跨 8 千个字学习知识,上下文要多长还是交给 Transformer 自己决定吧
选自Arxiv
参与:思源
Facebook 这个新 Transformer 能建模 8K Token 的上下文,换到中文语言模型来说,只要有需要,它能利用前面 8 千个汉字预测当前汉字到底是啥。
Facebook 的研究者提出了一种新型自注意力机制,它能够自主学习最优的注意力长度是多少,也就是说到底需要关注多长的上下文。这能允许我们有效地扩展 Transformer 中使用的最大上下文尺寸,同时还能保证内存占用和计算时间的合理性。
研究者在字符级的语言模型上测试了这种方法,并发现它在 text8 和 enwiki8 两个数据集上获得了当前最优的效果。值得注意的是,在模型学习到的最优上下文长度中,最大的一个达到了 8k 字符。换到中文语言模型来说,模型在预测某个汉字时需要利用另外 8 千个汉字的信息,这简直有点强。
如下图所示,只有少数 Attention heads 需要很长的上下文,大多数都只需要 50 字符左右的上下文,这和我们常见的做法是差不多的。另外有少数层级学出来的上下文非常长,我们如果只对它们增加上下文长度,那么内存占用和计算量都不会显著增加,达到 8 千字符的上下文也就不奇怪了。
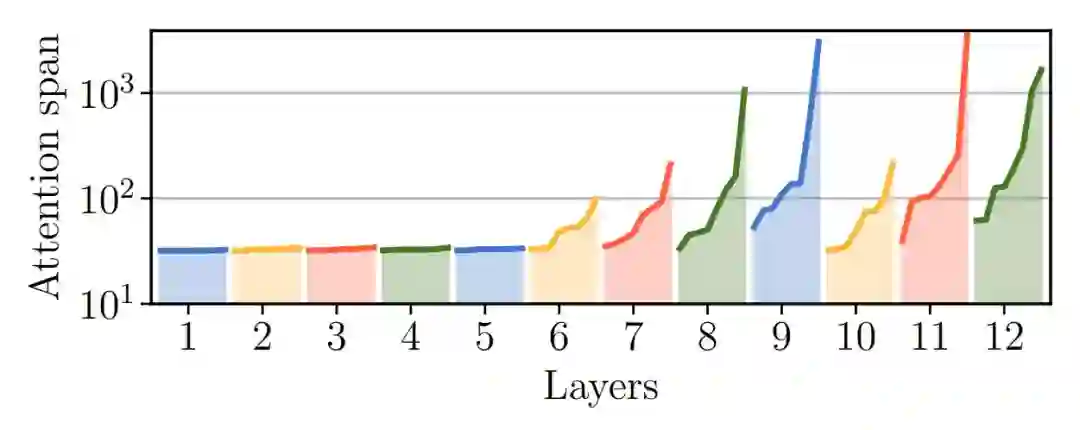
自适应注意力跨度学出来的上下文长度,模型一共 12 层,每层的 Attention heads 都不一样。
论文地址:https://arxiv.org/pdf/1905.07799.pdf
项目地址:https://github.com/facebookresearch/adaptive-span
Transformer 到底能建模多长语境
最开始我们还在使用 LSTM 搭建语言模型时,比较常见的方法就是将句子按照一定长度进行截断,例如每 50 个词截断之类的。然后将截断的词序列视为一个个样本,并进行训练。当时 LSTM 是一种「较长的短期记忆」,它能记住或建模的词长度有限,我们的序列弄再长也没什么用,反而会降低并行效率。
与循环神经网络不同,Transformer 能同时计算输入词序列内的所有表征,理论上它可以记住任意长度的上下文。但是 Transformer 这种耗内存的大模型很容易受到显存的限制,我们截断上下文的长度越长,Transformer 能注意的信息越多,同时占用的显存就越来越多。
尽管理论上 Transformer 没有建模长度的限制,但是实际受限于系统内存,其最多可能就建模长度为 N 的上下文。这个时候就需要 Transformer-XL 来帮忙了,它可以打破这种限制。Transformer-XL 先将某个定长序列学习到的表征缓存到内存里,然后在计算后一个定长序列时,它可以利用前面序列学习的结果。
通过这种方式,Transformer-XL 就能将上下文长度大大增加。但是我们会有一些疑问,超长上下文一定是更好的吗?它会不会有一些浪费算力的嫌疑?
