BiSeNet:双向分割网络进行实时语义分割
BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
ECCV2018
原文地址:https://arxiv.org/abs/1808.00897
一、语义分割
语义分割要解决的问题是,为一张图像之中的每个像素打上语义标签,也就是为每个像素分类,类别可能是行人、树木、道路等等。一般的分割数据库(例如Cityscapes,CamVid 和 COCO等)输入图片大小和图片场景都各不相同,包含的类别也都不同。
语义分割应用广泛,比如增强现实、无人驾驶、安防监控等,好的分割算法能实时并精确分割输入图片中的各类物体。


图1 语义分割实例
如上图,是一张图片进行语义分割后的结果。
Cityscapes:无人驾驶环境下的图像分割数据集。2975张精细标注的图像用来训练,500张精细标注的图像用来验证。BiSeNet中使用1525张图片来测试。此数据集中所有图片分辨率为2048*1024。每个像素都被标注为预先设定好的19个类别。
Camvid:共701张图片,367张用来训练,101张用来验证,233张用来测试。此数据集中所有图片分辨率为960*720。包含11个预先设定好的语义类别。
COCO-Stuff:2017新版COCO,提供了一个新的接口,来对同一个类别涂色。共164000张图片,其中118000张用来训练,5000张用来验证,20000张用来测试平均水平,20000难度稍大的用来挑战。此数据集中图片分辨率不一,包含91个确定类和1个不标注类。(类似图1下图中绿色部分不涂颜色,还是原来的草地)
二、实时语义分割面临的问题
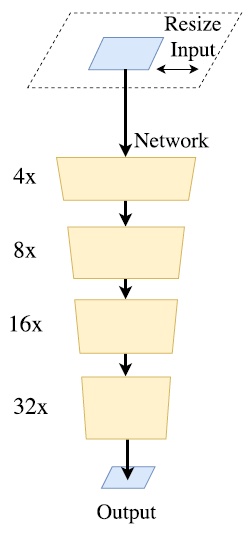
通过剪裁或 resize 来限定输入大小,以降低计算复杂度,来达到实时。尽管这种方法简单而有效,空间细节的损失还是让预测打了折扣,尤其是边界部分,导致度量和可视化的精度下降;(图2、3、5中橘色方块长度代表了空间分辨率、厚度代表了通道数量)
图2 resize加速
通过减少网络通道数量加快处理速度,尤其是在基本模型的早期阶段,但是这会弱化空间描述力;
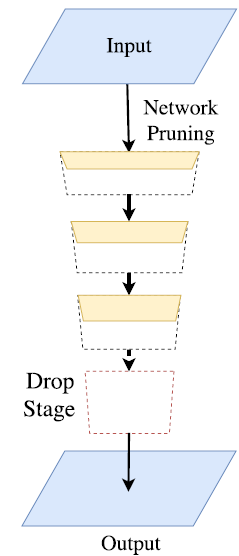
