神经机器阅读理解最新综述:方法和趋势

作者丨刘姗姗
学校丨国防科技大学
研究方向丨自然语言处理
近年来,基于深度学习方法的机器阅读理解受到了广泛的关注。近日,来自国防科技大学的团队在arXiv上发布了预印版综述文章 Neural Machine Reading Comprehension: Methods and Trends。


该文总结了神经机器阅读理解领域的经典方法与新兴趋势,并对一些有待解决的开放性问题进行了讨论。想要快速了解这一领域的读者,不妨可以从这篇论文看起。
引言
机器阅读理解(MachineReading Comprehension, MRC)任务主要是指让机器根据给定的文本回答与文本相关的问题,以此来衡量机器对自然语言的理解能力。这一任务的缘起可以追溯到 20 世纪 70 年代,但是受限于小规模数据集和基于规则的传统方法,机器阅读理解系统在当时并不能满足实际应用的需求。
这种局面在 2015 年发生了转变,主要归功于以下两点:1)基于深度学习的机器阅读理解模型(神经机器阅读理解)的提出,这类模型更擅长于挖掘文本的上下文语义信息,与传统模型相比效果提升显著;2)一系列大规模机器阅读理解数据集的公布,如 CNN & Daily Mail [1]、SQuAD [2]、MS MARCO [3] 等,这些数据集使得训练深度神经模型成为可能,也可以很好的测试模型效果。神经机器阅读理解在近几年逐渐受到越来越多的关注,成为了学术界和工业界的研究热点。
本文对神经机器阅读理解的方法和新趋势进行了详尽的总结,主要分为以下几点:
介绍了典型的机器阅读理解任务,给出公式化定义与代表性数据集,并对不同任务进行了比较;
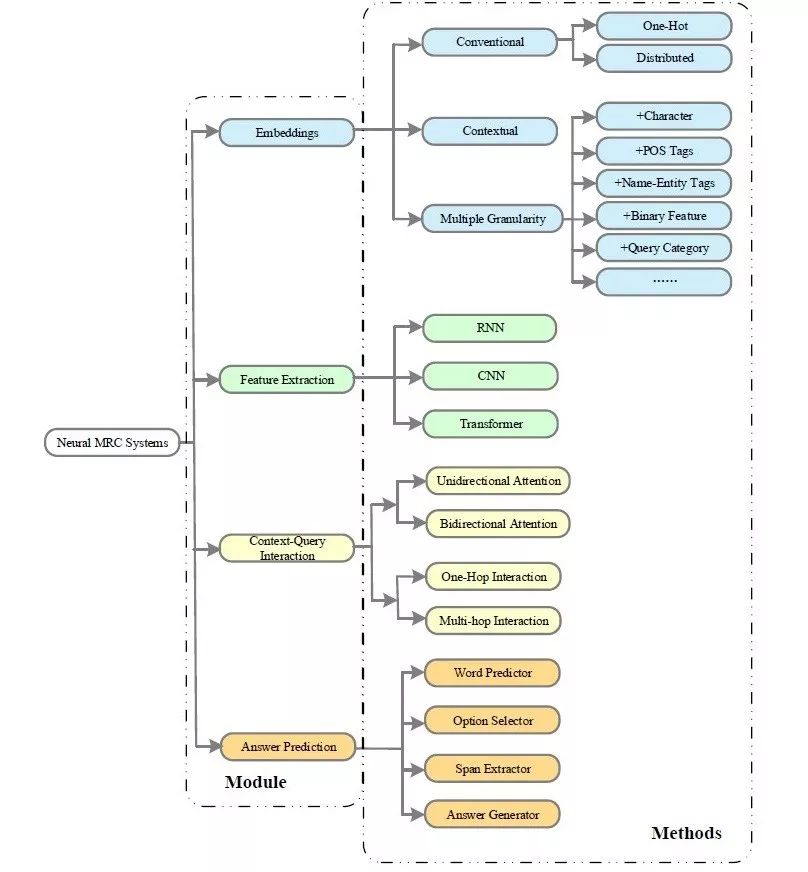
给出了机器阅读理解系统的基本框架,其中包括:嵌入编码、特征提取、文章-问题交互和答案预测四个模块;
介绍了机器阅读理解领域近两年出现的新兴研究趋势,并对一些有待解决的开放性问题进行了讨论。
任务
常见任务介绍
参考陈丹琦 [4] 在她的博士毕业论文中的观点,常见的机器阅读理解任务按照其答案形式可以分为以下四类:完形填空、多项选择、片段抽取和自由作答。
完形填空
任务定义:给定文章 C,将其中的一个词或者实体 a (a∈C) 隐去作为待填空的问题,完形填空任务要求通过最大化条件概率 P(a|C-{a}) 来利用正确的词或实体 a 进行填空。

完形填空任务在英语考试中非常常见。如 CLOTH [8] 中的例子所示,原文中的某个词被隐去,我们需要找到正确的词进行填空,使原文变得完整(虽然 CLOTH 数据集中提供了备选答案,但是这在完形填空任务中并不是必需的)。
代表数据集:CNN & Daily Mail [1]、CBT [5]、LAMBADA [6]、Who-did-What [7]、CLOTH [8]、CliCR [9]
多项选择
任务定义:给定文章 C、问题 Q 和一系列候选答案集合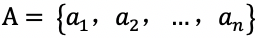
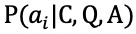
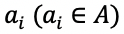

多项选择也是英语考试中的常见题型。如 RACE [11] 中的例子所示,根据文章内容提出一个相关问题,同时给出若干个候选答案,我们需要从候选答案中选择出能正确回答问题的答案。
