全景分割这一年,端到端之路
机器之心原创
作者:朱艳芳
编辑:邱陆陆
图像分割(image segmentation)任务的定义是:根据某些规则将图片分成若干个特定的、具有独特性质的区域,并提出感兴趣目标的技术和过程。
目前图像分割任务发展出了以下几个子领域:语义分割(semantic segmentation)、实例分割(instance segmentation)以及今年刚兴起的新领域全景分割(panoptic segmentation)。
而想要理清三个子领域的区别就不得不提到关于图像分割中 things 和 stuff 的区别:图像中的内容可以按照是否有固定形状分为 things 类别和 stuff 类别,其中,人,车等有固定形状的物体属于 things 类别(可数名词通常属于 things);天空,草地等没有固定形状的物体属于 stuff 类别(不可数名词属于 stuff)。
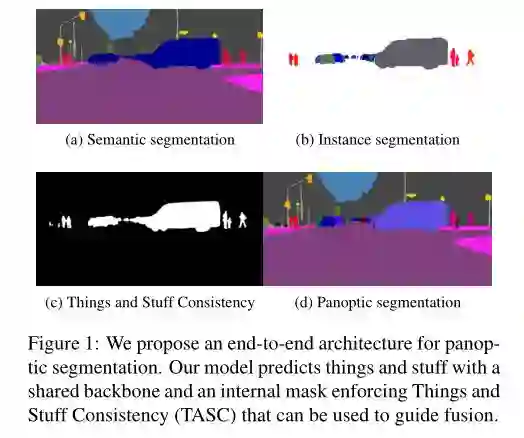
语义分割更注重「类别之间的区分」,而实例分割更注重「个体之间的区分」,以下图为例,从上到下分别是原图、语义分割结果和实例分割结果。语义分割会重点将前景里的人群和背景里树木、天空和草地分割开,但是它不区分人群的单独个体,如图中的人全部标记为红色,导致右边黄色框中的人无法辨别是一个人还是不同的人;而实例分割会重点将人群里的每一个人分割开,但是不在乎草地、树木和天空的分割。

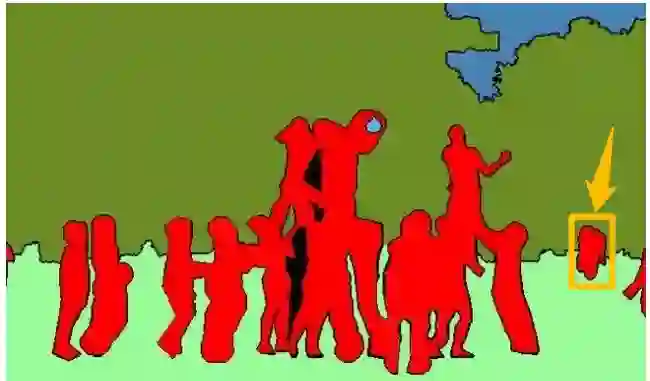
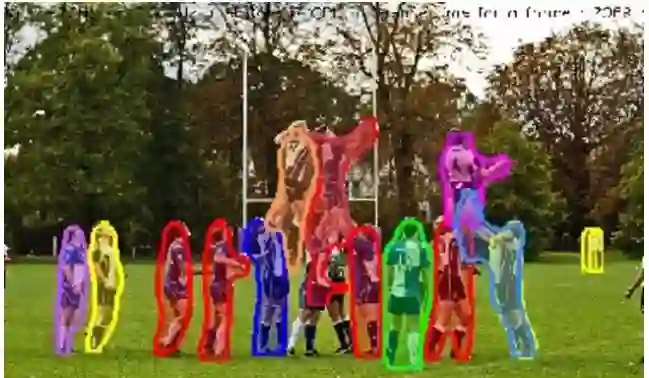
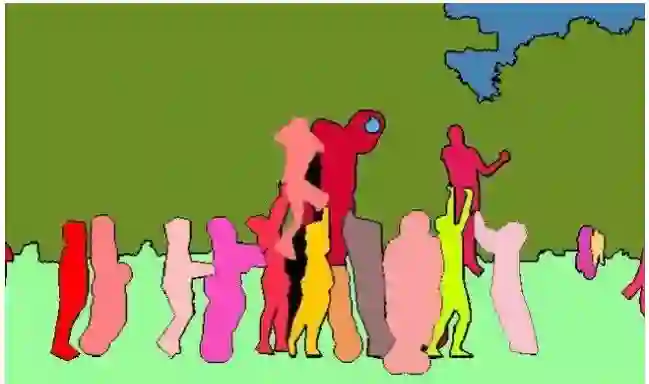
全景分割可以说是语义分割和实例分割的结合,下图是同一张原图的全景分割结果,每个 stuff 类别与 things 类别都被分割开,可以看到,things 类别的不同个体也被彼此分割开了。
目前用于全景分割的常见公开数据集包括:MSCOCO、Vistas、ADE20K 和 Cityscapes。
COCO 是微软团队公布的可以用来图像 recognition、segmentation 和 captioning 的数据集,主要从复杂的日常场景中截取,主要有 91 个类别,虽然类别比 ImageNet 少很多,但每一类的图像很多。