为追求极其紧凑的框架而丢弃模型的最后阶段---下采样阶段。该方法的缺点也很明显,模型的感受野不足以涵盖大物体,导致判别能力较差。
图3 轻量级模型drop最后下采样阶段(感受野太小)
所谓空间信息丢失,就是在图像不断被卷积、下采样的过程中,尺寸越来越小,原图中空间细节信息将越来越少,因为图像分辨率越来越小。
所谓感受野,就是神经网络某层输出的feature map的某个节点对应原输入图像的感受范围的大小。每个feature map的感受野大小都与它之前每层的卷积核大小及卷积的步幅有关系。
在分割任务中,普遍认为感受野越大,分割效果越好。若网络未经过足够的下采样操作,也就是卷积层不够多,网络不够深,获得的feature map中某节点的感受野不够大,直观的讲,可能无法涵盖大物体,一般的讲,还是网络不够深获得的feature map不具有足够的语义判别能力(与空间判别能力不同)。但网络一旦变深,就会丢失空间细节信息,并且在上采样恢复的过程中增加计算量同时丢失信息。因此空间细节信息和大感受野的具有强判别力的语义特征在算法实时的要求下很难兼得。
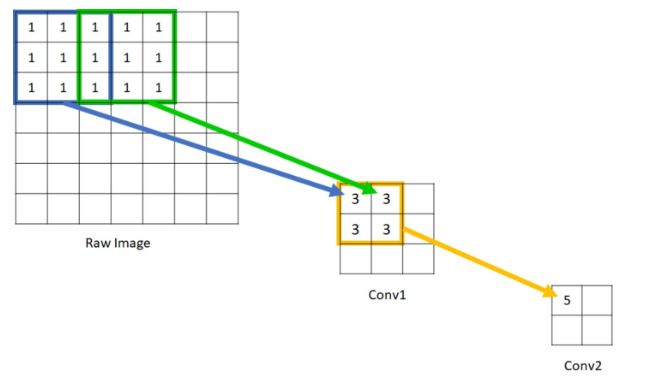
图4 感受野计算示意图
上述三个问题都说明现在的实时语义分割算法都在牺牲精度以求速度,为了解决上述问题,一般的语义分割算法总通过下面几种操作来增加空间信息和扩大感受野:
研究者广泛使用U型结构(跳层连接/skip-connection),融合分层特征来弥补丢失的空间信息,如图5。
图5 U型结构网络示意图
扩张卷积(膨胀卷积/空洞卷积),通过给卷积核一个膨胀率来扩大感受野,同时保持参数数量不变。下图中(a)卷积核感受野为9,(b)卷积核感受野为49,(c)卷积核感受野为225。
图6 扩张卷积
金字塔型池化模块,下图中,取原输入图像到达conv5的feature map来进行空间金字塔池化,其实就是用不同大小的池化窗口和步长,对feature map进行池化操作,获得不同尺寸的池化视图,然后将得到的结果连接起来,获得一个固定大小的特征向量。而且这一步不管输入的feature map大小如何,最后获得的特征向量都是固定维的,只要合理设定池化窗口和步长就可以了。
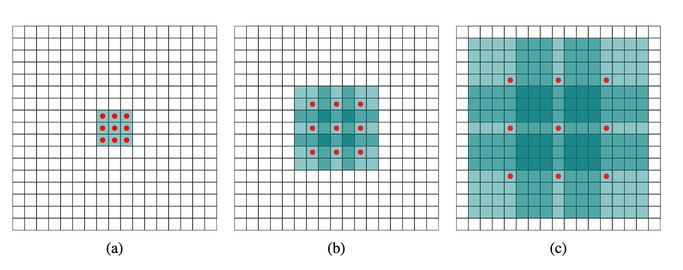
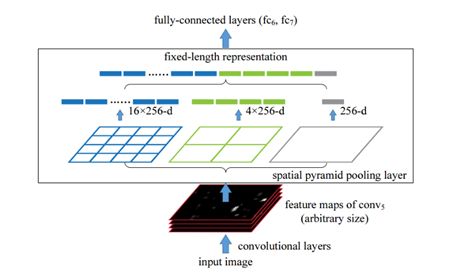
