Meta发布全新检索增强语言模型Atlas,110亿参数反超5400亿的PaLM
![]()
新智元报道

新智元报道
【新智元导读】这个模型只用了64个例子,就在自然问题上达到了42%的准确率,并且超过了5400亿参数的PaLM。
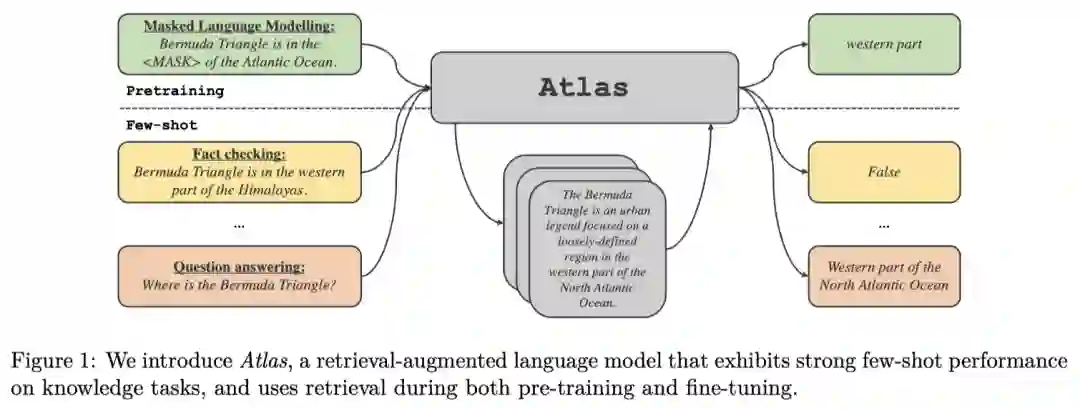
最近,Meta推出了一个全新的检索增强的语言模型——Atlas。
和那些动辄上千亿参数的前辈们不同,Atlas只有110亿的参数。
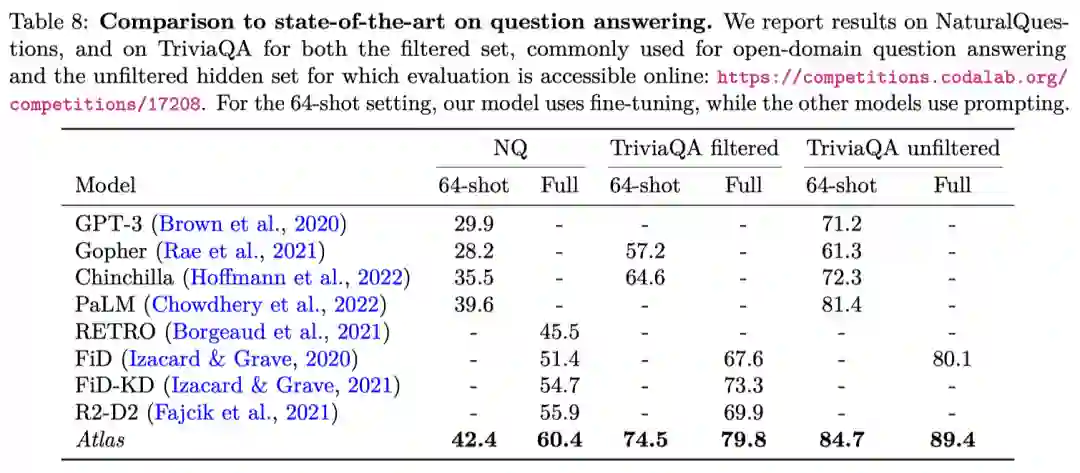
不过值得注意的是,Atlas虽然只有PaLM的1/50,但它只用了64个例子就在NaturalQuestions达到了42%以上的准确率,比PaLM这个5400亿参数的模型还高出了3%。

论文链接:https://arxiv.org/abs/2208.03299
检索增强模型
众所周知,世界知识对于自然语言处理来说是一个特别棘手的挑战,模型不仅需要理解任务的要求和如何产生输出,还必须存储和精确回忆大量的信息。
虽然在不需要世界知识的时候,小模型可以通过few-shot学习完成任务,但到目前为止,只有超大体量的模型在知识密集型的任务(如问题回答和事实核查)中显示出良好的效果。
而Atlas作为一个检索增强型的模型,往往可以超越上述限制。
结果表明,Atlas在few-shot问题回答(NaturalQuestions和TriviaQA)和事实核查(FEVER)上的表现优于更大的非增强模型,分别是超出了2.8%,3.3%和5.1%。
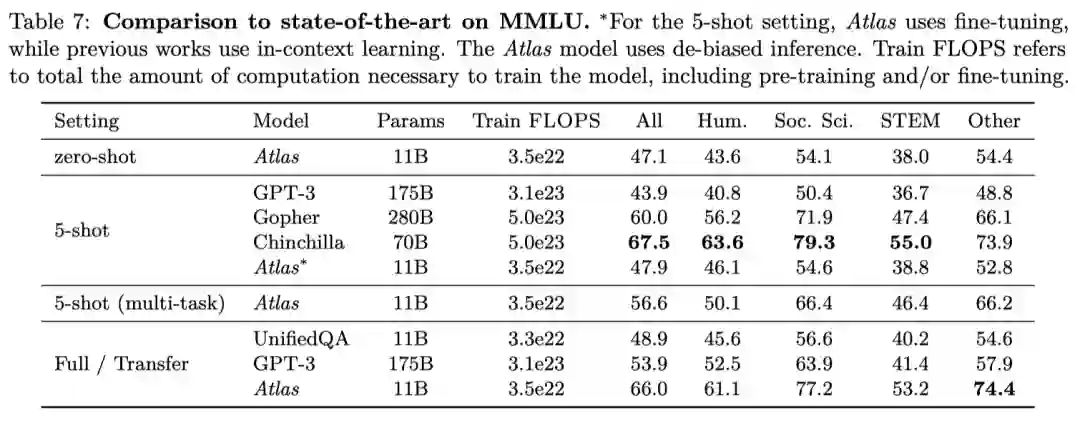
并且,Atlas在各种真实世界的测试(MMLU)上能与具有15倍以上参数的模型相当或更强。
此外,Atlas在全数据集设置中也刷新了SOTA。在NaturalQuestions上把准确率提高了8.1%,在TriviaQA上提高了9.3%,在5个KILT任务上也是如此。
更重要的是,Atlas检索到的段落可以被直接查验,从而获得更好的可解释性。此外还可以通过编辑甚至完全替换Atlas用于检索的语料库的方式,来保持模型一直都是最新的,无需重新训练。
LeCun表示,Atlas能够在问题回答和事实核查方面击败更大的模型,正是因为它可以从语料库中检索事实。