Vistas 是全球最大的和最多样化的街景图像数据库,以帮助全球范围内的无人驾驶和自主运输技术。
ADE20K 是一个可用于场景感知、分割和多物体识别等多种任务的数据集。相比于大规模数据集 ImageNet 和 COCO,它的场景更多样化,相比于 SUN,它的图像数量更多,对数据的注释也更详细。
Cityscapes 是一个包含 50 个城市街景的数据集,也是提供无人驾驶环境下的图像分割用的数据集。
链接如下:
COCO: http://mscoco.org/
Vistas: https://blog.mapillary.com/product/2017/05/03/mapillary-vistas-dataset.html
ADE20k: http://groups.csail.mit.edu/vision/datasets/ADE20K/
Cityscapes:https://www.cityscapes-dataset.com/
对于语义分割和实例分割任务,现在已经有了一些效果很好的模型,为研究者熟知的有语义分割的 FCN、Dilated Convolutions、DeepLab、PSPNet 等,实例分割的 SDS、CFM、FCIS、Mask R-CNN 等,而全景分割作为一个今年刚出现的概念,目前的相关研究仍然屈指可数。
今年一月,为了找到一种能将 stuff 和 things 同时分割开的算法,Facebook 人工智能实验室(FAIR)的研究科学家何恺明和他的团队提出了一个新的研究范式:全景分割(Panoptic Segmentation,PS),定义了新的评价标准。
全景分割概念的提出:如何同时分割 stuff 和 things?

论文地址:https://arxiv.org/abs/1801.00868
何恺明这篇开创新领域的论文的主要创新包含以下两点:
① 将语义分割和实例分割统一起来提出新的领域:全景分割;
② 定义新的评价指标。
针对语义分割和实例分割这两个单独的任务来说,现有一些专门的评价指标。
而作者认为没有使用一个统一的指标(将这两个任务联合起来的评价指标)是研究者们通常孤立地研究 stuff 和 thing 分割的主要原因之一。因此,定义了一个新的评价指标 panoptic quality (PQ) metric,来评价全景分割算法的好坏,PQ 的计算方式为:
给定 TP(样本为正,预测结果为正)、FP(样本为负,预测结果为正)和 FN(样本为正,预测结果为负),则 PQ 的定义为:
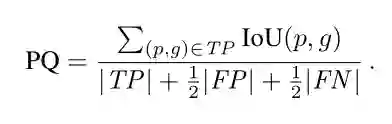
其中 p 表示预测的 segment,ɡ表示 ground truth。
在这篇开创性的文章中,作者并没有提出关于全景分割的新算法,只是定义了新的问题,文章中关于全景分割的效果是通过将语义分割(PSPNet)与实例分割(Mask R-CNN)的结果联合在一起得到的。作者只是定义了一个基于规则的将二者的预测结果结合在一起的方法。最后,文章还给出了两个潜在的研究方向为后面的研究者提供参考,一是研究端到端的全景分割模型;二是研究如何更好的将语义分割与实例分割模型结合的算法。
JSIS-Net:端到端的尝试
今年 9 月,埃因霍芬理工大学的团队使用共享的特征提取器,提出了联合语义与实例分割来得到全景分割的方法(a Joint Semantic and Instance Segmentation Network , JSIS-Net)。

论文地址:https://arxiv.org/abs/1809.02110
该网络的结构图如下:
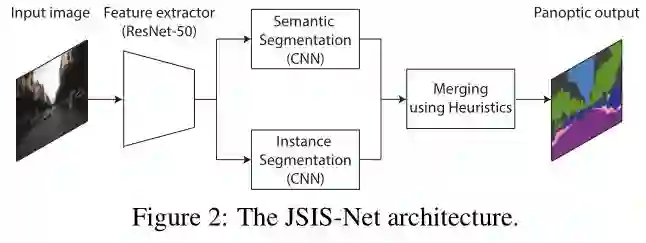
该算法与何恺明团队的做法是类似的,都是将语义分割与实例分割模型结合得到全景分割结果,只不过两个模型采用共享特征提取器来提取特征,并且进行联合训练。基本网络结构采用 ResNet-50,将提取到的特征同时输入到语义分割和实例分割分支中,在语义分割分支中,首先采用 PSPNet 中的金字塔池化模块产生特征图,然后采用混合上采样方法将预测的结果调整到输入图像的大小;实例分割分支中采用的是 Mask R-CNN,最后也将这两个模型得到的结果结合在一起得到全景分割的结果。
在将语义分割与实例分割的结果结合的过程中,有以下两个问题需要解决:
一是:由于全景分割任务要求所有的分割结果都不能有重叠,所以如何处理实例分割结果产生的重叠是首先需要解决的问题,即对于一个处于两个物体交叠部分的 things 类的像素来说,可能有来自实例分割模型的两个实例 id 标签,那么这时这个像素应该分配给谁?