让 Transformer 自己选择上下文长度吧
尽管 Transformer 允许跨很长的距离传递信息,但我们还是需要考虑计算效率与内存效率,这两个成本都会随着上下文长度的增加而急剧上升。一般实验中可以观察到,Transformer 很难将序列长度扩展到 1000 Tokens 以上,这对于字符级语言模型来说还是有一些问题的,因为有的依赖性甚至会跨越数千个 Token。
为此,在 Facebook 的这项工作中,研究者提出了一种 Self-attention 的替代方法,它能降低 Transformer 的计算成本。此外,新层级能自己学习最优的上下文大小,因此神经网络中的每一个注意力层级都会关注它们需要的上下文,并从这些上下文收集信息。
Facebook 通过实验发现,Transformer 层级如果接近输入数据,那么它们所需要的上下文序列是非常短的,可能就几十词左右。但是靠近输出的层级需要非常长的上下文,它们能达到几千的序列长度。
因为是自适应地选择上下文长度,所以尽管有些层级上下文长度非常长,但是总体计算成本和内存成本并不会增加,甚至在字符级语言模型达到新 SOTA 后,FLOPs 还能降低。
Transformer 该怎样选择上下文长度
在标准 Transformer 中,每一个注意力模块(Attention Head)都共享相同的注意力长度 S,它假设每一个注意力模块需要关注的长度相同,尽管它们关注的表征都各不相同。
如下图 1 所示,这个假设在字符级语言建模中并不成立,Head A 会关注更近的上下文,而 Head B 会从整个可用的上下文中提取有用的信息。因此,我们需要一种能自主选择上下文长度的注意力模块,这样才能降低计算力与内存成本。
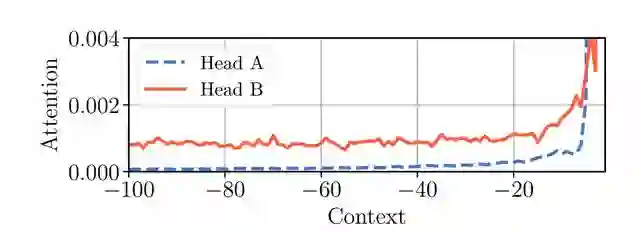
图 1:标准 Transformer 中两个不同 Head 的注意力模式。当前词的位置为 0,最大上下文长度为过去的 100 个词。
研究者表示,他们对每一个 Head 都会添加 Mask 函数,从而控制注意力关注的上下文长度。Mask 函数能将跨度距离映射到 [0, 1] 之间,且是一种单调非增函数。如下 Mask 函数 m_z 可以通过取值在 [0, S] 之间的实数 z 参数化:
