论文浅尝 | Multilingual LAMA: 探索多语言预训练语言模型中的知识

笔记整理:谭亦鸣,东南大学博士生
来源:EACL‘21
链接:https://aclanthology.org/2021.eacl-main.284.pdf
概述
本文关注将语言模型(LM)视作一个知识库,然后用于解决例如句子填空这样的NLP任务,这个做法在单语言(英语)取得了不错的效果。因此在这篇论文里,作者着重关注了以m-BERT为代表的多语言语言模型是否也能作为多语言KG适用于多语言NLP场景。他将单语LAMA数据集翻译为53种语言,并使用m-BERT作为知识库进行了实验评估,着重关注了m-BERT的可用性,和在不同语言上的性能差异性。从实验效果来看,首先m-BERT在部分语言上能够实现和单语LAMA实验类似的效果,另一方面,m-BERT虽然基于104weikipedia训练得到,但是依然存在语言偏置
背景与动机
单语上,使用预训练模型作为知识库(不做微调的情况下)来完成一些自然语言处理任务例如简单的文本生成,模板填空等,已经被证明是有效的。既然LAMA在英语但遇上已经取得了许多研究进展,作者对多语言预训练模型上是否也同样有效产生好奇,论文主要围绕三个问题进行展开:
1.M-BERT是否也能被当作一个多语言知识库来使用,这对于方法发展的多样性和可用性非常重要2.M-BERT作为知识库是否在不同语言上有性能差异,或者它不受语言不同的影响3.M-BERT相比单语模型包含了更多语言(104种)的训练数据,这些是否会在性能上带来额外的影响
贡献
作者总结论文的主要贡献如下:
1.论文建立了一个多语言版本(覆盖53种语言)的TREx以及GooleRE2.提出了一种“实体类型+模板”的模式替换传统“挖空查询”,并证明它具有更好的效果3.实验论证了M-BERT在不同语言上回答查询的性能差别明显4.论文论证了M-BERT作为知识库应用时存在语言偏向,例如当查询由意大利语构成,那么查询得到的实体往往也是意大利语的5.跨语言池化预测能够大幅提升实验性能,甚至优于英语单语BERT
数据
作者沿用了LAMA的做法,也使用了TREx以及GoogleRE这两个数据集,两者都是由三元组构成。LAMA的思路是使用模板直接在预训练模型种查询三元组的内容,例如对于三元组(巴黎,首都,法国),查询模板为:巴黎是___的首都。
TREx涵盖34,039个三元组,涉及41种关系类型,GoogleRE则包含5528三元组以及3种关系,每个关系对应的模板都是由人工制作的。
在LAMA的基础上,作者使用谷歌翻译将其模板翻译为其他语言,通过确定模板插槽是否被准确保留来验证翻译的准确性,并在必要的部分进行后处理修正。
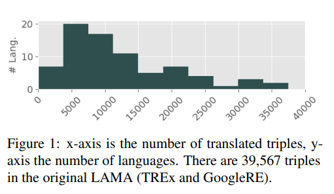
M-BERT支持104种语言,谷歌翻译覆盖了其中的77种,维基百科和谷歌知识图谱都没有支持所有语言的实体翻译,并且也不是所有实体都被包含在知识图谱中。对于英语,作者找到共计37,498个三元组。平均下来,34%的三元组可以被翻译。最终构建得到mLAMA,其统计信息如图1。
实验
作者在实验中验证了两种查询构建模式:
1.沿用Petroni等人的做法,使用带有插槽的模板例如:巴黎是___的首都2.增加对于插槽实体的类型约束,从而解决部分歧义问题例如:汤姆出生在_____,插槽处即可能是地点,也可能是年份,添加类型约束解决了这个问题。
对于插槽本身,作者分析了两种情况:
1.限定插槽为单个token,反应在模板上就是 “汤姆出生在[_____]”2.设置插槽为多个token,即 “汤姆出生在[__][_]” 多个插槽的情况下,生成过程可以描述为连续的条件概率如下:
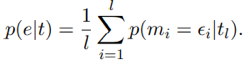
其中,e是实体,t是构成e的token序列
主要实验结果:

OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。



