ICCV 2019丨基于跨视角信息融合的三维人体姿态估计

编者按:现有的多视角三维人体姿态估计通常先估计二维人体姿态,再将二维提升为三维,因此一旦二维姿态估计不准确,将让三维姿态估计结果产生很大误差。为了进一步减小误差,微软亚洲研究院在 ICCV 2019 发表的一篇论文中,提出了基于跨视角信息融合的 3D人体姿态估计方法(Cross View Fusion for 3D Human Pose Estimation)。
三维人体姿态旨在从单目或者多目图像中恢复人体关键节点的三维坐标。在单目姿态估计中,因为信息不完备,算法通常只能恢复人体关键节点之间的相对位置,而无法获得在世界坐标系下的绝对坐标。为了解决这个问题,我们以多相机视角下的图片为输入,从而得到绝对的三维人体姿态。
现有的多视角三维人体姿态估计算法大多基于两阶段模型:第一阶段从图像中估计二维的人体姿态,第二阶段利用相机的参数信息,将二维姿态提升为三维。深度学习模型不断增强的表征能力在很大程度上推动了二维姿态估计的发展,从而也带来三维误差的不断下降。但是三维姿态估计仍然面临以下几个问题:
a) 二维姿态估计不准确:在真实世界的图像中,由于存在遮挡、自遮挡以及运动模糊等问题, 二维姿态估计的结果并不完美。
b) 三维姿态估计却严重依赖于二维姿态的准确度:由于三维姿态是从二维姿态中估计出来的,并且不会利用到图像信息,因此二维姿态的准确度会在很大程度上影响三维姿态估计的结果。
c) 从二维姿态恢复三维的方法大致可以分为两类:第一类使用三角化方法(Triangulation),它独立地估计每一个关键节点的三维位置。因为该方法不会利用到其他节点的信息,因此对于二维位置的精确度要求更高;第二类方法是基于图模型的方法(Pictorial Structure Model,PSM),它通过利用节点之间的关联信息(比如肢体长度等)使得当前节点的估计能够受益于相邻的节点。但该方法的缺点是需要对三维空间进行离散化,从而引入了不小的量化误差。
为了解决上述一系列问题,微软亚洲研究院提出了基于跨视角信息融合的 3D 人体姿态估计方法(Cross View Fusion for 3D Human Pose Estimation)。本方法首先建立了一个 CNN 网络,以多视角图片作为输入,能够融合其他视角信息到当前视角,从而能得到更加精准的 2D 姿态;再者,提出了递归图模型(Recursive Pictorial Structure Model,RPSM)来迭代地优化当前 PSM 所得到 3D 姿态,由粗略到细致,一步一步优化减少量化误差,来得到更加准确的 3D 姿态。
2D 姿态估计——多视角信息融合
整个框架结构如图1,蓝色框中的便是我们所设计的信息融合层。此信息融合是作用在 2D 姿态的 heatmap 上,即为每个视角图片的 heatmap,融合其他视角图片 heatmap 的信息,来达到纠正和增强当前视角 heatmap 的效果。
