新任务引介 | Embodied Question Answering
导读
本次分享的论文提出了一个新的任务 Embodied Question Answering (EQA)。在这个任务里面,一个agent在三维虚拟空间中进行随机出现,然后问这个agent一个问题,agent为了回答这个问题,需要在环境中进行探索和信息整合。这个任务需要agent具有主动的认知、语言理解能力、目标驱动的探索、常识推理并将自然语言的信息整合到动作序列中。
作者简介
本篇论文的作者来自于佐治亚理工学院和Facebook的AI研究院。他们结合虚拟空间环境构造了一个新的、极具挑战性的问答系统EQA,并进行了初探性的工作,开放了数据集和基线系统的代码,以期望有更多的研究者一同为这个有趣、富有挑战性的任务做出进展性工作。
论文作者列表:Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, Dhruv Batra.
论文分享人:EriC. MA
CVPR 2018落幕,一系列的研究者的oral带给我们最新前沿的关注点。今天我们分享的论文是FAIR(Facebook AI Research)发表在CVPR 2018上的工作。在这个工作中,作者提出了一个崭新的问答任务Embodied Question Answering(下面称EQA),该任务是融合多模态信息,通过向agent提出文本问题,需要其在虚拟的空间环境中进行路径规划和探索,以到达目标位置并进行答案的反馈。在当前的EQA任务中,答案仍然是处于一个封闭集合中,即agent可以做出的回答是在一个封闭的答案集中进行选择,可以看作是一个分类任务,根据文本问题和环境探索后得到的信息整合,分类得到一个最为契合的答案进行输入。本篇论文的主要贡献是提出了EQA的机器学习任务;实现了了一个agent系统,可以在环境中进行探索,并回答一些问题;利用了模仿学习等方法来辅助agent进行预学习,得到了不错的效果,并对泛化性能进行了相应的探索;其在一个虚拟3D的屋子环境里进行了实验,使用的是修改后的SUNCG数据集[2],agent在虚拟环境中进行交互,可以不用考虑安全性等一系列的问题,使得模型得到了非常大的简化;同时作者开放了EQA的数据集和虚拟平台环境,便于研究者们在这个新任务中提出自己的解决方案,也为后续继续完善这个任务提供了便利的途径。
图1给出了EQA的一个形象化的表述,在这个例子中,向agent提出的文本问题为“车是什么颜色的?”,agent经过在虚拟的环境中进行探索,当发现车子后,返回给系统“车是橘黄色的!”
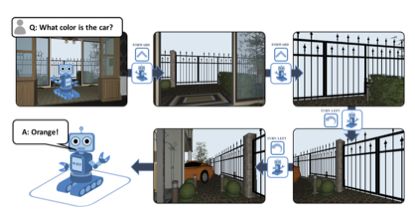
图1 EQA任务举例[1]
EQA的最终目标是:agent可以理解他们所处的环境(通过视觉等感知方式),具有沟通交流的能力(例如利用自然语言的一个对话),可以采取一定的动作(例如在环境中根据问答或对话进行主动的环境探索)。下面对agent需要具有的一些能力进行具体的分析:
主动探索性: 由于agent的出现地点是在环境中随机生成的,所以agent需要进行一定的动作和移动去寻找能够回答问题的视觉信息。
常识信息推理: agent没有一个关于虚拟环境的地图,所以agent需要自行对环境进行探索。因此agent必须自行构建一个常识系统,就像人一样去比较有目的的进行探索房屋(例如一个人接收到一个问题厨具的颜色等,他会根据自己的常识经验直接前往厨房、餐厅等去查看,拿到相应的结果后再进行回答,而不会漫无目的的在房间中摸索)。
收敛性分析: 在这个EQA的任务上,难度就是agent的探索可能是很长时间都难以收敛的(比如说问题是大房子里一共有多少个小房中有椅子,这种情况下agent可能跑了很多次也不能给出完全正确的答案。此时开发者也不知道究竟是agent理解错问题了,还是没有识别出椅子,还是计数出现了错误,这就导致进行训练的时候,难度非常大),为了解决这种问题,作者提出利用模仿学习的策略给agent进行一个示范,或者是给出RL中的中途的一些引导进行前期的训练,以方便agent进行更好的学习和收敛。
在测试环节,agent是一个完全自我的系统,其无法得到关于环境的结构性表达,没有地图,没有位置信息,没有任何的启发式算法,没有外界的知识输入。其唯一可以拿到的就是模拟的摄像头采集到的RGB图像、问题文本,所使用的就是探索模型和已经训练好的QA模型。
EQA和之前的一些工作的对比:
1.VQA – 视觉问答中没有主动的动作,模型的输入只是单一图像配合文本类型的问题,模型在封闭答案集上分类选出最适合的答案,也有一些视觉问答任务是基于的生成式模型,根据图像和文本生成一段文本回答。
Video QA – 任务同VQA相似,将VQA中的单张图片的输入替换成视频(处理时往往采样为多帧的图像)即可。
Visual Dialog – 通过给模型输入单张图片和文本句子,使得模型根据给定的图片与用户进行对话的生成。
EQA – 本篇论文的工作,给定agent一个文本问题,需要agent自行规划探索路径进行主动的在虚拟环境中进行搜索关键位置,找到符合问题的场景后,利用探索的路径过程中得到的图像信息,并最终给出答案。
总的来说,EQA比VQA更具有挑战性,因为agent在主动探索的时候,探索路径的随机性更大,较VQA更难收敛;但是其优点是可以去找到更有利于agent生成正确答案的图像信息,也能让agent在学习的过程中学习到一定的推理信息。
EQA数据集简介:
House 3D – EQA的数据集的背景原型是SUNCG数据集[2],作者对该数据集进行适当的修改调整,得到了EQA的实验数据集。在这个过程中作者主要在环境中增添了一个agent,且对这个agent所设置的限制非常少,主要是其不可穿透3D虚拟环境中的墙和一些物品,对agent的高度、重量等物理属性都没有限制。在这个环境中,作者给agent提一个问题,希望agent可以利用语言、常识、视觉的信息进行推理以及对环境的探索来解答一系列的问题。
在这个3D虚拟环境中包含12种房间类型,50种目标类型(如图2所示)。

图2 EQA数据集-虚拟环境示例[1]
a)部分环境;b)可以提问的房间种类;c)可以提问的目标种类
关于问题的建模 – 在EQA的问题设置上,拥有非常多的问题模板,在具体的给agent提出问题前,是将希望提问的模块与模板进行替换,便可以生成一系列的问题,实际实现的过程可以理解成为一个键值填充的过程,如图3所示。

图3 EQA数据集问题模板示例[1]
构造了问题模板,便可以用之前设定好的目标来填充问题模板中的对应位置;agent回答问题的时候,通过探索房间,找到对应的目标以进行相应的回答。特别的,EQA的这个数据集不是静态的数据集,可以随时通过补充一些房间、目标,甚至是增多agent的个数,这也为后续数据集的扩充奠定了基础。
EQA v1数据集 – 这个数据集大概有5000个问题,建立在750个环境上,总共有45个特殊的物体以及7个特殊的房屋类型。统计起来,一个环境大概问了6个问题,最多的一个环境问了22个问题,最少的一个环境问了1个问题。在建设问题的过程中,会注意把一些不需要探索就可以知道答案的问题进行了删减,换言之,期望数据集中的数据都是需要agent在实际的环境中进行探索才可以有效问答。作者开源了3D虚拟环境的数据集[3]以及EQA中问题产生的代码[4]。
作者在这篇论文中提出了一个解决EQA的初探性工作:利用层次化的模型来解决EQA问题。
首先agent随机在环境中生成初始位置,然后接收到一个问题,agent只能利用其唯一具有的一个RGB摄像机,然后在环境中进行相应的探索以给出答案;在EQA中,agent不会事先得到环境的任何表达,也不会有任何额外的信息。
因此对每一个agent建模可以利用的包含4个模块 - 视觉、语言、探索、回答。其在训练的过程中是接受完全自然的数据(像素和单词),然后进行一个全屋子/全环境的探索,最终给出一个视觉问答的答案。作者提出的模型架构是利用CNN、RNN模型的融合构建agent,特别的,在RNN中使用了Adaptive Computation Time(ACT) RNN [5], 这个网络架构的特点是可以得到输入、输出之间需要多少个计算步(Computational Steps),并利用一个“挂机”(halting)层来进行反向传播。 在agent中,将有一个“规划器”来控制agent都去走哪些方向,用一个“控制器”来决定每一个方向走多远。
视觉模态信息的构建:输入是224*224的RGB图像,是摄像头从3D房间中得到的视觉信息,模型架构是按块构架,每一个块是5*5的卷积网络、ReLU激活、批正则化、2*2的最大池化,然后重复四次这种架构块,最终得到一个尺寸固定的表达。对视觉信息的要求是需要其可以得到物体的属性(颜色、纹理等)、语义信息(例如目标的种类)、环境的地理信息(例如深度等)。为了达到这个目的,作者在一个预测框架上进行了多任务的预训练,以实现编码原始的RGB值、语义类别和像素的深度信息。