二是:在将语义分割与实例分割的结果联合的过程中,由于 stuff 的分割只有来自语义分割的预测,而对 things 的预测,语义分割和实例分割两部分都能产生预测,所以对于一个 things 类别的像素来说,可能有来自语义分割和来自实例分割模型的两个标签,那么当对这种情况两个模型预测产生冲突时该如何如何解决?
对于第一个问题,何恺明团队的做法是采用一种类似非极大值抑制的算法(NMS-like)将重叠的分割结果去除掉;而埃因霍芬理工大学团队的做法是计算重叠部分的像素属于各个实例的概率,并将其分配给那个概率最高的实例。
对于第二个问题,如果产生预测冲突,何恺明团队的做法是将此标签分配给 things 标签及其对应的实例 id,而埃因霍芬理工大学团队的做法是,首先将语义分割结果中得到的 things 类都删除掉,并且用语义分割结果预测的最有可能的 stuff 类代替它们,这样就使得语义分割的结果只有 stuff 类,然后用实例分割的 things 类的结果来替换语义分割结果中属于 things 类的像素。
JSIS-Net 的主要贡献在于,应用端到端学习的思想来联合进行语义分割和实例分割预测,从而最终预测全景分割输出。作者在最后的结论中表明这种网络虽然可以 work,但是效果比何恺明团队提出的基本方法的效果还差。
如何在没有足够的全景分割标注数据的情况下,习得全景分割模型
今年 11 月份,牛津大学的团队提出了弱监督全景分割模型:

论文地址:https://arxiv.org/abs/1808.03575
code 地址:https://github.com/qizhuli/Weakly-Supervised-Panoptic-Segmentation
这是首个利用弱监督方式训练得到全景分割效果的模型,文章中也没有提出新的关于全景分割的模型,采用的模型是《Pixelwise Instance Segmentation with a Dynamically Instantiated Network》论文中的模型,网络结构如下:
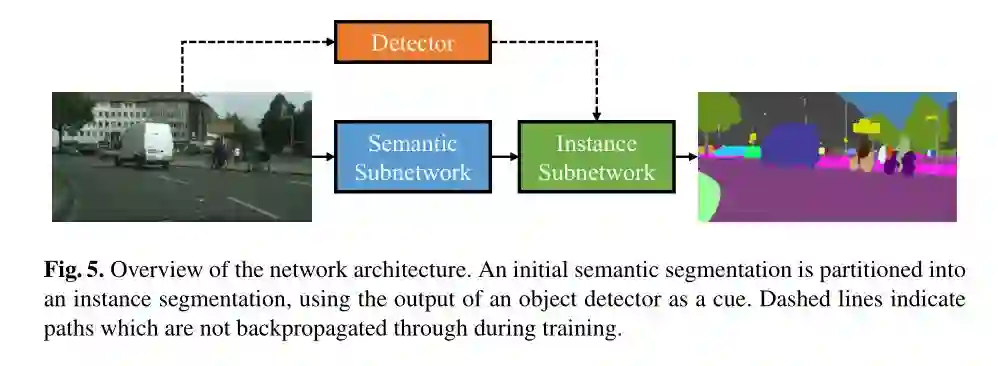
这篇文章的主要特点如下:
① 对于仅有 bounding boxes 注释的图像,也可以将图像中的 stuff 类和 things 类很好的区分出来。