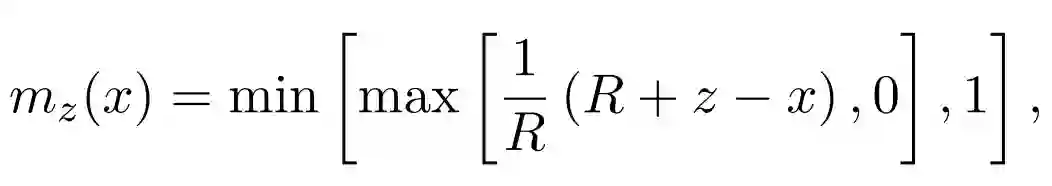
其中 R 是一个超参数,用来控制平滑度。最终注意力权重可以通过 Mask 函数确定只需要关注哪些序列。
实验
最后,研究者在一系列字符级语言模型中测试了这种方案的效率。具体而言,他们在 text8 和 enwik8 两个数据集上测试了自适应注意力跨度,这两个数据集都有 1 亿左右的 Tokens 数,也就是字符数。
如下表 1 所示为不同模型在 text8 数据集上的语言建模效果,其中 T12 表示 12 层的 Transformer,它也是专门用来训练字符级的语言模型。T-XL 则表示 Transformer-XL,可以看到它的上下文建模长度是非常长的,因此所需的计算资源也非常大。
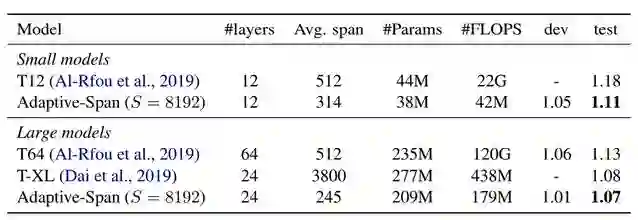
表 1:text8 数据集上的字符级语言模型,开发和测试集的度量标准都是 BPC,其它层级和计算资源的参数都如上所示。
不同模型在 enwiki8 数据集上的效果,横竖坐标的意义都和上面表 1 差不多。
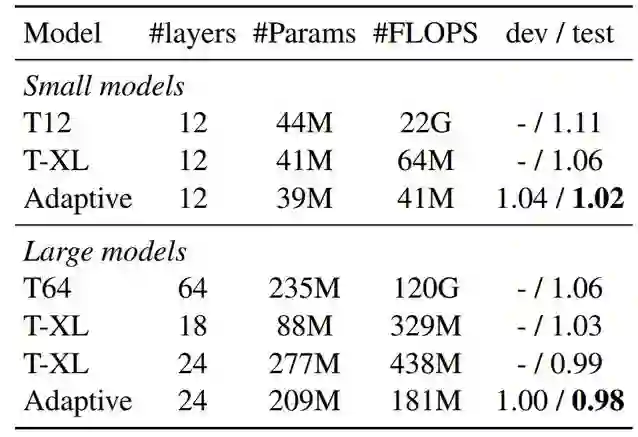
表 2:enwiki8 数据集上的效果,自适应跨度模型所采用的上下文上限 S=8129。
在下面图 3 中,作者对比了 Transformer 中固定上下文长度和可变上下文长度的差别。其中左图展示了随着上下文长度的增加,两种方式之间的效果对比。中间那幅则展示了平均上下文长度的变化,自适应的方式知道只有少数层级需要很长的上下文,所以平均下来增长并不大。最右边的那幅图展示了随着上下文长度的变化,模型需要计算力的变化。
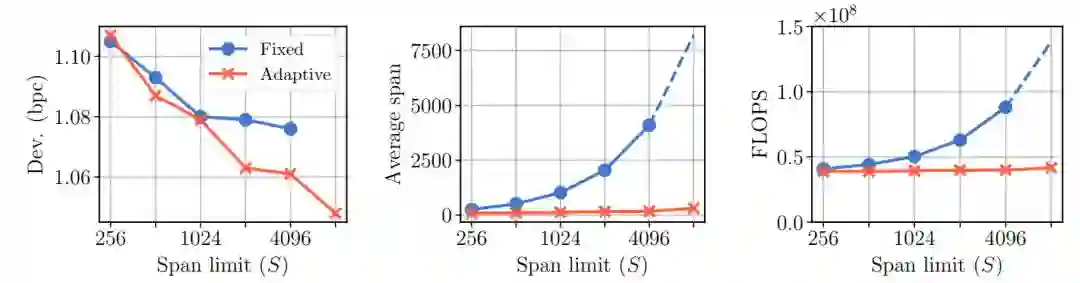
图 3:固定上下文与自适应上下文之间的对比。
本文为机器之心整理,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