图7 空间金字塔池化
但是这样做都有明显的缺点:一是U型结构中对浅层高分辨率的特征图进行了更多的不必要的计算,拖慢了速度;二是因为resize或减少通道丢失的空间信息,不是简单通过结合浅层特征就能复原的;三是扩张卷积有些像素信息没有利用上,这对像素级的分割是很不好的。虽然扩大了感受野,但是对小物体分割效果下降;四是空间金字塔池化操作计算量大,拖慢分割算法的速度。
三、BiSeNet网络结构概述
BiSeNet网络以获得一个实时的语义分割算法为目标,尽量获取丰富的空间信息和更大的感受野,获得更准确的预测结果。
BiSeNet概括来说包含两路分支,Spatial Path (SP) 和 Context Path (CP)。分别来解决空间信息缺失和感受野不够大的问题。BiSeNet借助 U 形结构融合两分支最后两个阶段的特征,但这不是一个完整的 U 形结构。图8展示了此网络的整体结构。
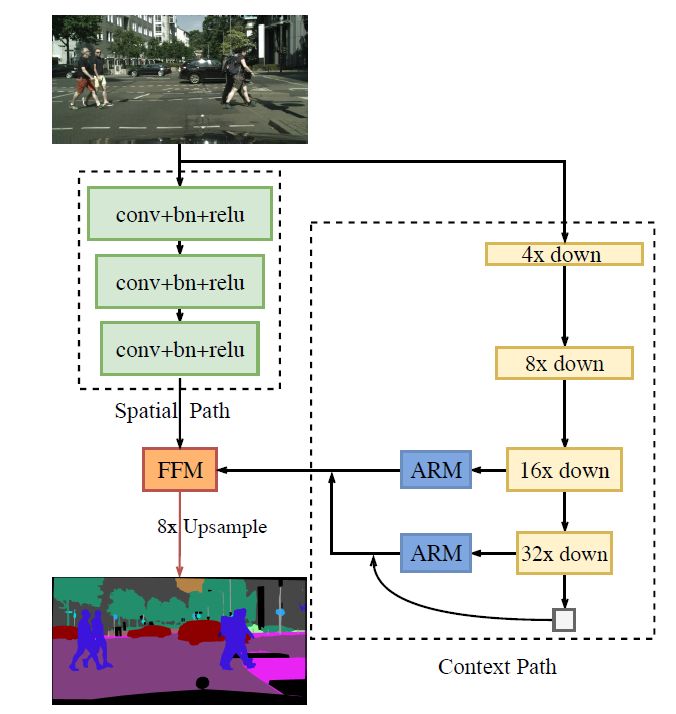
图8 BiSeNet网络结构图
SP分支:只包含三层卷积层,最后得到1/8的特征图,这样能保留图片丰富的空间信息。为什么这么说,因为每经过一次卷积,相当于对图片进行了一次下采样操作,卷积层越多,卷积操作越多,得到的特征图越小,将损失图片的空间信息。
CP分支:在可以快速下采样特征图的Xception模型尾部增加一个全局平均池化层,通过全局语境信息来获得最大的感受野。
FFM和ARM:分别是特征融合模块和注意力增强模块。FFM为了融合两路特征,ARM模块用来增强最后的预测的准确性。
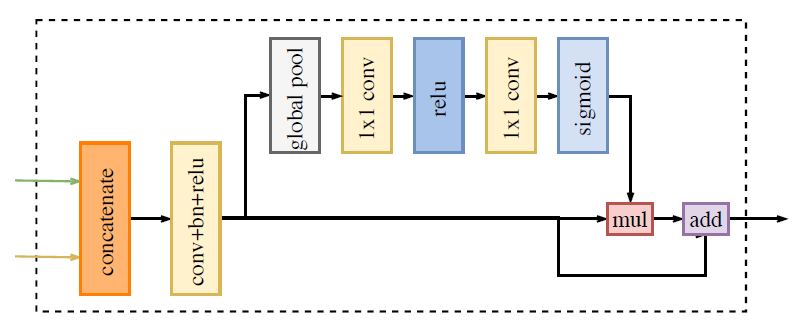
图9 Feature Fusion Module
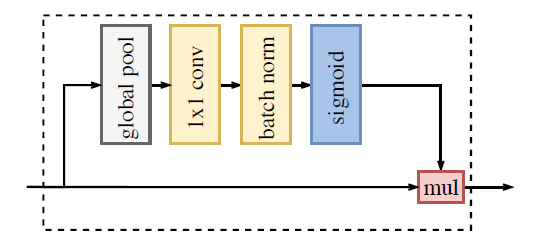
图10 Attention Refinment Module
四、Spatial path (丰富的空间信息)
如图8所示,SP分支只包含三层,其中每一层包含:
步幅为2的卷积层;
批归一化层:批归一化操作是为了使样本遵循均值为0,方差为1的分布。这样可以加快优化过程中寻找最优解的收敛速度。(具体过程包括求此批数据均值、求此批数据方差、进行归一化、将函数值通过参数映射到相应区间。);
ReLU层:ReLU激活函数,f(x)=max(0,x);
