站在BERT肩膀上的NLP新秀们:XLMs、MASS和UNILM

作者丨高开远
学校丨上海交通大学硕士生
研究方向丨自然语言处理
写在前面
在前一篇站在 BERT 肩膀上的 NLP 新秀们(PART I)[1] 介绍了两个都叫 ERNIE 的模型,思路也挺相似的,都是给 BERT 模型增加外部知识信息,使其能更好地“感知“真实世界。
今天我们来看看另外几个有意思的 BERT 新秀:
XLMs from Facebook
MASS from Microsoft
-
UNILM from Microsoft
XLMs


对于 BERT 的改进可以大体分为两个方向:第一个是纵向,即去研究 BERT 模型结构或者算法优化等方面的问题,致力于提出一种比 BERT 效果更好更轻量级的模型;第二个方向是横向,即在 BERT 的基础上稍作修改去探索那些 Vanilla BERT 还没有触及的领域。直观上来看第二个方向明显会比第一个方向简单,关键是出效果更快。本文就属于第二类。
我们知道,BERT 预训练的语料全是单语言的,所以可想而知最终的模型所适用的范围基本也是属于单语范围的 NLP 任务,涉及到跨语言的任务可能表现就不那么好。
基于此,作者们提出了一种有效的跨语言预训练模型,Cross-lingual Language Model Pretraining (XLMs)。XLMs 可以认为是跨语言版的 BERT,使用了两种预训练方式:
基于单语种语料的无监督学习
基于跨语言的平行语料的有监督学习
其在几个多语任务上比如 XNLI 和机器翻译都拉高了 SOTA。那么我们就来看看具体的模型。
Shared sub-word vocabulary
目前的词向量基本都是在单语言语料集中训练得到的,所以其 embedding 不能涵盖跨语言的语义信息。为了更好地将多语言的信息融合在一个共享的词表中,作者在文本预处理上使用了字节对编码算法(Byte Pair Encoding, BPE),大致思想就是利用单个未使用的符号迭代地替换给定数据集中最频繁的符号对(原始字节)。这样处理后的词表就对语言的种类不敏感了,更多关注的是语言的组织结构。
关于 BEP 的具体栗子可以参考:Byte Pair Encoding example [2].
Causal Language Modeling (CLM)
这里的 CLM 就是一个传统的语言模型训练过程,使用的是目前效果最好的 Transformer 模型。对于使用 LSTM 的语言模型,通过向 LSTM 提供上一个迭代的最后隐状态来执行时间反向传播(backpropagation through time, BPTT)。
而对于 Transformer,可以将之前的隐状态传递给当前的 batch,为 batch 中的第一个单词提供上下文。但是,这种技术不能扩展到跨语言设置,因此在这里作者们只保留每个 batch 中的第一个单词,而不考虑上下文。
Masked Language Modeling (MLM)
这一个预训练目标同 BERT 的 MLM 思想相同,唯一不同的就是在于模型输入。BERT 的输入是句子对,而 XLM 使用的是随机句子组成的连续文本流。
Translation Language Modeling (TLM)
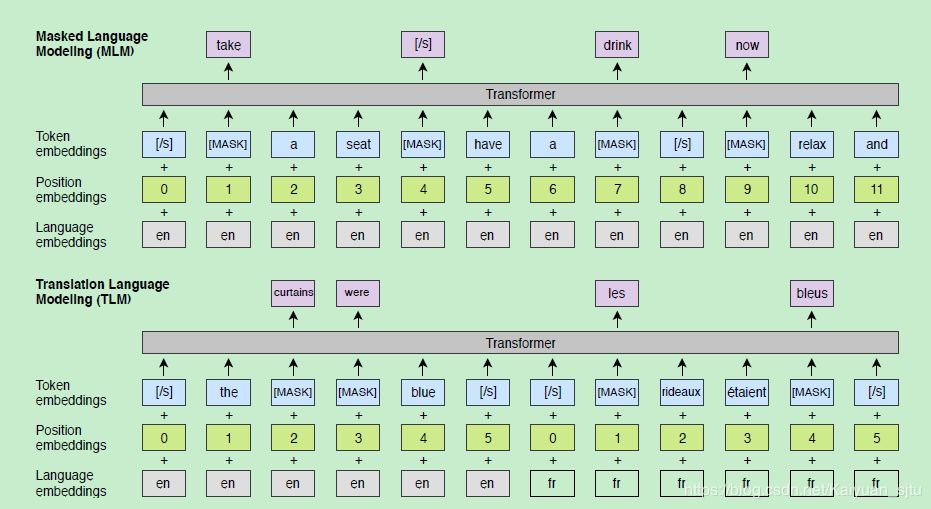
这一部分应该是对跨语言任务取得提升的最大原因。不同于以上两个预训练模型(单语言语料训练 + 无监督训练),翻译语言模型使用的是有监督的跨语言并行数据。如下图所示输入为两种并行语言的拼接,同时还将 BERT 的原始 embedding 种类改进为代表语言 ID 的 Laguage embedding 和使用绝对位置的 Position embedding。
TLM 训练时将随机掩盖源语言和目标语言的 token,除了可以使用一种语言的上下文来预测该 Token 之外(同 BERT),XLM 还可以使用另一种语言的上下文以及 Token 对应的翻译来预测。这样不仅可以提升语言模型的效果还可以学习到 source 和 target 的对齐表示。
MASS