语言模态信息的构建:利用2层的LSTM进行编码语言,隐层节点数为128。在具体的实现中,将语言的问题编码同探索、回答模块进行了分离,因为在问题的编码中,有很多重要的信息,需要额外提取出来,指导agent去进行后续的操作。例如当问题是“厨房里面的椅子是什么颜色?”,此时“颜色”是探索的一个重要的目标,而厨房则是会引导、限制agent去探索的路径和区域。
探索模块的构建:用ACT-RNN来作为“规划器”,规划器的动作是选择方向,还有一个“控制器”,是控制走多少步。在这个部分注意有两个变量,一个是记录目前的时间点,另一个是记录走了多少步,这两个作为一个组合会对应一个图像帧,并进行记录。“控制器”是用一个前向多层全联接网络搭建的。直观上讲,“规划器”是将agent的意图编码到一个隐状态向量h,同时伴随着选择一个动作;而“控制器”则是控制agent进行行走,直到达到“规划器”的目标。
EQA中问答系统模块的构建:当agent决定停下来,或者是走到了最大的步数的时候,agent开始进行问题的回答,而且回答问题的依据便是根据记录的一系列的图像帧。作者在这篇文章使用的问答生成时是通过选择最后五帧,然后结合问题的编码送入神经网络,最后在172种可能的回答里面进行softmax,选择出得分最高的答案进行输出。
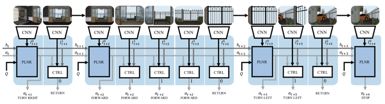
图4 ACT模型架构图[1]
图4中的Q表示文本问题的编码向量,at表示t时刻agent所采取的动作(action),ht为循环神经网络中的隐向量,PLNR为“规划器”,CTRL为“控制器”。特别需要注意的是,在图4的架构中,一系列的PLNR构建为一个循环神经网络,换言之,时间t的变化只在规划器进行动作的时候。具体实现的数据流为,问题编码和上一时刻(t-1)的动作及隐向量同时送入“规划器”,规划器输出该时刻(t)的动作(包含直线行走、转弯等),当“规划器”完成t这个时刻的动作选择后,数据流会立即流进“控制器”中,“控制器”接受当前时刻t的动作,视觉模块CNN给出的视觉特征向量,以及循环神经网络中的隐向量,并输出“控制器”的动作(延续“规划器”的动作或返回至“规划器”数据流中)。通过这样的数据流的分流,可以有效的利用“规划器”控制agent的动作序列,而利用“控制器”决定每个动作需要agent执行的次数。
模仿学习模块
训练的过程中分为两大部分,首先是利用生成的“专家数据”(或是探索的引导信息)进行模仿/监督学习,作为一个预训练的架构,再进行强化学习的策略梯度下降使得agent可以在更多的问题、环境中具有泛化性能。
独立的路径探索实现
模仿学习主要是希望agent可以利用一些专家的监督信息去学习一些探索最短路径的策略,在具体的实现的时候,是agent利用隐向量、文本问题编码以及当前的画面帧,来保持其处在最短路径上。
强化学习模块奖励的设定
作者给出了两种reward,一种是在最终的时候的通过回答问题的正确性进行给定reward,另一种是即时的奖励来帮助agent快速贴近目标。最终的reward给定的方式是如果agent回答了正确的答案并停止了给5分,其他情况给0分;关于即时的奖励是给动作的,即直走的动作时,给定的reward是用0.005 * 距离目标的位置变化(agent采取转向动作时没有奖励)。训练的方式是REINFORCE 策略梯度。训练的一些细节:所有的LSTM都是两层的堆叠架构,隐层有128维。向前走的动作每次最多是0.25m,转向每次转9度,即转向40次才能转360度。
EQA的目标是可以准确的回答问题。实验对比结果如图5所示。
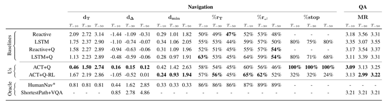
图5 EQA 实验结果对比[1]
作者构建了一些EQA的评测指标:
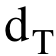
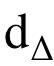
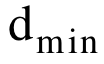
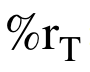
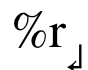
MR:agent对答案集中的答案进行按分数排序后的平均排序分。
实验对比系统的比较:
Reactive CNN : 利用最后看到的几帧来预测接下来的动作,这样的模型不是针对最后的目标去进行学习的,这个模型学习的任务就是简单记忆画面帧,然后希望从训练集的环境中泛化到测试集上。
Reactive CNN+Question: 这个模型是将画面帧同问题的编码联合起来预测接下来的动作,其目标是一个问题的编码而不是一个目标的图像。
在这两个模型中,agent的动作空间是{向前、左转、右转},其没有停止的动作,在具体的测试的时候,就是走一个最大的步长限制后停止。
LSTM+Question: 上述的Reactive模型没有记忆信息,而这一个模型是利用问题的编码,当前帧,之前的动作共同来预测接下来的动作。这些同ACT(作者提出的模型)是相同的,与这个模型比较的原因是作者探索其提出的规划器-控制器(planner-controller)架构的有效性。
HumanNav: AMT工人(亚马逊众包)远程操作agent进行任务的完成。
ShortestPaths + VQA: 利用VQA模型,在测试的时候,直接给它最短路径让agent沿最短路径到达目标物处。
几点实验结论分析:
1)所有的baseline的探索效果都非常差,主要表现在agent停止时,其距离目标的位置比出现在环境时还要远;
2)记忆模块可以帮助提高性能。一开始出现在环境时基本都是距离终点差不多远,而具有记忆模块的系统可以在最终的时候距离目标终点更近;
3)ACT的系统效果最好。利用Q-问题编码结合作者提出的系统可以在停机的时候距离目标位置最近,而Q问题编码+强化学习+作者的系统,达到了最好的回答效果;
4) 利用RL的模型,会让agent更多的进入目标物所在的房间,但是距离目标物的距离不能保证达到最小,这主要是因为RL具有更大的探索可能性,但是这样个缺点并没有影响agent回答问题的精度;
5)最短路径+VQA的系统没有达到非常好的效果,主要是因为agent根据最短路径走以后,到达终点时,其不一定正好面朝着目标物或可能视野有一定的限制,这导致了agent在回答问题时可能存在障碍。
总的来说,FAIR提出的这个新任务虽然目前回答的问题还比较简单(主要是某一个房间里具有什么目标,某些目标的颜色是什么等),但是EQA需要agent具有更多的操作和表现(需要有视觉、语言两种模态信息的处理,同时需要对路径进行规划,对环境进行探索,并最终得到答案的得分),涉及到多模态信息的融合、处理,虽然是一个初探性的任务和工作,但确实是一个极具挑战性和有趣的任务。另外,利用这样的虚拟环境,让agent具有真正去交互的环境,随着训练的深入,可以帮助agent自发性的学习到一些常识性的知识(例如厨具多在厨房里,车子多在车库里,浴缸多在洗手间中),这对后续的通用人工智能的研究和发展未尝不是一个崭新的尝试!
主要参考文献:
[1] A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Ba- tra. Embodied Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018.
[2] S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and
T. Funkhouser, “Semantic scene completion from a single
depth image,” in CVPR, 2017. 2, 4
[3] https://github.com/abhshkdz/House3D/tree/0bbba101a997908df16eee02936a0b539adeb0c2
[4] https://github.com/facebookresearch/EmbodiedQA/tree/master/data/question-gen/data
[5] A. Graves, “Adaptive computation time for recurrent neural networks,” CoRR, vol. abs/1603.08983, 2016.

历史文章推荐:
AI综述专栏 | 脑启发的视觉计算2017年度关键进展回顾(附PPT)
AI综述专栏 | 11页长文综述国内近三年模式分类研究现状(完整版附PDF)
AI综述专栏 | 朱松纯教授浅谈人工智能:现状、任务、构架与统一(附PPT)
【AIDL专栏】罗杰波: Computer Vision ++: The Next Step Towards Big AI