最后得到一个原图1/8大的高分辨率的特征图,因为卷积的少,属于浅层的特征,但包含丰富的空间信息。虽然得到的特征图是高分辨率的,但因为只有三层,所以计算负担也不大。
五、Context path(快速获得大的感受野)
如图8所示,在选择的轻量级模型(本文中选择的是Xception模型)尾部加上一个全局平均池化层(ARM模块),获取最大感受野。
Xception模型:能进行快速下采样,加快计算速度,并得到高层语义特征。
全局平均池化:相当于在一个W*H*C的特征图上进行W*H大小的取平均的池化操作,最后归一化得到一个1*1*C的权重向量。
ARM模块:如图10所示,在进行了全局平均池化操作后,可以直接得到一个整合全局信息的向量,快速获取最大的感受野,无需在Xception模型的结果上进行任何上采样操作。ARM模块的计算负担可以忽略不计。
这里对Xception模型进行介绍,Xception模型是Google继Inception模型后推出的,使用了depthwise separable convolution(深度可分离卷积)在参数数量差不多的情况下,对比前模型有了明显的提速。原始的InceptionV3主要设计动机如图11所示,是为了使网络自己学到好的特征,将图11中的四种特征提取方式concat起来获得输入图片的特征。

图11 InceptionV3
经过简化,变成了图12中的形式:
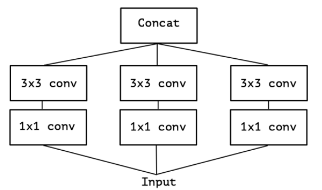
图12 InceptionV3简化形式
图12又等价于图13的形式,也就是输入进行1*1卷积核降维后,使用三个3*3卷积核,每个卷积核卷积一部分(1/3channels)1*1卷积核处理的结果:
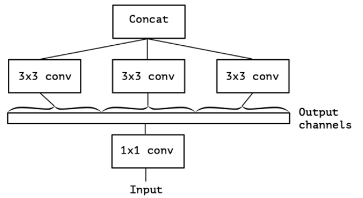
图13 InceptionV3等价形式
图13的极端情况,即对1*1卷积核的卷积结果,每个通道都使用一个3*3卷积核进行处理:
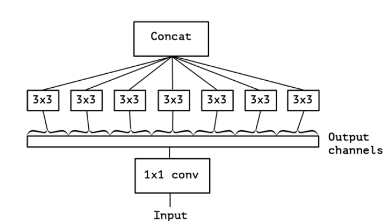
图14 极端情况
这里就可以推出深度可分离卷积结构了,也就是说原来的Inception模型的操作是先进行1*1卷积再分通道分别进行3*3卷积的,并且1*1卷积后有一个ReLU激活层。而现在可以变为先给每个通道都分配一个3*3卷积核进行卷积,再使用1*1卷积核进行卷积(降维)。推广来讲,假设原始特征有M个通道,那么:
先使用M个3*3的卷积核分别对每个通道进行卷积;
再使用N个1*1卷积核对步骤1的处理结果进行卷积;
得到通道数为N的特征。
两个模型最大的差别就是Xception使用了深度可分离卷积结构。在Xception原论文中有实验对比,这样进行特征提取(下采样)非常快。而本算法BiSenet采用的Xception39结构是Xception模型中最轻量级的一种。下面附一张Xception网络结构图。
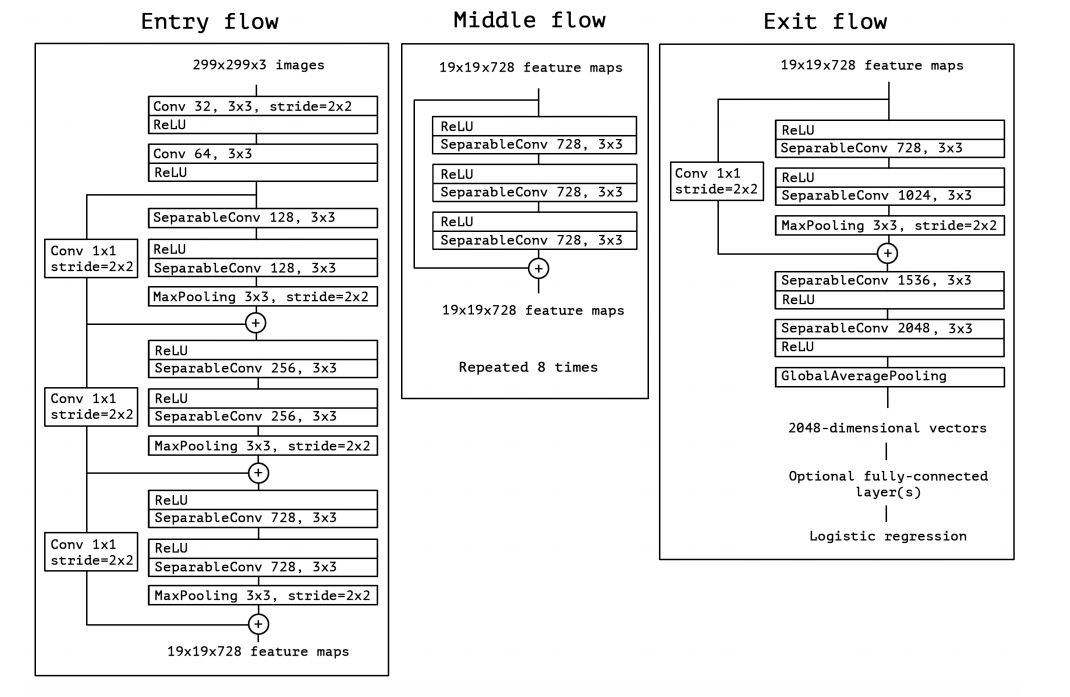
六、Feature fusion module(特征融合模块/FFM)
上述SP和CP分支的特征图因为是不同层的特征,所以不能直接相加融合。对于SP分支的特征图来说,是浅层的、包含丰富空间信息的特征;对于CP分支的特征图来说,是深层的、包含丰富上下文信息的特征。对两部分特征进行融合的网络如图9所示,具体步骤为:
连接两部分特征;
对连接后的特征进行批归一化,平衡两者的尺度;
全局平均池化2步骤处理后的特征,得到特征权重向量,这个特征权重向量意味着对连接后的特征图进行一个特征选择和结合的操作;
使用3步骤得到的权重向量与1步骤得到的连接后的特征相乘;
利用4步骤得到的特征与1步骤的到的特征相加,得到融合后的特征。
七、网络整体分析
速度方面:
尽管SP得到的特征图具有高分辨率,但SP分支只有三层,因此计算负担不大;
CP分支使用在ImageNet上预训练过的轻量级模型Xception进行快速下采样,速度很快,并且ARM模块并不增加什么计算负担;
SP和CP分支是同时计算的。
精度方面:SP分支得到的特征图丰富了特征的空间信息,CP分支得到的特征图具有更大的感受野,两者相辅相成,提高了预测的准确度。
八、损失函数
使用一个辅助损失函数用来训练,一个主损失函数用来检测整个网络的输出。另外有辅助损失函数用来监督CP分支的训练,类似深层监督,也就是网络某阶段输出作为一个独立的网络输出,反卷积到label尺寸大小,求得损失,所有阶段的损失加权求和再求最小。深层监督模式有利于更快收敛、减轻梯度消失和爆炸的问题以及求得更小的损失。
所有损失函数都是softmax损失函数:
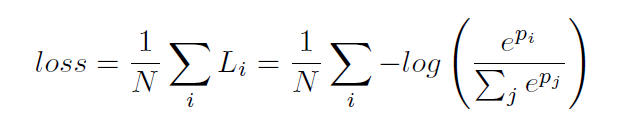
