<论文分享> NLP领域最新论文分享-1123

分享一些笔者最近看到的一些NLP相关的论文,简要对摘要做了翻译,文末附下载链接,需要的朋友自取。
Streaming Graph Neural Networks
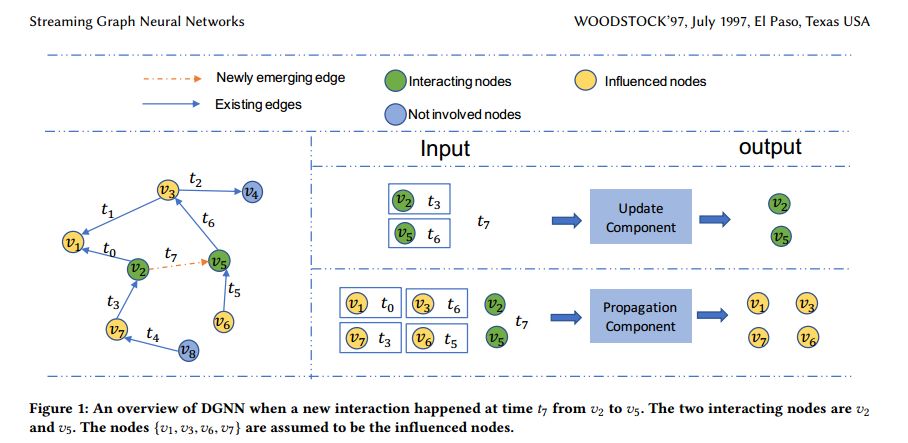
摘要:图是许多真实世界数据的基本表示,如社交网络。近年来,人们越来越努力将神经网络模型扩展到图形结构数据。这些通常被称为图神经网络的方法已经被用于推进许多与图形相关的任务,例如物理系统的推理动力学、图形分类和节点分类。大多数现有的图神经网络模型都是为静态图形设计的,而许多真实世界的图形本身就是动态的。例如,随着新用户的加入和新关系的建立,社交网络自然会不断发展。目前的图神经网络模型不能利用动态图形中的动态信息。然而,动态信息已经被证明可以提高许多图形分析任务的性能,例如社区检测和链接预测。因此,有必要为动态图设计专用的图神经网络。在这篇论文中,本文提出了一种新的动态图神经网络模型(Dynamic Graph Neural Network model)DGNN,它可以随着图的发展来模拟动态信息。特别地,所提出的框架可以通过捕获edge的顺序信息(交互)、edge之间的时间间隔和信息的连贯传播来保持更新节点信息。对各种动态图的实验结果表明了所提出框架的有效性。
Reversible Recurrent Neural Networks
摘要:递归神经网络( RNN )在处理顺序数据方面提供了最先进的性能,但是训练起来需要大量内存,限制了训练RNN模型的灵活性。可逆RNNs(hidden-to-hidden的转换可以反向的RNNs)提供了一条降低训练记忆需求的途径,因为隐含状态不需要存储,而是可以在反向传播期间重新计算。本文首先展示了完全可逆的RNNs,它不需要存储隐含层的激活,从根本上来说是不合理的,因为它们不能忘记隐含状态的信息。然后,本文提供了一个存储少量信息的方案,以便实现带遗忘的完美反转。本文的方法实现了与传统模型相当的性能,同时将activation memory成本降低了10 - 15倍。将本文的提出的技术扩展到基于注意力的序列对序列模型,在这种模型中,获得了相同的性能,同时在编码器中将activation memory成本降低了5 - 10倍,在解码器中降低了10 - 15倍。