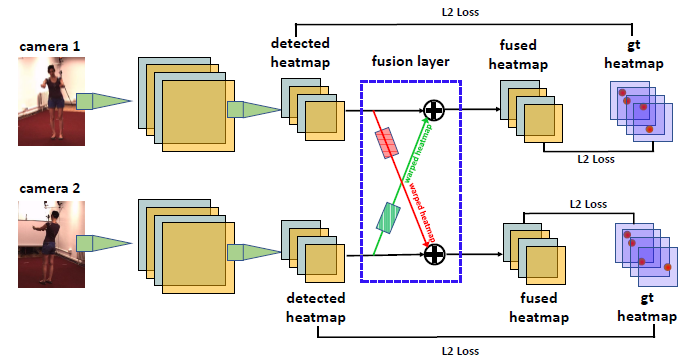
图1:2D 姿态估计网络框架
该方法的难点在于如何从不同视角之间去找到相对应的 feature,并将其融合起来。
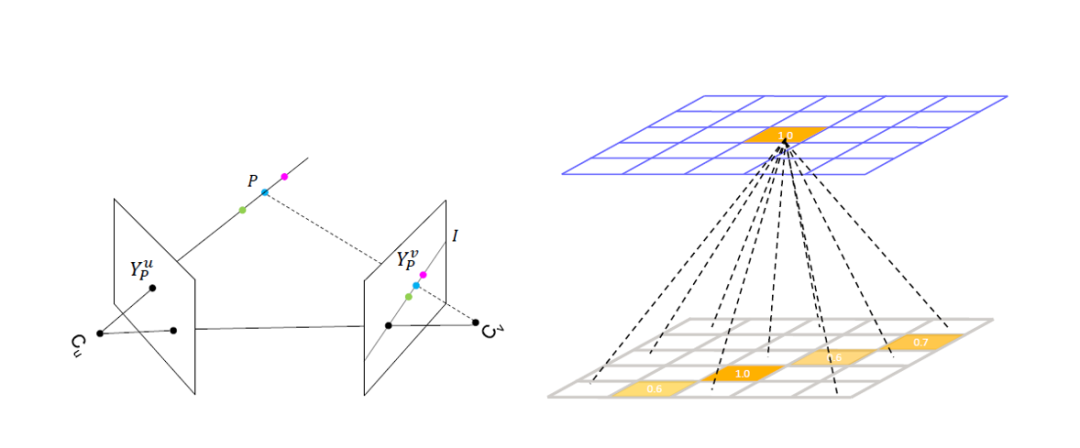
图2:Epipolar Geometry 以及 weight matrix 连接方式
受到 Epipolar Geometry 的启发(如图2左),当我们想增强视角 u 下 Y_P^u 该点的特征时,我们需要找到视角 v 下的 Y_P^v 点,并将其值拿出来做融合。但是由于只知道 2D 平面上的 Y_P^u,缺失深度信息,所以无法知道 Y_P^v 的具体位置,但由 Epipolar Geometry 可知,Y_P^v 必然在 Epipolar Line I(由 Y_P^u 确定)上。另外根据 heatmap 的特性,它在模型训练较好以后呈高斯分布,只有 Y_P^v 附近有高的响应,其他地方皆接近于0,因此我们可将该直线上所有点的值均融合过来。该操作可由一个全连接层来实现(如图2右),上方 heatmap 的每个 pixel,均由一个权值矩阵与下方 heatmap 所有 pixel 连接,只有那些在上方 pixel 所确定 epipolar line 上的下方 pixel 所对应的权值为正值,其他均为 0。我们在实验中对比了两种训练方法,一种是一直保持该线上 pixel 对应权值为正值,其他地方全部手动置成 0;一种是直接让这个权值矩阵根据数据集去自由学习,最后发现两者取得了相似的实验结果,最终我们文中的实验均采用第二种训练方法。
局限性及解决方法
由于我们的网络中,权值矩阵隐式地学习到了有关于当前相机摆放以及设置等信息,所以如此训练得到的模型不能直接用于其他不同设置的相机所拍摄的图片。于是我们提出了一种自动将模型转化到新环境下应用的方法,它不需要人工标注 2D 以及 3D 姿态。首先在 MPII 数据集上训练一个基于单目图片输入的 2D 姿态估计网络,用这个网络去估计在新环境下图片的 2D 姿态(会存在噪声以及不准确的情况),来作为近似 2D 姿态 ground truth。然后再用这些近似的 ground truth 训练我们文中的 2D 信息融合网络,实验部分评估了该方法。
3D姿态估计——RPSM迭代优化
我们把人体视作一个图模型(如图3左),先由 triangulation 得到 root 节点(即骨盆节点),由于该节点在任何视角均清晰可见,故而 2D 坐标十分精准,由 triangulation 得到的 3D 坐标也十分精准。再以该节点为中心,上下左右各 1m 形成解空间。将该解空间离散化成许多小网格,我们的目标就是确定不同的节点在哪些网格,再以网格坐标作为该节点坐标。