我们知道,BERT 只使用了 Transformer 的 encoder 部分,其下游任务也主要是适用于自然语言理解(NLU),对于类似文本摘要、机器翻译、对话应答生成等自然语言生成(NLG)任务显然是不太合适的。
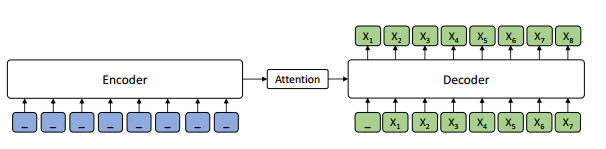
BERT 的大火,也带动了 NLP 届的 pre-training 大火,受到 BERT 的启发,作者们提出联合训练 encoder 和 decoder 的模型:Masked Sequence to Sequence Pre-training for Language Generation (MASS),框架如下:
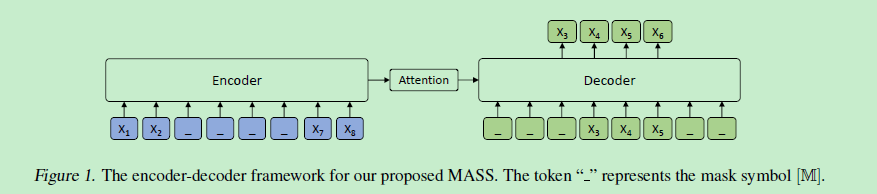
训练步骤主要分为两步:
1. Encoder:输入为被随机 mask 掉连续部分 token 的句子,使用 Transformer 对其进行编码;这样处理的目的是可以使得 encoder 可以更好地捕获没有被 mask 掉词语信息用于后续 decoder 的预测;
2. Decoder:输入为与 encoder 同样的句子,但是 mask 掉的正好和 encoder 相反,和翻译一样,使用 attention 机制去训练,但只预测 encoder 端被 mask 掉的词。该操作可以迫使 decoder 预测的时候更依赖于 source 端的输入而不是前面预测出的 token,防止误差传递。
MASS 预训练输入为 m 个 token 的句子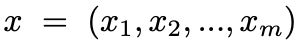
,其中
表示被 mask 掉的片段。MASS 预训练目的预测输入中被 mask 掉的
。
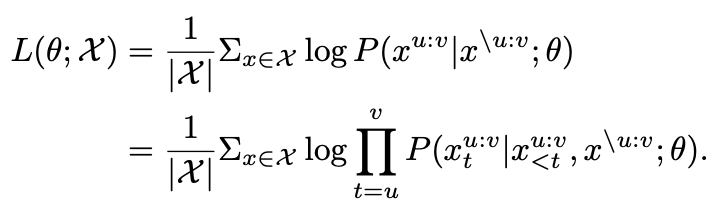
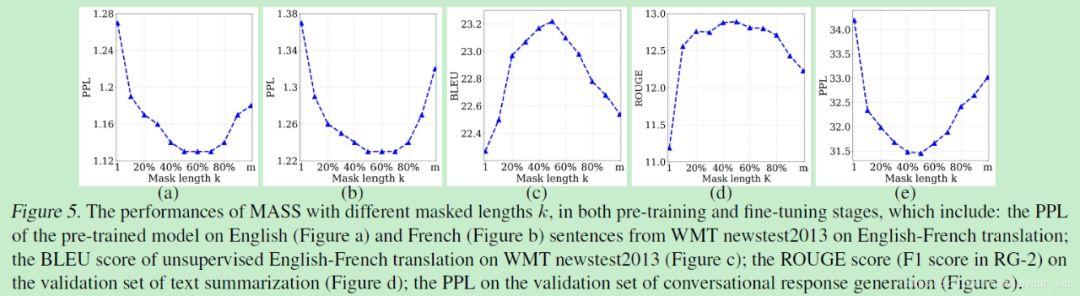
此外,作者们还提出了一个对于 mask 长度的超参数 k,并指出当 k=1 时,即 encoder 屏蔽一个 token,decoder 没有输入,该形式与 BERT 的 MLM 训练模型一致(但是 BERT 不是随机离散 mask 的嘛,好像还不太一样)。
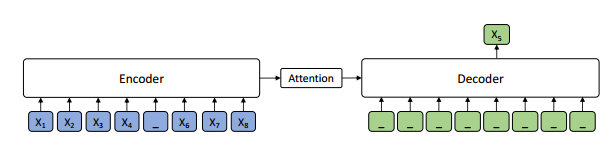
当 k=m 时,即 encoder 完全 mask 掉,decoder 输入为完整句子,该形式与 OpenAI 的 GPT 模型一致。
由于 K 值为超参数,属于人为设定,作者们又在文章末尾对其进行了分析,通过多个试验表明,当 k 为句子长度的 50%~70% 时模型效果最好。
UNILM


