论文浅尝 | 问题多样性对于问答的帮助
笔记整理 | 毕胜 东南大学在读博士,研究方向:自然语言处理 知识图谱

问题生成通过生成一些合成的问题作为训练语料有效提高了问答系统的效果,本文的研究点是:在QG中,生成问题的文本多样性是否对下游的QA有帮助?

直观上来看,多样的问题确实是能够提升QA的效果。
背景
现有QG大部分采用beam search试图产生多样性的问题,同时采用如BLEU、ROUGE等metric作为评估方式。这样做存在两个问题:1、BLEU、ROUGE这类评估方式都倾向于让生成的结果与Ground Truth (GT)更加相似,而多样性是希望生成的结果和GT更加不同,这两个指标的趋势是相反的;2、我们希望对于一个答案有更多的标注数据,这样就能模型学习生成更多的多样性问题,但是通常没有足够的标注数据。
于是,作者希望提出一种新的metric,既能够使得生成的问题准确、又兼具多样性。在此之前,作者做了大量的实验,来验证多样性对于下游任务QA的重要性。
方法
方法上,作者并没有太多的创新,直接使用了RoBERTa进行Fine-Tuning,inference时采用了top-p nucleus sampling[1]。其实还有很多种采样方式,作者认为NS有效、简单、速度快。Top-p nucleus sampling (NS@p),简单来说,就是从nucleus N中采样词。
以一个例子来说明:假设词典中存在1k个词,p设置为0.5,在每一个时间步,通过softmax我们会得到一个词分布,我们从中选取一个最小的子集(在实验部分,作者说明这个自己的最大数量为20),满足:(1)、子集中的词的概率和大于p;(2)、在所有满足条件(1)的子集中,其概率最大:
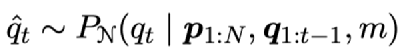
与top-k采样相比,通过将采样池限制在词汇表的一个更大可能性区域,当原始分布在一个或几个项目达到峰值时,NS减少了生成低概率词的可能性。
实验
首先,在SQuAD1.0 上,对比了beam seach(b=5)和NS@p的结果,p=0.1,0.5,0.75,0.95。对比的评估指标包括 BLEU-1, ROUGE-4,METEOR。同时,还对比了将该生成结果用于QA 模型(基于BERT)的fine-tuning,得到的QA模型在测试时的F1值,以此来对比不同方式生成的问题对于QA的提升程度。实验使用的数据量分别为原始training data的5%,20%,50%,100%。采用的RoBERTa分别为base和large。一共进行了四组实验,每组训练10个模型。
如上图,绿色代表每个指标中最优结果,红色代表最差结果。可以看出:尽管beam search在不同数据量的训练中,所有QG metrics都高于NS@p的方式,但是在QA的表现上,只有在数据量为5%时高于NS@p。上述实验对于每个答案只生成一个问题,作者还增加了一个实验,在RoBERTa-large,数据量100%,p=0.95,每个答案生成5个问题时,QA F1=86.4。
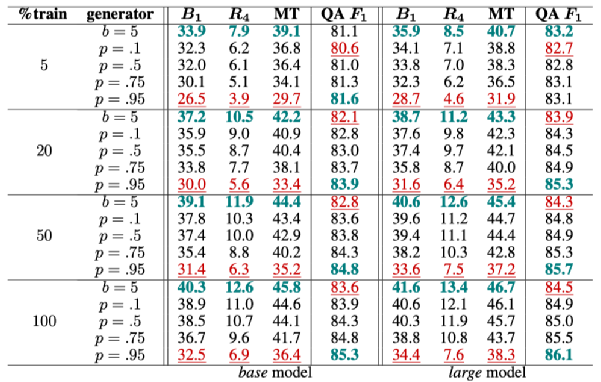
其次,作者增加了四组实验,这四组实验是将上面训练好的模型,直接对NewsQA的数据进行测试(zero-shot),结果如下图:
结论与前面的实验类似。随着p的提高,BLEU、ROUGE的值越低,意味着问题的多样性越大,同时,QA F1随之升高。
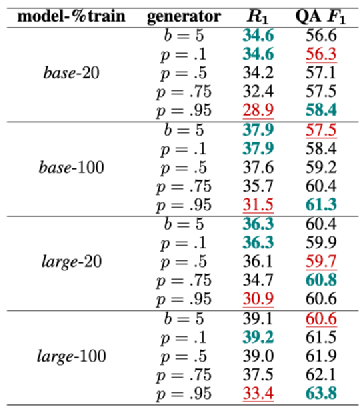
最后,文章对比了生成的问题和GT对于QA系统的效果。作者采用上述最好的QG模型(large-100%-NS@0.95),来对比手动标注的结果,即GT。实验结果如下图:
可以看出,在SQuAD上,GT的效果86.3略高于SYNTH(合成问题)86.1,但是当使用该模型对每个答案生成5个问题时,其QA F1达到了86.4,高于GT。将合成结果和GT合并后,其效果1+1>2。在NewsQA也出现类似的结论。
通过上面三次实验可以看出,(1)、多样性QG确实能够提升QA的训练;(2)、总是生成类似的问题(beam seach)用处很小;(3)、常用的QG meitrics并不足以评估生成的问题对于QA模型训练的有效性。
因此,作者探索了新的QG评估方式。
新的指标
通过前面的实验可以看出,现有的metrics并不充分,因为它们只关注和GT有关的准确性。作者提出两个metrics:
Accuracy:类似于语言模型的困惑度评估,在时间步t,给定标准答案和前t-1步的标准结果,把生成正确词汇的概率当作时间t的准确率,最后求均值作为当前整个问题的Accuracy P(GT)。
Diversity:衡量问题多样性最符合直觉的方式就是评估所有时间步生成的词的平均熵,但是首先熵是一个无界度量,另一点就是它和Accuracy的趋势是相反的。也就是说,需要存在一种度量方式,在Accuracy提高的同时,Diversity也是提高的。回到前面的实验数据,通过观察可以发现,对着p的增大,多样性也随之提升,subset N也是增加的,因此,标准词(GT)在N中的概率也增加了。由于GT是否在N中是一个bool值,因此统计全部时间步GT在N中的概率。
综上,最后的metric为:
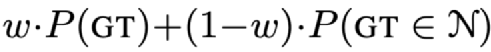
w∈[0,1],是一个微调参数。
结论
整体来说,本文论证了问题多样性对于QA模型训练的重要性,通过实验证明了top-p的采样方式在QG中的有效性,同时通过实验提出了一个新的metric。
文章还是挺有意思的,但是存在一些疑问。首先文章没有做case study,我们也看不出生成的问题到底长什么样子,通过BLEU、ROUGE来看,可能效果不是很好,存在语法、逻辑错误等问题。如果QG的目的不是为了提升QA那么将会有很大问题。当然,作者题目中也说明了for QA,也没啥好说的。但即便如此,如果生成的问题很糟糕,这些实验就变成地一种数据增强,按照这种思路,不考虑生成问题的可读性、语法、语义等,直接进行数据增强是不是也能达到类似的效果呢?上述实验中对于QA的提升到底是来源于问题的多样性还是来源于BERT呢?
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