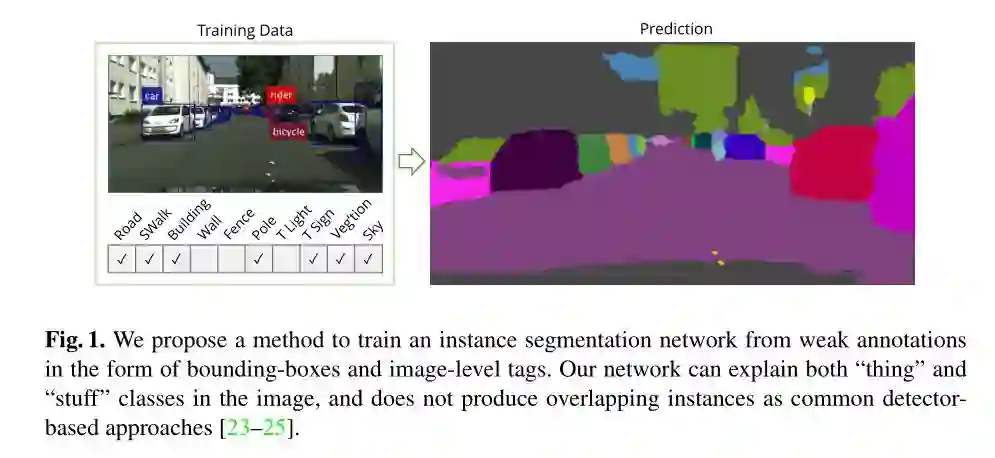
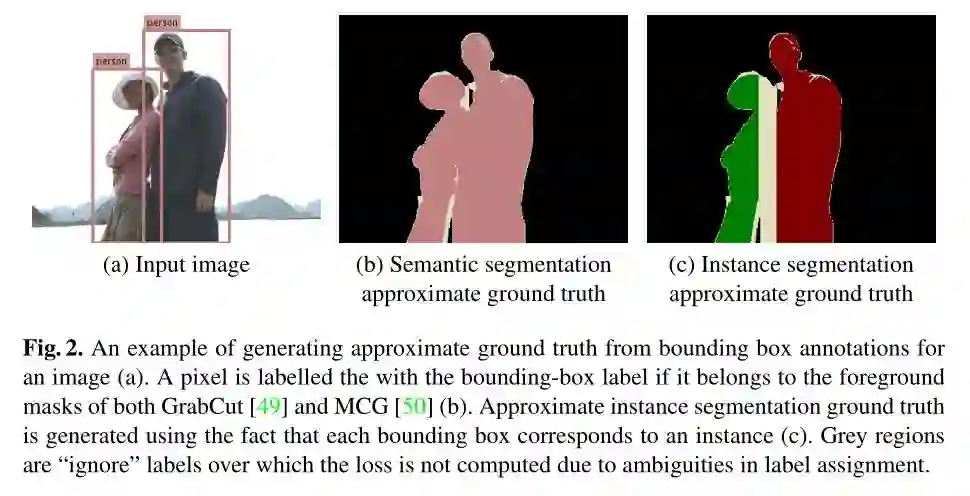
② 对于上面提到的全景分割得到的 segments 不能有重叠的问题,这篇论文很好的解决了此问题,它不会预测出任何的 overlap,其解决办法是:对于图像中的所有像素,在没有可靠注释的情况下,该模型首先采用弱监督(weak supervision)和图像先验(image priors)来使图像中像素的一个子集去逼近 ground-truth,然后,使用这个像素子集的估计标签来训练网络。逼近 ground-truth 的方法是:只对那些确定的像素分配标签,并将剩余的像素集标记为「忽略」区域。
TASCNet:端到端实现
12 月份,丰田研究院也提出了端到端的全景分割模型 TASCNet:

论文地址:https://arxiv.org/abs/1812.01192
这篇文章针对何恺明提出的两个研究方向都进行研究,既设计了一个 end-to-end 的全景分割模型,也提出了一个新算法可以更好的将语义分割与实例分割模型结合。网络结构如下:
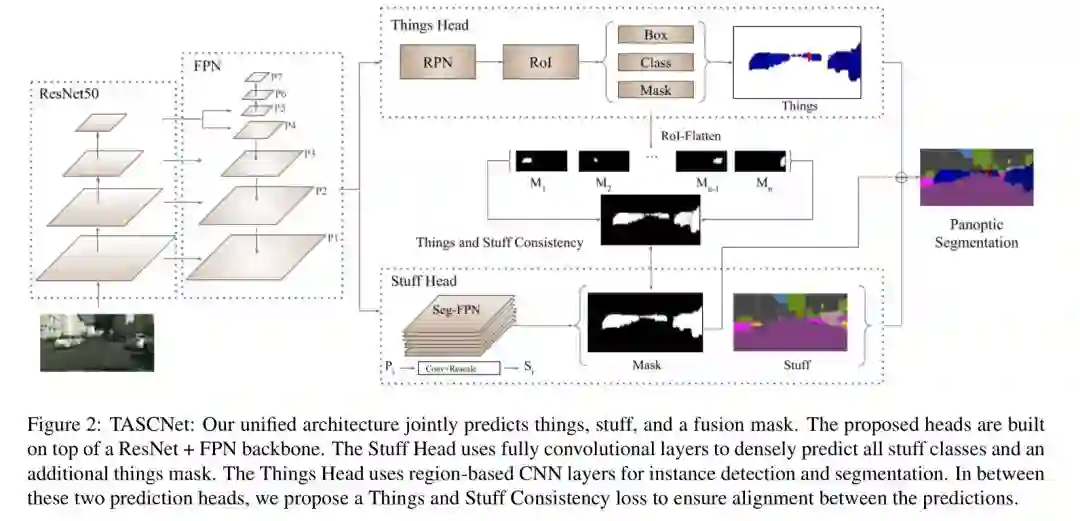
和所有的网络一样,TASCNet 也用了深度网络提取特征,它使用的是 ResNet-50 和 FPN 作为 backbone,使用 FPN 能够从 backbone 网络的更深处捕获低级特征,这样可以识别更多的对象。
这篇文章的创新主要在于它提出了一个新的算法(Things and Stuff Consistency, TASC),用于在训练过程中保持语义分割和实例分割这两个子任务的输出分布之间对齐(alignment)。作者认为虽然语义分割与实例分割这两个分支都使用的是同一个 backbone 网络训练得到的特征,但是由于这两个任务在注释上的细微差别以及其他因素的影响,会使得这两个分支 drift apart,而全景分割的任务是使得全局最优,所以采用 TASC 算法来使得两个任务更好的融合。
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