Compositional Language Understanding with Text-based Relational Reasoning
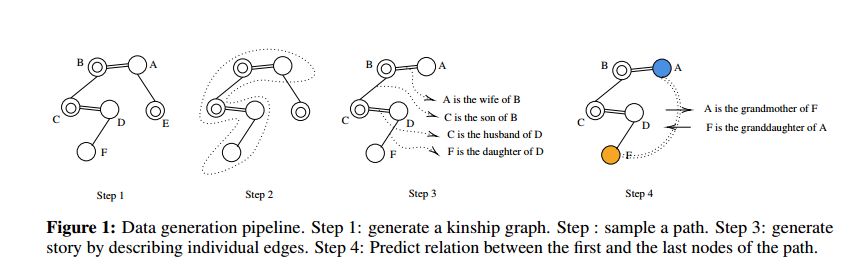
摘要:用于自然语言推理的神经网络在很大程度上侧重于提取、基于事实的问答和常识推理。然而,理解神经网络在多大程度上可以从自然语言中执行关系推理和combinatorial generalization也是至关重要的,这些能力常常被标注技术和标准QA中语言建模的优势所掩盖。在这项工作中,本文提供了一个新的语言理解基准数据集,它隔离了关系推理的性能。本文还提出了一个神经信息传递的baseline,并表明与传统的递归神经网络方法相比,该模型结合了关系归纳偏差(relational inductive bias),在combinatorial generalization方面性能更优。
Dynamic Meta-Embeddings for Improved Sentence Representations
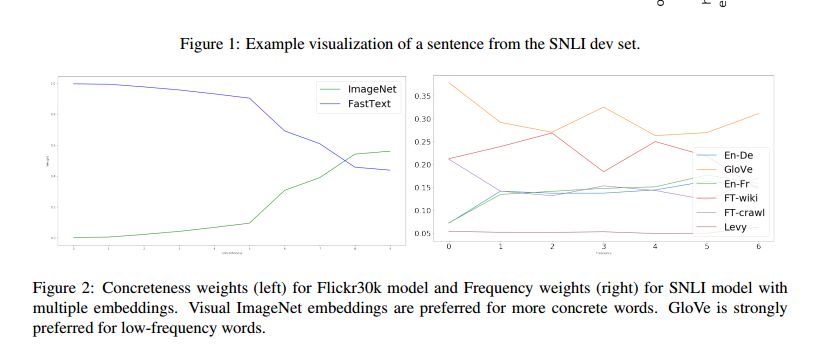
摘要:许多NLP系统设计的第一步是选择使用那种已经预训练好的embedding,但本文认为这个步骤最好留给神经网络自己去学习。为此,本文引入了Dynamic Meta-Embedding,这是一种简单而有效的Embedding集成监督学习方法,促进各类模型在同类模型中获得了state-of-art的结果。本文随后展示了该技术揭示word embedding在NLP系统中的一些新用法。
Embedding Logical Queries on Knowledge Graphs
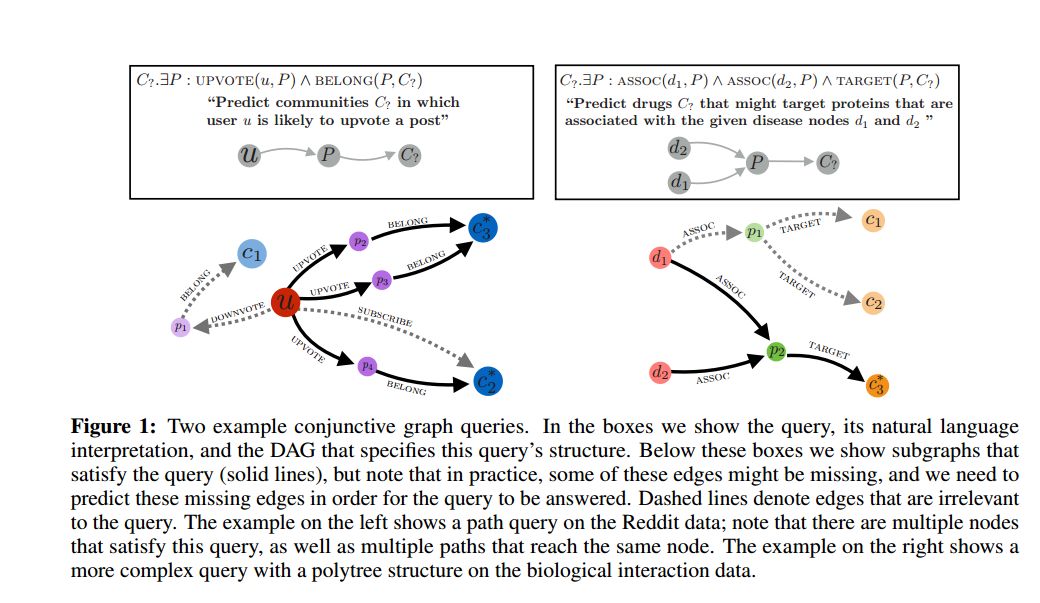
摘要:可以将知识图谱当做一张图,学习实体低纬度embedding,并将其应用于预测实体之间未观察到的或缺失的边。然而,这一领域的一个具有挑战性的问题是如何超越简单的边缘预测,处理更复杂的逻辑查询,这可能涉及多个未观察到的边、实体和变量。例如,给定一个不完整的生物知识图谱,我们可能想预测哪些药物可能靶向与X和Y疾病相关的蛋白质?这是一个需要对所有可能与X和Y疾病相互作用的蛋白质进行推理的查询(Query)。在这里,本文引入了一个框架,以便在不完整的知识图谱上有效地对连接逻辑查询(一阶逻辑f(first-order logic)的一个灵活但易处理的子集)进行预测。