这个就更炸了,也是微软的最近才放出的工作,直接预训练了一个微调后可以同时用于自然语言理解和自然语言生成下游任务的模型:UNIfied pre-trained Language Model (UNILM)。
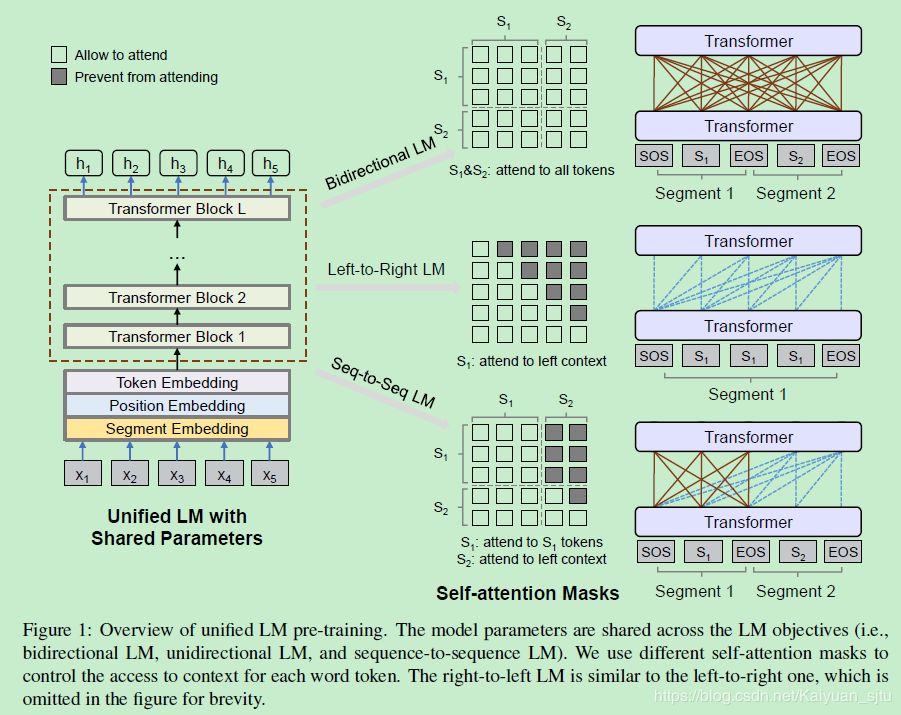
看完论文之后会发现非常自然,使用的核心框架还是 Transformer,不同的是预训练的目标函数结合了以下三个:
单向语言模型(同 ELMO/GPT)
双向语言模型(同 BERT)
seq2seq 语言模型(同上一篇)