其中p是网络输出的预测结果。另外还设计了一个连接损失函数,通过一个权值α平衡主、辅损失函数,以更好的优化,本方法中α=1:

此连接辅助函数L只在网络训练时使用,其中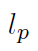
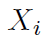
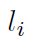
九、实验细节
网络结构:使用Xception39模型;
训练参数:使用带mini-batch的随机梯度下降算法优化,batch size为16;使用一种变化的学习率
,power初始化为0.9,学习率初始化为2.5exp-2;
数据:随机剪裁到某固定大小去训练。
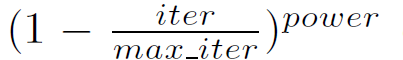 ,power初始化为0.9,学习率初始化为2.5exp-2;
,power初始化为0.9,学习率初始化为2.5exp-2;十、实验结果
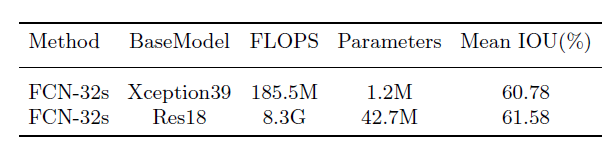
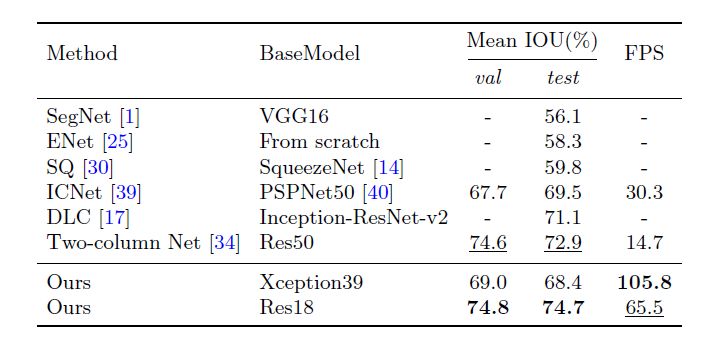
baseline(Cityscapes数据集):使用预训练的Xception39模型,然后将融合后的特征直接上采样到和原输入图像一样大,下表还包含需要的操作数及参数数量作为baseline
验证U模型有效性:还是选择Xception39模型作为骨干模型,但U-shape-8s只使用最后两阶段输出;U-shape-4s为标准U型结构所有层输出都使用
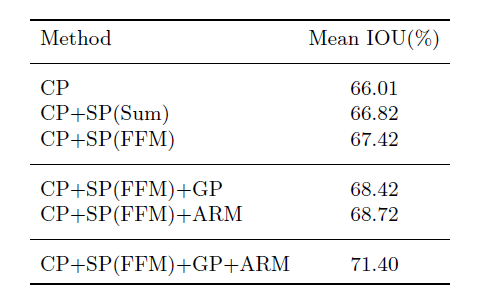
验证CP、SP、GP(global average poling)、ARM、FFM模块有效性:
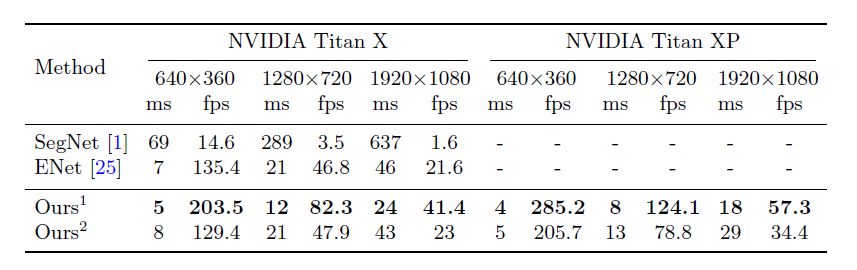
速度(三个数据集)与精确度:下表中1是使用Xception39做基础模型,2是使用Res18做基础模型。还使用了两种硬件环境来测试。

Xception:Deep Learning with Depthwise Separable Convolutions
CVPR 2017
原文地址:https://arxiv.org/pdf/1610.02357.pdf


