题目: Large-scale Pretraining for Visual Dialog: A Simple State-of-the-Art Baseline
摘要:
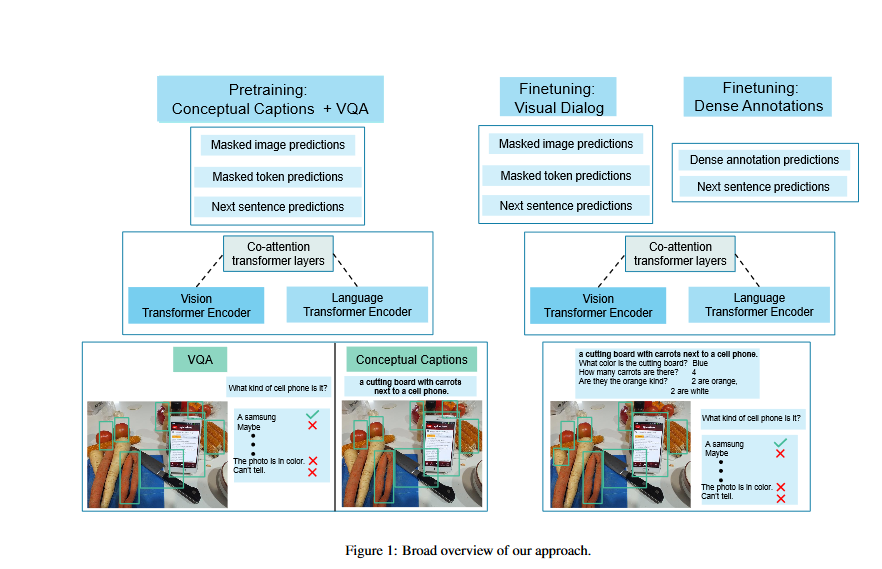
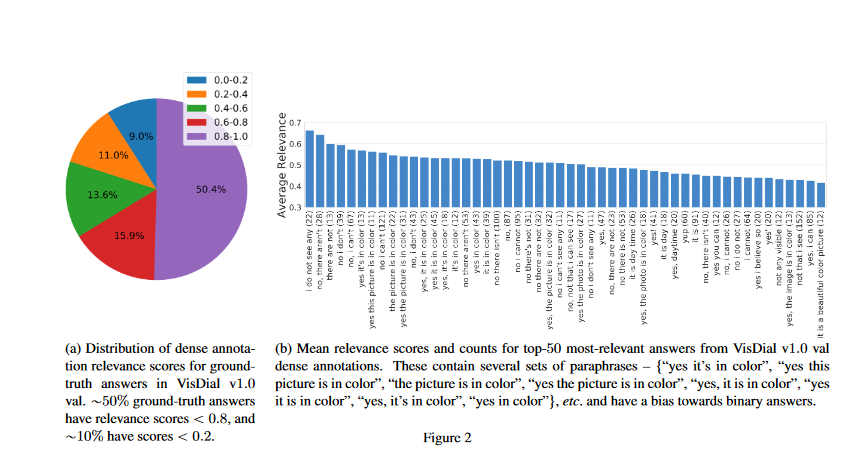
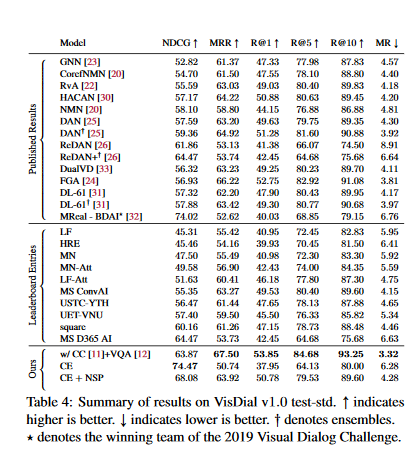
Visual dialog之前的工作重点是在VisDial数据集上单独训练深度神经网络模型,这已经取得了很大的进展,但也是限制和浪费。在这项工作中,随着最近的语言表示学习的趋势,我们介绍了一种方法,以利用在转移到可视化对话框之前,在相关的大规模视觉语言数据集上的预训练。具体地说,我们采用了最近提出的多回合可视地面会话序列的维尔伯特模型。我们的模型预先训练了概念说明和可视化问题回答数据集,并通过掩蔽语言建模和下一个感知预测目标对可视拨号进行了微调。我们最好的单模型在视觉对话方面达到了艺术级的水平,在NDCG和MRR上的表现超过了之前发表的作品(包括模型集成)的1%。
作者简介:
Vishvak Murahari是佐治亚理工学院计算机科学硕士二年级的学生,由Devi Parikh教授和Abhishek Das教授指导。在佐治亚理工学院获得了计算机科学学士学位(专注于人工智能和设备),研究的问题是计算机视觉、机器学习和自然语言处理的交叉领域,目前对会话人工智能感兴趣。
Dhruv Batra是佐治亚理工学院交互计算学院的副教授,也是Facebook人工智能研究(FAIR)的研究科学家。他的研究兴趣在于机器学习、计算机视觉、自然语言处理和人工智能的交叉领域。他的研究的长期目标是开发“看”(更普遍地通过视觉、听觉或其他感官感知他们的环境)、“说”(即在他们的环境中保持一个自然语言对话)、“行动”(例如,操纵他们的环境并与之互动以实现目标)和“理性”(即,在他们的环境中进行交流的智能体,考虑他们行动的长期后果)。
Devi Parikh是佐治亚理工学院交互计算学院的副教授,也是Facebook人工智能研究(FAIR)的研究科学家。她的研究兴趣包括计算机视觉和人工智能,特别是视觉识别问题。她最近的工作包括探索视觉和语言交叉的问题,并利用人机协作来构建更智能的机器。她还研究了其他一些课题,如分类器集成、数据融合、概率模型推理、3D重组、条形码分割、计算摄影、交互式计算机视觉、上下文推理、图像的层次表示和人类调试。
Abhishek Das是佐治亚理工学院计算机科学博士生,研究重点是深度学习及其在构建能看见(计算机视觉)、思考(推理/可解释)、说话(语言建模)和行动(强化学习)的智能体中的应用。