注意哦,这里的 Transformer 是同一个,即三个 LM 目标参数共享,有点 multi-task learning 的感觉,可以学习到更 genneral 的文本表示。
接下来看本文模型:
Input Representation
模型的输入是一个序列,对于单向 LM 是一个文本片段,对于双向 LM 和 seq2seq LM 是两段文本。embedding 模式使用的是跟 BERT 一样的三类:
token embedding:使用 subword unit
position embedding:使用绝对位置
segment embedding:区分第一段和第二段
另外,[SOS] 为输入序列起始标志;[EOS] 为在 NLU 任务中为两个 segment 的分界标志,在 NLG 任务中为解码结束标志。
Backbone Network: Transformer
文中使用的是多层堆叠的 Transformer(24 层,与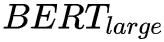
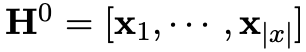

其中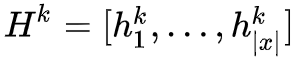
表示输入
在经过 K 层 transformer 之后的上下文表示。
重点来了。上面说将三个语言模型统一到了一起,那么是如何实现的呢?作者们这里使用的是 Self-attention Masks,即对不同的语言模型,设置不同的 mask 策略进行学习。
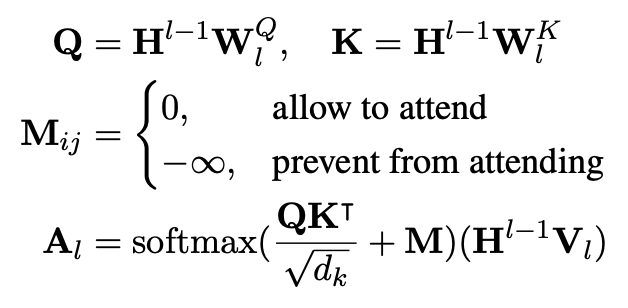
下面具体介绍各个模型的 Mask 策略。
Unidirectional LM
对于单向 LM(left-to-right or right-to-left),我们在做 attention 的时候对每一个词只能 attend 其一个方向的上下文。如对 left-to-right LM, 我们就只能 attend 该词左边的信息,需要将右侧的词给 mask 掉;对于 right-to-left LM 也是同理。这样我们得到的 Mask 矩阵就是一个上三角或者下三角。
Bidirectional LM
和 BERT 一样,双向 LM 在训练时可以看到左边和右边的信息,所以这里的 Mask 矩阵全是 0,表示全局信息可以 attend 到该 token 上。
Sequence-to-Sequence LM
对于 seq2seq LM,情况稍微复杂一点点,有点像上述两个 Mask 矩阵的结合版本。该模型输入为两个 segment S1 和 S2,表示为“[SOS] t1 t2 [EOS] t3 t4 t5 [EOS]”,encoder 是双向的即有四个 token 可以 attend 到 t1 和 t2 上;decoder 是单向的,仅仅能 attend 到一个方向的 token 以及 encoder 的 token,以 t4 为例,它只能有 6 个 token 可以 attend。
在训练时会随机 mask 掉两个 segment 中的 token,然后让模型去预测被 mask 掉的词。
Next Sentence Prediction
对于双向 LM,作者也设置了 NSP 预训练任务,除了特殊 TOKEN 不一样,其他跟 BERT 是一样的。
实验部分我也不多做分析了。
小结
对于以上三篇论文做个小的个人评价:大而美。
模型和数据都很大,但是最终出来的效果是美的,争取往小而美的方向发展。
对于 XLM 和 MASS 都是涉及跨语言模型,补充了 BERT 在 NLG 任务上的不足。模型层面而言 XLM 没有使用传统的 encoder-decoder 框架,属于比较讨巧的方式。
UNILM 可以同时处理 NLU 和 NLG 任务,在 GLUE 上首次不加外部数据打赢了 BERT。后续的改进可以考虑加入跨语言任务的预训练,比如 XLM 和 MASS 做的工作。
最后,如若文章理解或措辞有误,还请大家务必海涵指正。
参考文献
[1] https://blog.csdn.net/Kaiyuan_sjtu/article/details/90757442
[2] https://gist.github.com/ranihorev/6ba9a88c9e7401b603cd483dd767e783
[3] https://www.lyrn.ai/2019/02/11/xlm-cross-lingual-language-model/
[4] https://zhuanlan.zhihu.com/p/56152762
[5] https://zhuanlan.zhihu.com/p/56314795
[6] https://github.com/facebookresearch/XLM
[7] https://zhuanlan.zhihu.com/p/65346812
[8] https://www.zhihu.com/question/324019899
[9] https://mp.weixin.qq.com/s/U_pYc5roODcs_VENDoTbiQ

点击以下标题查看往期内容推荐:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 访问作者博客



