【泡泡图灵智库】点云序列的语义分割数据集
泡泡图灵智库,带你精读机器人顶级会议文章
标题:A Dataset for Semantic Segmentation of Point Cloud Sequences
作者:Jens Behley, Martin Garbade, et al.
来源:arXiv [cs.CV] 2019
播音员:
编译:黄文超
审核:万应才
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是 —— A Dataset for Semantic Segmentation of Point Cloud Sequences,该文章目前发表于arXiv。
语义场景理解对于各种应用来说都很重要。特别地,自动驾驶车辆需要对其附近的建筑和物体具有细粒度的理解能力。激光雷达(LiDAR)提供有关环境的精确几何信息,因此是几乎所有自动驾驶车辆的传感器套件的一部分。尽管如此,但是目前仍缺少基于LiDAR的此任务的大型数据集。在本文中,作者引入了一个大型数据集来推动基于激光的语义分割研究。作者对KITTI Vision Odometry Benchmark的所有序列进行了标注,并为其激光雷达的360° FOV提供密集的逐点标注。作者基于该数据集提出了三个基准任务:(i)使用单次扫描对点云进行语义分割,(ii)使用由多次扫描组成的序列进行语义分割,以及(iii)语义场景补全,这需要预测未来时刻的语义场景。作者提供了baseline实验,并表明需要更复杂的模型来有效地完成这些任务。该数据集为开发更先进的算法打开了大门,同时也提供了大量数据来扩展新的研究方向。
主要贡献
• 提供点云序列的逐点标注数据集,其中包含的类别数和标注的详细程度都前所未见;
• 提供了对点云语义分割的最新方法的评估;
• 使用多次扫描研究了时序信息在语义分割中的应用;
• 基于移动车辆的序列标注,进一步引入了用于语义场景补全的数据集并提供基线结果;
• 与评测网站一起,发布了点云标记工具,使其他研究人员能够在将来生成其他标记数据集。
算法流程
SemanticKITTI 数据集
该数据集基于KITTI Vision Benchmark的odometry数据集,总共提供了23201帧用于训练,20351帧用于测试。总计类别数为28,其中6个类别具有是否正在移动的属性;另外引入了一个outlier类,用于弥补激光雷达的由于测量原因造成的错误数据。单帧的标注以及多帧融合的标注如图 1 所示。

图1 单帧(上)及多帧融合(下)标注
数据标注过程首先使用现成的SLAM系统[5]进行闭环和点云的配准、重建,确保地图的一致性。进而以100m×100m的大小划分区块,加载位于此区域内的多帧点云进行标注。整个数据集包含518个区块,历经超过1700小时的时间。图 2 展示了不同类别的分布情况,其与Cityscapes数据集的分布类似。

