机器翻译中丢掉词向量层会怎样?

论文标题:
Neural Machine Translation without Embeddings
论文作者:
Uri Shaham,Omer Levy
论文链接:
https://arxiv.org/pdf/2008.09396.pdf
代码链接:
https://github.com/UriSha/EmbeddinglessNMT (待开源)
词向量
长期以来,词向量被认为是深度学习模型下不可缺少的一部分,从Word Embedding开始,词向量被普遍认为可以建模隐空间中的语言单元的语义。
但是,发展到如今基于Transformer模型的时代,词向量更多地是被默认当做模型输入和输出的一部分。它在当今模型下的作用似乎成为了业内普遍接受的规则。
词向量在当下的使用方法是将离散的语言单元映射为连续值的向量。比如字典大小为 ,那么我们就需要 的一个矩阵 去表示词向量。
在输入和输出的时候,词向量矩阵用于离散单元和模型隐藏层的“过渡”,即表示为 ,其中 是长度为 的输入句子,用one-hot表示成一个矩阵, 是位置编码,在输出的时候,就是 , 是模型的最后一层得到的向量。
现在的问题是,能不能去掉输入和输出的矩阵 ?也就是能不能不要词向量,直接把one-hot送入到模型中。本文通过实验回答了这个问题。
本文使用字节(Byte)编码表示输入到模型的语言单元,并且丢掉了传统的词向量,在多个语言的机器翻译任务上进行了实验。
结果表明,基于Byte编码的无词向量模型和基于BPE编码、字编码和Byte编码的有词向量模型效果没有显著区别,甚至在一些任务上还要更优。
这启发我们进一步思考对于机器翻译而言,编码的作用为何,词向量的作用为何,我们需不需要打破现在默认的词向量用法?
用Byte编码丢掉词向量
简单来说,本文使用长度为256的one-hot编码表示一个UTF-8字节(因为一个字节有8位,一共会产生256个不同的字节),这样的一个好处是不会出现OOV。
由于使用的是UTF-8编码,所以不同的语言会有不同的长度,比如英文每个字就是一个字节,阿拉伯语每个字就是两个字节,而中文每个字用三个字节表示。
但是这并不影响我们进行编码,只是对于中文而言,得到的编码后的句子会更长一些。
下图是一个使用各编码方案的例子。使用BPE编码得到的句子最短,其次是使用字编码,最后使用Byte编码会更长,因为在阿拉伯语中,每个字需要两个Byte表示。

对于一个句子,在用Byte编码处理后,可以得到一个输入One-hot矩阵 ,这里 是编码处理后的句子长度。
这时候,不再需要把它和词向量矩阵相乘,只需要再加上位置编码 (如果需要的话),然后再送入模型就行了。对于输出也是同样的操作,这可以总结为:
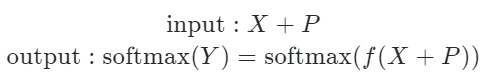
实验
本文在IWSLT上实验,选择了10个不同的语言,对每个语言 ,测试它们和英语互译的效果,即 。数据预处理、基线模型、超参设置详见原文。下表是实验结果。
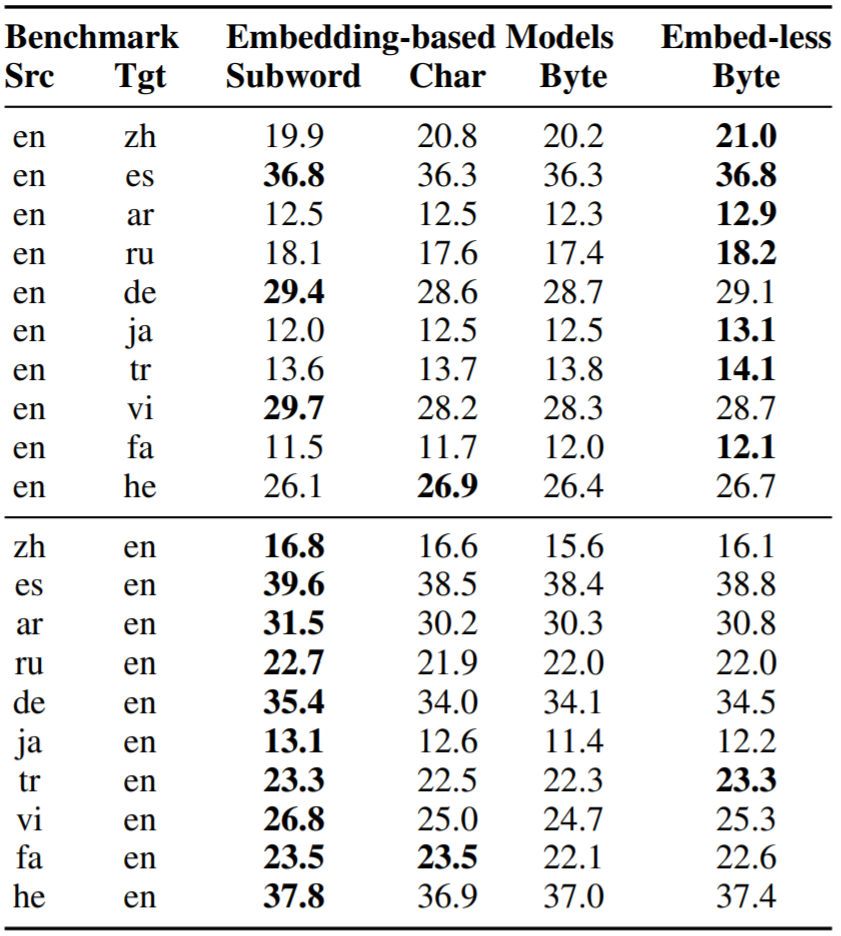
首先看同样是Byte编码的有词向量模型和无词向量模型。可以看到,无词向量模型都好于有词向量模型,和字编码(Char)相比,在大多数情况下Byte+Embed-less也都更好,这说明在编码粒度较细(Char和Byte)时,不加词向量效果会更好。
再来比较有词向量的Subword和无词向量的Byte。出乎意料的是,在 的10组实验里,有8组都是Byte更好。
但是在 的10组实验里,都是Subword更好,这似乎说明英语这种语言更适合使用Subword编码。这是一个非常有趣的现象。
小结
本文探究了基于Byte编码的无词向量机器翻译的效果,实验表明,使用Byte编码时,丢掉输入和输出的词向量层都结果没有太大的影响。
实验还发现,不同的语言对编码似乎非常敏感,尤其是英语比其他语言更加适合subword编码。未来可以进一步研究不同语言的编码偏好,以及词向量在现代深度模型下的作用。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