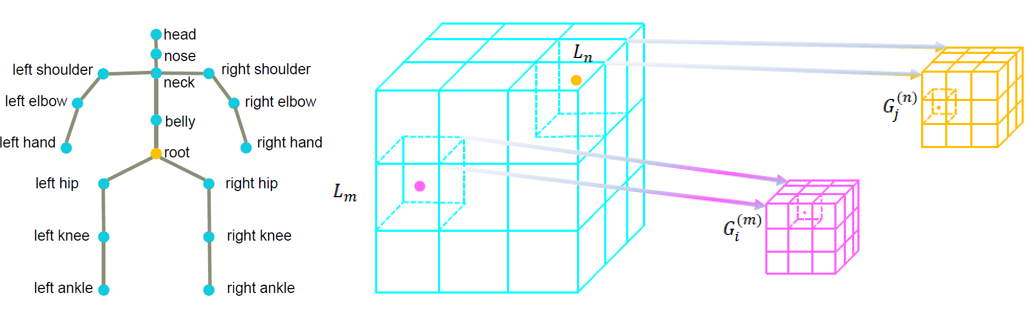
图3:人体图模型和进一步细分解空间
具体来说,将各个网格分别投影到不同视角下,得到对应的 heatmap 值,再结合人体骨骼的先验知识(即肢体长度约束),可用动态规划求解该问题。求解完成后,我们得到了一个粗略的 3D 人体姿态,我们继续在原有的网格里面进一步分出小网格(如图3右),再重复上述求解过程(值得注意的是此时相应肢体长度约束形式应做出相应改动),从而得到更精准的 3D 姿态。我们实验中均重复10次该过程可达到收敛,由于此过程中每次离散化均是2,故而求解过程十分之快。与原始的 PSM 相比,我们在得到更高精度结果下,增加的时间却十分之少。
数据集
主要实验的训练以及测试数据集为 H36M(Human3.6M),另外,部分实验中还加入了 MPII 作为训练集来增强网络,最后还在 Total Capture 数据集上进行了实验。
2D姿态估计实验
我们探究了不同视角信息融合的方法带来的实验效果(如表1),single、ours分别表示不使用、使用该信息融合层来进行不同视角信息融合,Sum 以及 Max 代表的是直接将相应 Epipolar line 上的值相加的和,以及从中取最大值来进行融合,可以看出我们提出的方法效果最好,所有类型节点的被检测率都得到了提高。尤其是像 Wrist(手腕节点)这种容易被遮挡住的,提升幅度最大。对比 Sum 及 Max,由于检测得到的 heatmap 通常包含一些噪声,我们所提出的信息融合层经过数据集的训练,对于这些噪声的泛化能力更强,故而能取得更好的效果。
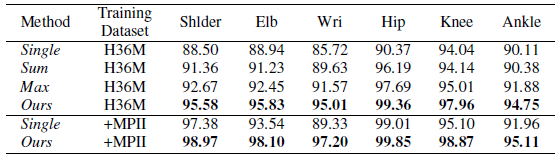
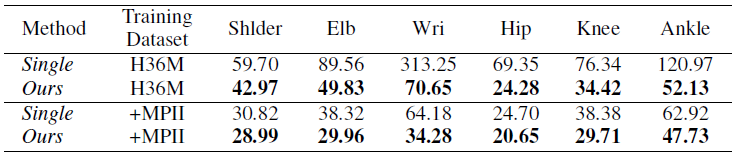
表1:上方为 2D 节点被检测到的概率,越大越好;
下方为 3D 节点在欧式空间的误差距离,越小越好
节点在某个视角下不可见时,我们通过融合其他可见视角下的信息来帮助其得到正确结果。可通过图4来感受利用其他视角信息帮助当前视角的情况。2D 结果带来的提升直接影响到 3D 结果,如表1下,所有节点误差距离均得到减小,像手腕、脚踝等困难节点,得到的提升非常大。

图4:利用其他视角信息帮助当前视角的情况对比
未通过信息融合与通过信息融合的姿态估计对比
3D姿态估计实验
我们做了大量实验,验证了我们提出的多视角信息融合以及 RPSM 的有效性。值得注意的是,以下表格中实验结果,都是没有用 Procrustes 来对齐模型检测结果和 ground truth 所得到的。
RPSM vs. Triangulation:首先,由于 RPSM 的迭代优化以及考虑了人体骨骼的先验知识,由表3可看出,在所有的实验配置下,RPSM 得到结果均比 Triangulation 要好;其次,当 2D 姿态检测模型精度不高时,RPSM 与 Triangulation 拉开了很大差距(47.82mm对比94.54mm)。而实际中的人体由于各种因素影响,其 2D 姿态估计的不准确十分常见,此时我们提出的 RPSM 更具有实用性。