代表数据集:MCTest [10]、RACE [11]
片段抽取
任务定义:给定文章 C(其中包含 n 个词,即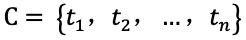
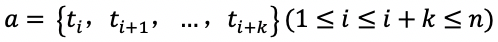

片段抽取任务要求从原文中抽取一个连续的句子(或词组)作为问题的答案。如 SQuAD [2] 中的例子所示,原文中的 inherentdifficulty 被抽取出来作为问题的答案。
代表数据集:SQuAD [2]、NewsQA [12]、TriviaQA [13]、DuoRC [14]
自由作答
任务定义:给定文章 C 和问题 Q,自由作答的正确答案 a 有时可能不是文章 C 的子序列,即 a⊆C 或 aØC。自由作答任务通过最大化条件概率 P(a|C,Q) 来预测回答问题 Q 的正确答案 a。

自由作答任务的答案形式最为灵活。如 MS MARCO [3] 中,提供了 10 篇相关的文章,回答问题时需要对文章中的线索进行归纳总结,与片段抽取任务相比,自由作答任务的答案不再限制于原文中的句子,更符合人们平时的作答习惯。
代表数据集:bAbI [15]、MS MARCO [3]、SearchQA [16]、NarrativeQA [17]、DuReader [18]
不同任务比较
我们从构建难易程度(Construction)、对自然语言理解的测试水平(Understanding)、答案灵活程度(Flexibility)、评价难易程度(Evaluation)和实际应用贴合程度(Application)等五个维度出发,对上述四类常见的机器阅读理解任务进行比较,依据每个任务在不同维度上的表现,得分最低 1 分、最高 4 分,结果如下图所示:
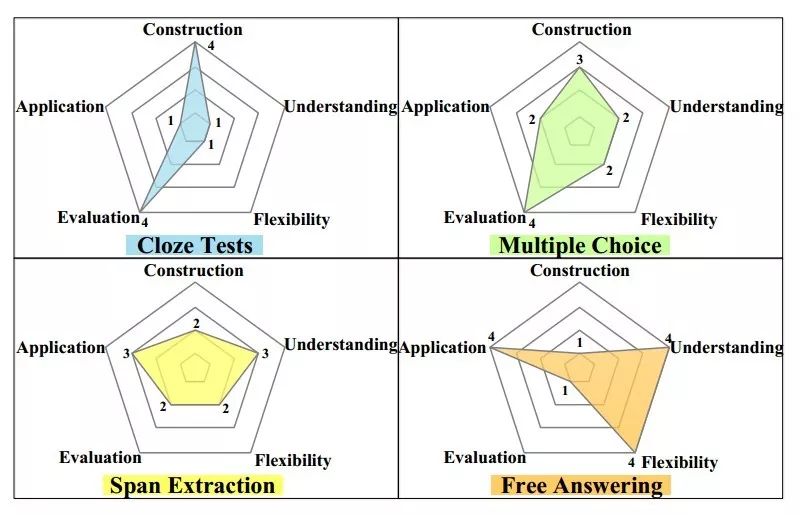
完形填空任务的数据集易于构建,可以用准确率指标进行评价。但是由于这一任务的答案限定为原文中的一个词或实体,所以并不能很好的测试机器对自然语言的理解能力且与实际应用相距较远。
多项选择任务由于提供了候选答案,答案的形式相较于完形填空而言更为灵活,构建数据集可以直接利用现有的语言测试中的多项选择题目,所以较为容易。由于该任务要求从备选答案中选出正确答案,模型的搜索空间相对较小,对自然语言理解的测试较为局限,提供备选答案与实际应用场景不太相符。
片段抽取任务是一个适中的选择,数据集相对容易构建,模型效果也可以使用精确匹配和 F1 分数进行衡量,答案限定为原文中的子片段,相较于多项选择有了更大的搜索空间,也在一定程度上能测试机器对自然语言的理解能力,但是和实际应用仍有一定差距。
自由作答任务答案形式非常灵活,能很好的测试对自然语言的理解,与现实应用最为贴近,但是这类任务的数据集构造相对困难,如何有效的评价模型效果有待进行更为深入的研究。
基本框架
典型的机器阅读理解系统一般包括嵌入编码、特征抽取、文章-问题交互和答案预测四个模块。
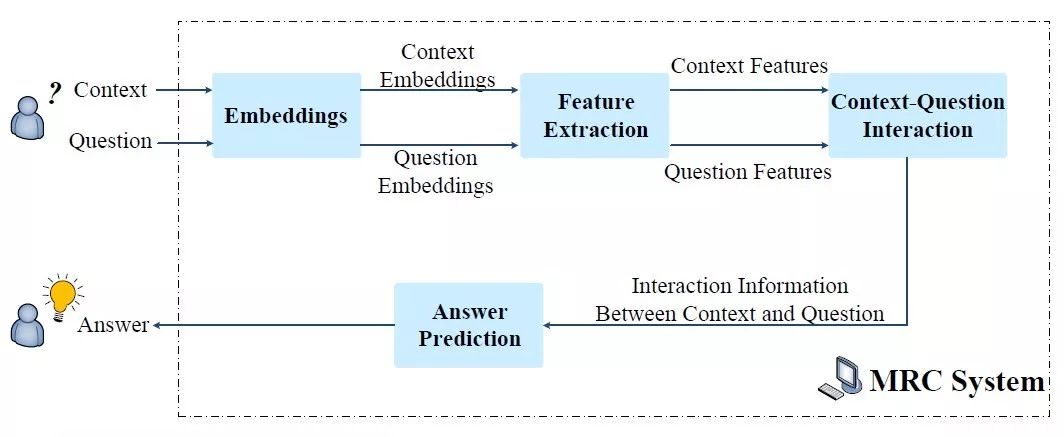
