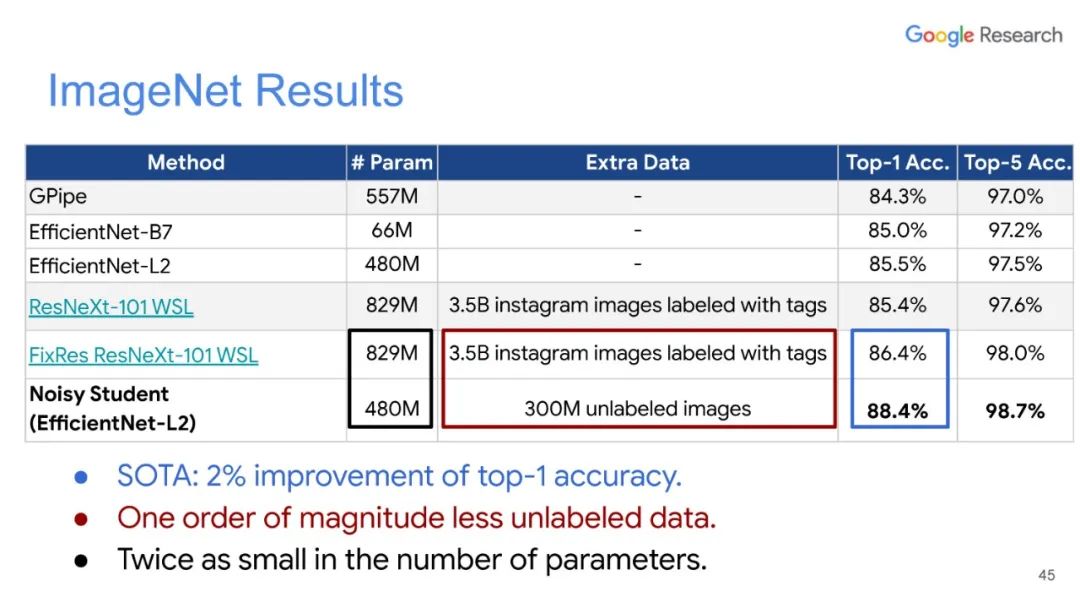
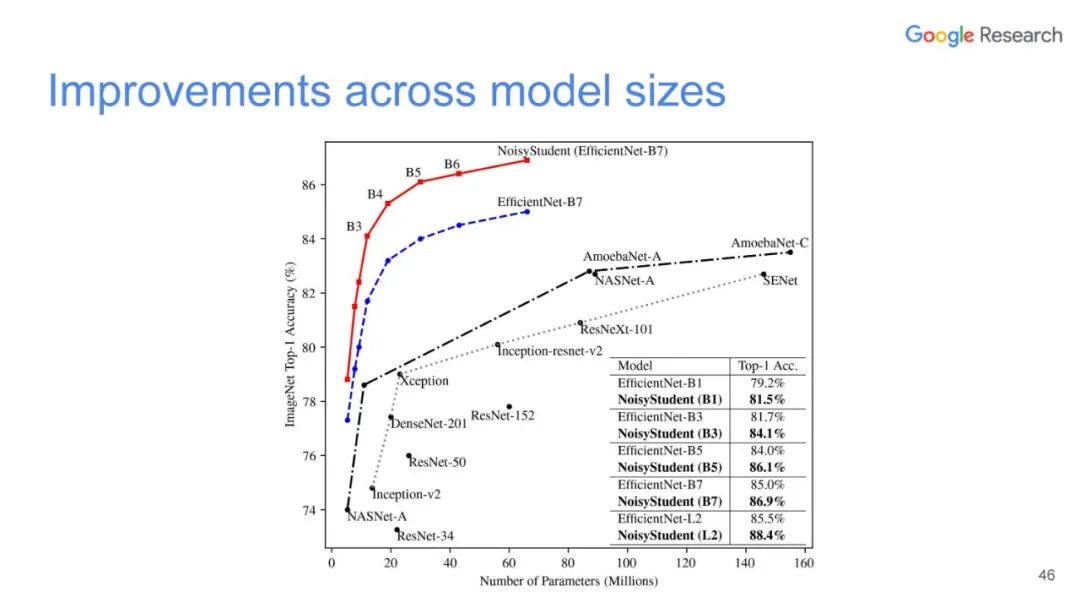






















专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“UDA” 就可以获取《Google AI-Luong,无标记数据学习, 83ppt, learning from Unlabeled Data》专知下载链接