表2:3D 姿态估计误差随着迭代优化次数的增加而减少
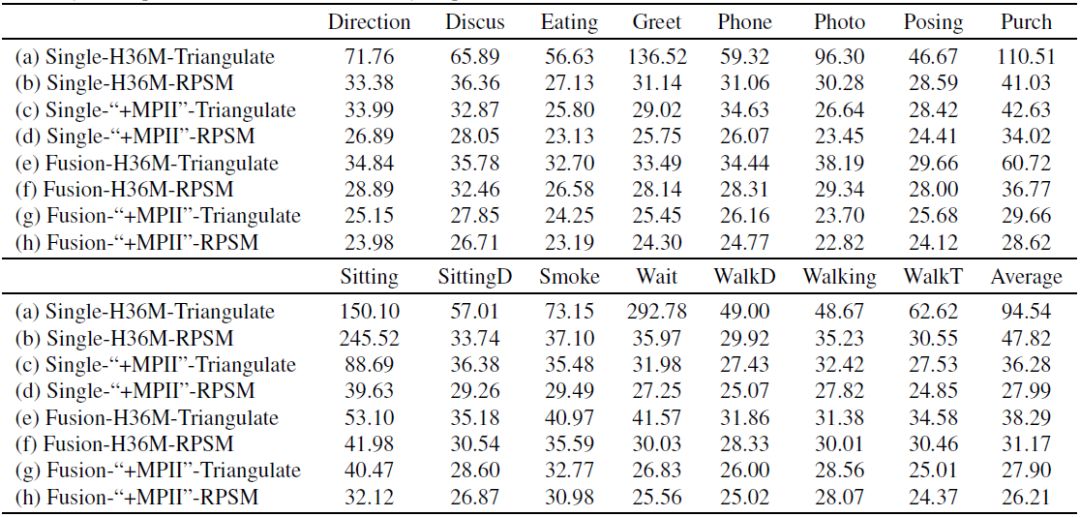
表3:不同方法下的 3D 姿态估计误差差异
RPSM vs. PSM:由表2可以看出,t=0 即 PSM,随着迭代优化次数的增加,误差逐渐较少,最终达到收敛。
Single vs. Fusion:由表3中 (a) (e),(b) (f),(c) (g) 对比可以看出,通过信息融合后所得到的结果均比未经过融合要好。而且对于困难的动作如“sitting”,对比(c) (g),可以看出多视角信息融合使得该误差由 88.69mm 降到了 40.47mm,由此可见我们方法的有效性。
Ours vs. State-of-the-arts:表4显示了我们方法与当前最好方法的比较结果,可以看出我们显著地降低了该误差,我们能实现的最好结果 26.21mm 更是比此前最好的 52.8mm 的一半还要小。
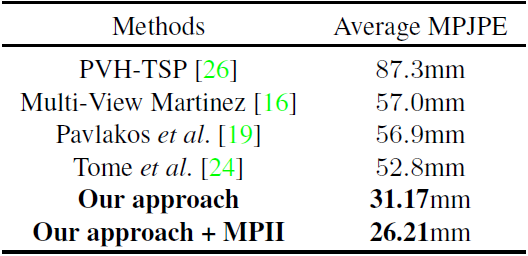
表4:我们方法与当前最好方法的对比结果
另外为了验证我们工作的泛化能力,我们还在 Total Capture 数据集进行了实验(如表5),我们同样取得了最好结果。
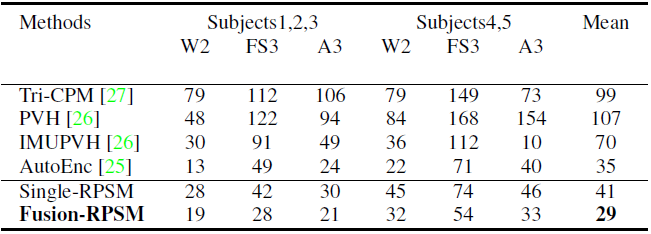
表5:Total Capture 数据集上的实验结果
泛化到新环境下的图片
我们用在不使用标注的 H36M 数据集下进行该实验,先在 MPII 上训练好一个基于单目图片的 2D 姿态估计网络,直接将其用于在 H36M 测试集得到 2D 姿态后,再利用 RPSM 得出 3D 姿态,其误差为 109mm。我们再以这些带有噪声的 2D 姿态作为近似的标注,训练我们上述提出的 2D 多视角信息融合的网络,是否进行融合的结果分别为 43mm 与 61mm,43mm 优于前文提到的目前最好方法结果。这些实验结果充分说明了我们方法的有效性,而且能够方便地运用到新环境中。
我们提出了多视角信息融合以及 RPSM 的方法,极大地提升了当前的实验结果。并且这两种方法是独立的,可十分方便地与现有的其他方法结合在一起。
本工作的相关源代码已经在 GitHub 上开源。点击阅读原文,即可访问 GitHub 主页。
GitHub 主页:https://github.com/microsoft/multiview-human-pose-estimation-pytorch
你也许还想看:




感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