嵌入编码:这一模块将输入的自然语言形式的文章和问题转化成固定维度的向量,以便机器进行后续处理。早期常用的方法为传统的词表示方法,如独热表示和分布式词向量,近两年由大规模语料库预训练的基于上下文词表示方法也得到了广泛的应用,如 ELMo [19]、GPT [20]、Bert [21] 等。同时,为了能更好的表示语义句法等信息,上述词向量有时也可以和词性标签、命名实体、问题类型等语言特征结合后进行更细粒度的表示。
特征提取:经由嵌入编码层编码得到的文章和问题的词向量表示接着传递给特征提取模块,来抽取更多的上下文信息。这一模块中常用的神经网络模型有循环神经网络(RNN)、卷积神经网络(CNN)和基于多头自注意力机制的 Transformer 结构 [22]。
文章-问题交互:机器可以利用文章和问题之间的交互信息来推测出文章中哪些部分对于回答问题更为重要,为了实现这一目标,文章-问题交互模块常用单向或双向的注意力机制来强调原文中与问题更为相关的部分。与此同时,为了更深层次的挖掘文章和问题之间的关系,两者之间的交互过程有时可能会执行多次,以此来模拟人类在进行阅读理解时重复阅读的行为。
答案预测:这一模块基于前述三个模块累积得到的信息进行最终的答案预测。由于常见的机器阅读理解任务可以按照答案类型进行分类,所以这一模块的实现是高度任务相关的。
对于完形填空任务,答案输出是原文中的一个词或实体,一种做法是将文中相同词的注意力权重得分进行累加,最终选择得分最高的词作为答案 [23];对于多项选择任务,是从多个候选答案中挑选出正确答案,一般是对备选答案进行打分,选择得分最高的候选者作为答案;对于片段抽取任务,从原文中抽取一个连续的子片段作为答案,常用方法是 Wang & Jiang [24] 提出的预测答案开始和结束位置的概率的边界模型;对于自由作答任务,答案灵活度最高,不再限制于原文中,可能需要进行推理归纳,现有的方法常用抽取和生成相结合的模式。
新的研究趋势
基于知识的机器阅读理解
在人类阅读理解过程中,当有些问题不能根据给定文本进行回答时,人们会利用常识或积累的背景知识进行作答,而在机器阅读理解任务中却没有很好的利用外部知识,这是机器阅读理解和人类阅读理解存在的差距之一。
为了引入额外的外部知识,一些学者提出了基于知识的机器阅读理解任务,与之前所介绍的任务不同,这一任务的输入除了文章和问题,还有从外部知识库中抽取的知识,以此来提高机器进行答案预测的准确率。
代表性的基于知识的机器阅读理解数据集有 MCScript [25],其中的文本关于人类的一些日常活动,有些问题仅根据给定文本不能作答,需要一定的常识。例如回答“用什么来挖洞”(What was used to dig the hole?)这一问题,依据常识我们知道一般是用“铲子”(a shovel)而不是用“手”(bare hands)。

基于知识的机器阅读理解任务的挑战主要有:
1. 相关外部知识的检索(如何从知识库中找到“用铲子挖洞”这一常识);
2. 外部知识的融合(知识库中结构化的知识如何与非结构化的文本进行融合)。
带有不能回答问题的机器阅读理解
机器阅读理解任务有一个潜在的假设,即在给定文章中一定存在正确答案,但这与实际应用不符,由于给定文章中所含的知识有限,一些问题仅根据原文可能并不能做出回答,这就出现了带有不能回答问题的机器阅读理解任务。在这一任务中,首先机器要判断问题仅根据给定文章能否进行作答,如若不能,将其标记为不能回答,并停止作答;反之,则给出答案。