图2 标注类别分布
算法评估
1)单帧语义分割实验
算法的输入是一系列的3维点坐标及其反射强度,输出每个点的分类标签。评估指标为平均交并比(mIoU),如式(1)所示,其中C为类别。
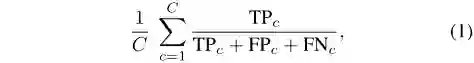
作者对6个算法进行了评估,分别为:PointNet[40],PointNet++[41],Tangent Convolutions[52],SPLATNet[51],Superpoint Graph[31] 和 SqueezeSeg[60]。另外对于最后一种算法,作者还评估了其改变骨干网络后的两种变体:Darknet21Seg和Darknet53Seg。
PointNet 和 PointNet++使用原始点云输入,算法的核心是一个最大池化操作,能够得到与输入顺序无关的输出结果。但是 PointNet 无法捕捉特征间的空间关系,PointNet++则弥补了这个缺陷。Tangent Convolutions也解决了非结构化的点云输入,直接在表面上进行正弦卷积。SPLATNet 采用了体素化的方法,将点云表示为高维稀疏的网格,由于体素化方法的时间和空间效率都不高,SPLATNet 使用双边卷积,只在有效的网格内进行计算。Superpoint Graph以局部几何一致性划分超点,用图结构来表示点云,比原始的表示方式更加紧凑和富有表达性。SqueezeSeg 则以球体投影的方式,把 3D 的点云转化为 2D 的图像,随后利用全卷积网络以及条件随机场来输出结果。由于 SqueezeSeg 算法性能较好且训练较快,作者又基于 Darknet 架构训练了两种SqueezeSeg的变体(骨干网络分别有21层和53层)以探究算法性能和模型参数数量的关系。
2)多帧语义分割实验
评估指标与单帧实验相同,但是算法可以利用过去时间内多帧点云,同时要求算法能够区分移动的对象。作者提供的baseline将连续的5帧融合成一帧,由于极大的数据量,作者仅对DarkNet53Seg和Tangent Convolutions算法进行了评估,因为它们能够不经过降采样处理大量数据,同时又能在合理的时间内完成训练。实验结果见表3。
3)场景补全实验
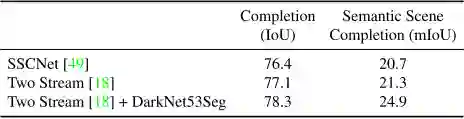
由于标注的序列特性,该数据集还可以用来进行3D语义场景补全如图 3 所示。车辆搭载的LiDAR行驶经过3D物体,由此记录到其背面的数据,而该信息在车辆刚驶向物体时是不可见的。作者评估了三种算法:SSCNet[49],Two Stream算法[18]和修改的Two Stream算法。实验结果见表4。
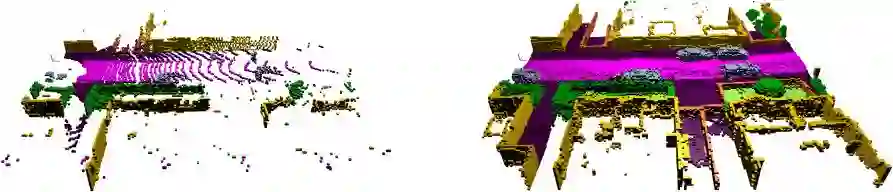
图3 场景语义补全。其中左侧为不完整
的点云输入,右侧为期望的补全的输出
主要结果
表1展示了单帧语义分割评估中各算法的结果,可以得出的结论是当前state-of-the-art的算法在大型、复杂的数据下性能均不佳。作者指出这主要的原因是所使用的网络架构的复杂性有限(如表2所示),因为这些网络的参数数量远小于当前用于图像语义分割的网络。作者训练了Darknet21Seg和Darknet53Seg来验证这个猜想,骨干网络复杂度的提升带来了精度从29.5%到49.9%的提升。其他可能的原因还有激光雷达生成的点云的稀疏性,以及遮挡问题对直接使用点云数据的算法的影响,在遮挡的情况下造成了物体表面的不连续。
表1 单帧语义分割结果
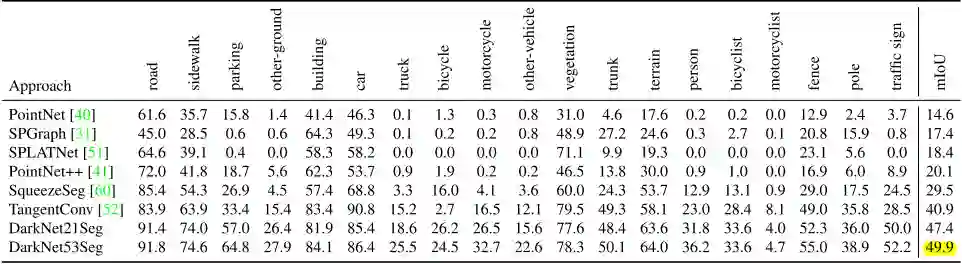
表2 单帧语义分割中各算法的参数
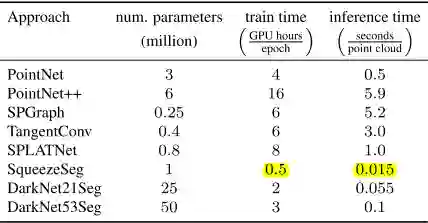
表3 多帧语义分割baseline结果
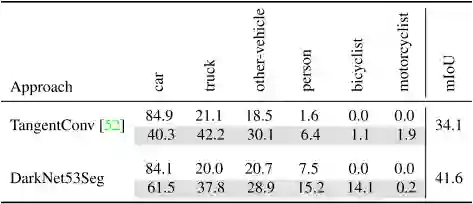
表4 场景语义补全baseline结果

Abstract
Semantic scene understanding is important for various applications. In particular, self-driving cars need a fine-grained understanding of the surfaces and objects in their vicinity. Light detection and ranging (LiDAR) provides precise geometric information about the environment and is thus a part of the sensor suites of almost all self-driving cars. Despite the relevance of semantic scene understanding for this application, there is a lack of a large dataset for this task which is based on an automotive LiDAR. In this paper, we introduce a large dataset to propel research on laser-based semantic segmentation. We annotated all sequences of the KITTI Vision Odometry Benchmark and provide dense point-wise annotations for the complete 360° field-of-view of the employed automotive LiDAR. We propose three benchmark tasks based on this dataset: (i) semantic segmentation of point clouds using a single scan, (ii) semantic segmentation using sequences comprised of multiple past scans, and (iii) semantic scene completion, which requires to anticipate the semantic scene in the future. We provide baseline experiments and show that there is a need for more sophisticated models to efficiently tackle these tasks. Our dataset opens the door for the development of more advanced methods, but also provides plentiful data to investigate new research directions.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