架构
Atlas遵循文本到文本的框架,也就是说,系统会得到一个文本查询作为输入,并生成一个文本输出。
例如,在回答问题的情况下,查询与问题相对应,模型需要生成答案。在分类任务中,查询对应于文本输入,模型生成词汇化的类别标签,即标签所对应的词。

Atlas基于两个子模型:检索器和语言模型。
当执行一项任务时,模型首先用检索器从大型文本语料库中检索出前k个相关文档。然后,这些文档和查询一起被送入语言模型,再由语言模型生成输出。检索器和语言模型都是基于预训练的Transformer网络。
检索器模块基于Contriever,一种基于连续密集嵌入的信息检索技术。Contriever使用一个双编码器结构,其中查询和文档由一个变换器编码器独立嵌入。在最后一层的输出上应用平均池化,以获得每个查询或文档的一个向量表示。然后,通过计算查询和每个文档的相应嵌入之间的点积,得到查询和每个文档之间的相似度分数。Contriever模型使用MoCo对比损失进行预训练,并且只使用无监督的数据。
密集检索器的一个优点是,查询和文档编码器都可以在没有文档注释的情况下,利用如梯度下降和蒸馏等技术进行训练。
语言模型依靠序列到序列模型的Fusion-in-Decoder modification,并在编码器中独立处理每个文档。然后,将对应于不同文档的编码器的输出连接起来,并在解码器中对这一单一序列进行交叉注意。在语言模型中处理检索到的文档的另一种方法是将查询和所有的文档连接起来,并将这个长序列作为模型的输入。
训练和评估
具体来说,作者使用Perplexity Distillation目标函数,以及掩码语言建模作为前置任务。并使用维基百科和Common Crawl的混合数据对这些模型进行预训练,用于训练数据和索引的内容。
作者检索了20个文档,每2500步更新一次索引,并对前100个文档进行重新排名。并使用AdamW对模型进行10,000次迭代的预训练,批大小为128。
MMLU的结果
作者将110亿参数的Atlas与诸如GPT-3和Chinchilla这些SOTA进行了比较。
结果显示,Atlas在zero-shot中的表现明显优于随机。结合去偏推理,Atlas的zero-shot得分甚至超过了5-shot的GPT-3(47.1% vs 43.9%)。
对于5-shot的设置,Atlas比GPT-3高出4%,同时使用的参数少了15倍,预训练计算量少了10倍。集合多任务训练之后,Atlas提高到56.6%,接近Gopher的5-shot性能(60.0%)。
最后,在全数据设置中,Atlas达到了65.6%的整体准确率,接近SOTA的水平。有趣的是,在这种设置下,Atlas的表现明显优于GPT-3,而在5-shot的设置下,它们的表现相似。
FEVER的结果
在15-shot的设置中,Atlas的得分是56.2%,比Gopher高出5.1分。
在64-shot的设置中,作者从整个训练集中均匀地选出用于训练的实例。而由此产生的训练集中,正样本是要多于负样本的。不过,Atlas依然达到了64.3%的准确率。
最后,作者在完整的训练集上对模型进行了微调,并取得了78%的准确率,只比ProoFVer低了不到1.5%。
其中,ProoFVer的架构采用的是一个用句子级注释训练的检索器,并提供与FEVER一起发布的维基百科语料库,而Atlas则是从CCNet和陈旧(2021年12月)的维基百科中检索。
于是,作者尝试着也采用由FEVER维基百科语料库组成的索引,果然Atlas刷新了SOTA,达到80.1%的水平。

结论
在本文中,作者介绍了Atlas,一个检索增强的大型语言模型。
结果表明,通过联合预训练检索器模块和语言模型,Atlas在广泛的知识密集型任务上具有强大的few-shot学习能力,包括NaturalQuestions、TriviaQA、FEVER、8个KILT任务和57个MMLU任务。
例如,Atlas在对64个例子进行训练时,在NaturalQuestions上达到了42%以上的准确率,在TriviaQA上达到了84.7%的准确率,与PaLM这个5400亿参数的模型相比,提高了近3个百分点,后者需要50倍的预训练计算。
作者还就训练这种检索增强模型时,哪些因素是重要的提供了详细的分析,并证明了Atlas的可更新性、可解释性和可控制性能力。
最后,作者证明了Atlas在全数据集设置中也很出色,在NaturalQuestions、TriviaQA、FEVER和5个KILT任务中都刷新了SOTA。