SQuAD2.0 [26] 是带有不能回答问题的机器阅读理解任务的代表数据集。在下面的例子中,问题是“1937 年条约的名字”(What was the name of the 1937 treaty?),但是原文中虽然提到了 1937 年的条约,但是没有给出它的名字,仅根据原文内容不能对问题进行作答,1940 年条约的名字还会对回答问题造成误导。

带有不能回答问题的机器阅读理解任务的挑战有:
1. 不能回答问题的判别(判断“1937 年条约的名字是什么”这个问题能否根据文章内容进行作答);
2. 干扰答案的识别(避免被 1940 年条约名字这一干扰答案误导)。
多文档机器阅读理解
在机器阅读理解任务中,文章是预先定义的,再根据文章提出问题,这与实际应用不符。人们在进行问答时,通常先提出一个问题,再利用相关的可用资源获取回答问题所需的线索。
为了让机器阅读理解任务与实际应用更为贴合,一些研究者提出了多文档机器阅读理解任务,不再仅仅给定一篇文章,而是要求机器根据多篇文章对问题进行作答。这一任务可以应用到基于大规模非结构化文本的开放域问答场景中。多文档机器阅读理解的代表数据集有 MS MARCO [3]、TriviaQA [13]、SearchQA [16]、DuReader [18] 和 QUASAR [27]。
多文档机器阅读理解的挑战有:
1. 相关文档的检索(如何从多篇文档中检索到与回答问题相关的文档)
2. 噪声文档的干扰(一些文档中可能存在标记答案,但是这些答案与问题可能存在答非所问的情况)
3. 检索得到的文档中没有答案
4. 可能存在多个答案(例如问“美国总统是谁”,特朗普和奥巴马都是可能的答案,但是哪一个是正确答案还需要结合语境进行推断)
5. 需要对多条线索进行聚合(回答问题的线索可能出现在多篇文档中,需要对其进行总结归纳才能得出正确答案)。
对话式阅读理解
机器阅读理解任务中所提出的问题一般是相互独立的,而人们往往通过一系列相关的问题来获取知识。当给定一篇文章时,提问者先提出一个问题,回答者给出答案,之后提问者再在回答的基础上提出另一个相关的问题,多轮问答对话可以看作是上述过程迭代进行多次。为了模拟上述过程,出现了对话式阅读理解,将对话引入了机器阅读理解中。
对话式阅读理解的代表性数据集有 CoQA [28]、QuAC [29] 等。下图展示了 CQA 中的一个对话问答的例子。对于给定的文章,进行了五段相互关联的对话,不仅问题之间存在联系,后续的问题可能与之前的答案也有联系,如问题 4 和问题 5 都是针对问题 3 的答案 visitors 进行的提问。

对话式阅读理解存在的挑战有:
1. 对话历史信息的利用(后续的问答过程与之前的问题、答案紧密相关,如何有效利用之前的对话信息);
2. 指代消解(理解问题 2,必须知道其中的 she 指的是 Jessica)。
开放性问题讨论
外部知识的引入
常识和背景知识作为人类智慧的一部分常常用于人类阅读理解过程中,虽然基于知识的机器阅读理解任务在引入外部知识方面有一定的尝试,但是仍存在不足。
一方面,存储在知识库中的结构化知识的形式和非结构化的文章、问题存在差异,如何将两者有效的进行融合仍值得研究;另一方面,基于知识的机器阅读理解任务表现高度依赖于知识库的构建,但是知识库的构建往往是费时费力的,而且存储在其中的知识是稀疏的,如果不能在知识库中直接找到相关的外部知识,可能还需要对其进行进一步的推理。
机器阅读理解系统的鲁棒性
正如 Jia & Liang [30] 指出的,现有的基于抽取的机器阅读理解模型对于存在误导的对抗性样本表现非常脆弱。如果原文中存在干扰句,机器阅读理解模型的效果将大打折扣,这也在一定程度上表明现有的模型并不是真正的理解自然语言,机器阅读理解模型的鲁棒性仍待进一步的提升。
限定文章带来的局限性
机器阅读理解任务要求机器根据给定的原文回答相关问题,但是在实际应用中,人们往往是先提出问题,之后再利用可用的资源对问题进行回答。多文档机器阅读理解任务的提出在一定程度上打破了预先定义文章的局限,但是相关文档的检索精度制约了多文档机器阅读理解模型在答案预测时的表现。信息检索和机器阅读理解需要在未来进行更为深度的融合。
推理能力的缺乏
现有的机器阅读理解模型大多基于问题和文章的语义匹配来给出答案,这就导致模型缺乏推理能力。例如,给定原文“机上五人地面两人丧命”,要求回答问题“几人丧命”时,机器很难给出正确答案“7 人”。如何赋予机器推理能力将是推动机器阅读理解领域发展的关键问题。
本文对 Neural Machine Reading Comprehension: Methods and Trends 一文的主要内容进行了介绍,由于篇幅限制,介绍较为粗略,感兴趣的读者可以参看原论文的详细介绍。
参考文献
[1] Hermann K M, KociskyT, Grefenstette E, et al. Teaching machines to read and comprehend[C]//Advancesin neural information processing systems. 2015: 1693-1701.
[2] Rajpurkar P, Zhang J, Lopyrev K, et al. Squad: 100,000+ questions for machinecomprehension of text[J]. arXiv preprint arXiv:1606.05250, 2016.
[3] Nguyen T, Rosenberg M, Song X, et al. MS MARCO: A Human Generated MAchineReading COmprehension Dataset[J]. choice, 2016, 2640: 660.
[4] Danqi Chen. Neural Reading Comprehension and Beyond. PhD thesis, StanfordUniversity, 2018.
[5] Hill F, Bordes A, Chopra S, et al. The goldilocks principle: Reading children'sbooks with explicit memory representations[J]. arXiv preprint arXiv:1511.02301,2015.
[6] Paperno D, Kruszewski G, Lazaridou A, et al. The LAMBADA dataset: Wordprediction requiring a broad discourse context[J]. arXiv preprintarXiv:1606.06031, 2016.
[7] Onishi T, Wang H, Bansal M, et al. Who did what: A large-scale person-centeredcloze dataset[J]. arXiv preprint arXiv:1608.05457, 2016.
[8] Xie Q, Lai G, Dai Z, et al. LARGE-SCALE CLOZE TEST DATASET DESIGNED BYTEACHERS[J]. arXiv preprint arXiv:1711.03225, 2017.
[9] Šuster S, Daelemans W. Clicr: A dataset of clinical case reports for machinereading comprehension[J]. arXiv preprint arXiv:1803.09720, 2018.
[10] Richardson M, Burges C J C, Renshaw E. Mctest: A challenge dataset for theopen-domain machine comprehension of text[C]//Proceedings of the 2013Conference on Empirical Methods in Natural Language Processing. 2013: 193-203.
[11] Lai G, Xie Q, Liu H, et al. Race: Large-scale reading comprehension datasetfrom examinations[J]. arXiv preprint arXiv:1704.04683, 2017.
[12] Trischler A, Wang T, Yuan X, et al. Newsqa: A machine comprehension dataset[J].arXiv preprint arXiv:1611.09830, 2016.
[13] Joshi M, Choi E, Weld D S, et al. Triviaqa: A large scale distantly supervisedchallenge dataset for reading comprehension[J]. arXiv preprintarXiv:1705.03551, 2017.
[14] Saha A, Aralikatte R, Khapra M M, et al. Duorc: Towards complex languageunderstanding with paraphrased reading comprehension[J]. arXiv preprintarXiv:1804.07927, 2018.
[15] Weston J, Bordes A, Chopra S, et al. Towards ai-complete question answering: Aset of prerequisite toy tasks[J]. arXiv preprint arXiv:1502.05698, 2015.
[16] Dunn M, Sagun L, Higgins M, et al. Searchqa: A new q&a dataset augmentedwith context from a search engine[J]. arXiv preprint arXiv:1704.05179, 2017.
[17] Kočiský T, Schwarz J, Blunsom P, et al. The narrativeqa reading comprehensionchallenge[J]. Transactions of the Association for Computational Linguistics,2018, 6: 317-328.
[18] He W, Liu K, Liu J, et al. Dureader: a chinese machine reading comprehensiondataset from real-world applications[J]. arXiv preprint arXiv:1711.05073, 2017.
[19] Peters M E, Neumann M, Iyyer M, et al. Deep contextualized wordrepresentations[J]. arXiv preprint arXiv:1802.05365, 2018.
[20] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding bygenerative pre-training[J]. URL https://s3-us-west-2. amazonaws.com/openai-assets/ researchcovers/languageunsupervised/language understandingpaper. pdf, 2018.
[21] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectionaltransformers for language understanding[J]. arXiv preprint arXiv:1810.04805,2018.
[22] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advancesin neural information processing systems. 2017: 5998-6008.
[23] Kadlec R, Schmid M, Bajgar O, et al. Text understanding with the attention sumreader network[J]. arXiv preprint arXiv:1603.01547, 2016.
[24] Wang S, Jiang J. Machine comprehension using match-lstm and answer pointer[J].arXiv preprint arXiv:1608.07905, 2016.
[25] Ostermann S, Modi A, Roth M, et al. Mcscript: A novel dataset for assessingmachine comprehension using script knowledge[J]. arXiv preprintarXiv:1803.05223, 2018.
[26] Rajpurkar P, Jia R, Liang P. Know What You Don't Know: Unanswerable Questionsfor SQuAD[J]. arXiv preprint arXiv:1806.03822, 2018.
[27] Dhingra B, Mazaitis K, Cohen W W. Quasar: Datasets for question answering bysearch and reading[J]. arXiv preprint arXiv:1707.03904, 2017.
[28] Reddy S, Chen D, Manning C D. Coqa: A conversational question answeringchallenge[J]. Transactions of the Association for Computational Linguistics,2019, 7: 249-266.
[29] Choi E, He H, Iyyer M, et al. Quac: Question answering in context[J]. arXivpreprint arXiv:1808.07036, 2018.
[30] Jia R, Liang P. Adversarial examples for evaluating reading comprehensionsystems[J]. arXiv preprint arXiv:1707.07328, 2017.

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文