在本文的方法中,本文在低维空间中对图形节点embedding,并在这个embedding space中将逻辑运算符表示为学习过的几何运算(例如平移、旋转)。通过在低维embedding space中执行逻辑运算,与基于简单枚举的方法所需的指数复杂性相比,本文的方法实现了线性时间复杂性的变量查询。本文展示了这一框架在对现实世界数据集的两项应用研究中的结果,这两项研究涉及数百万种关系:预测药物-基因-疾病相互作用网络中的逻辑关系,以及来自流行网络论坛的基于图表的社会相互作用表示。
Deep Learning for Generic Object Detection: A Survey
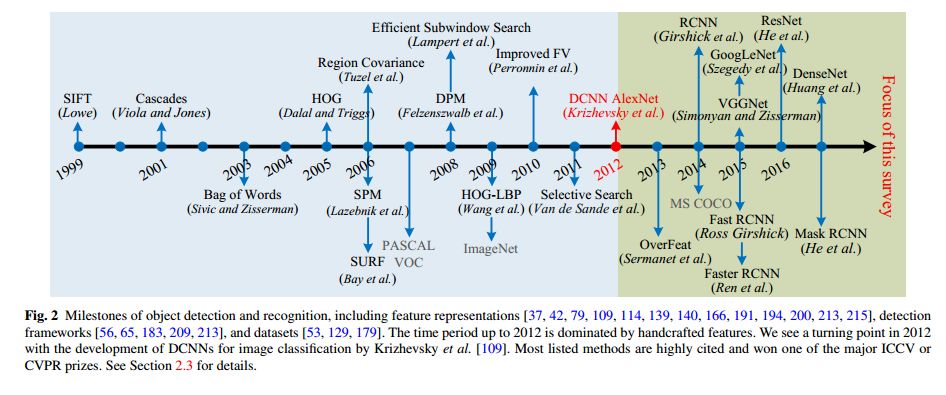
摘要:通用目标检测旨在从自然图像中的大量预定义类别中定位对象实例,是计算机视觉中最基本和最具挑战性的问题之一。近年来,深度学习技术已经成为直接从数据中学习特征表示的有力方法,并在通用对象检测领域取得了显著突破。考虑到这个快速发展的时代,本文整理了深度学习技术在这个领域所带来的最新成就的全面综述。这项调查包括了250多项关键贡献,涵盖了通用目标检测研究的许多方面:领先的检测框架和基本子问题,包括目标特征表示、目标提案生成、上下文信息建模和训练策略;评估问题,特别是基准数据集、评估指标和最新性能。最后,本文确定了未来研究的有希望的方向。
Learning Sequence Encoders for Temporal Knowledge Graph Completion
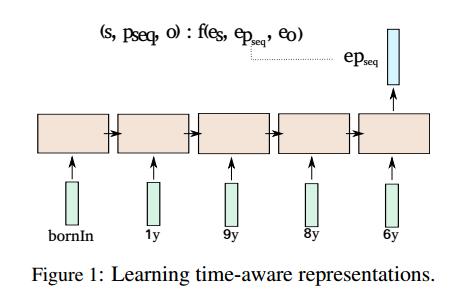
摘要:知识图谱中链接预测的研究主要集中在静态多关系数据上。在这项工作中,本文考虑了时间知识图谱,其中实体之间的关系可能只保持一个时间间隔或特定时间点。根据以往关于静态知识图谱的工作,本文建议通过学习潜在实体和关系类型表示来解决这个问题。为了整合时间信息,本文利用递归神经网络来学习关系类型的时间感知表示,这可以与现有的潜在因子分解方法结合使用。该方法被证明对实际的KG中常见的挑战:时间表达式的稀疏性和异构性,具有鲁棒性。实验显示了本文的方法在四个时间(temporal)KGs上的优势。
Deep learning for time series classification: a review
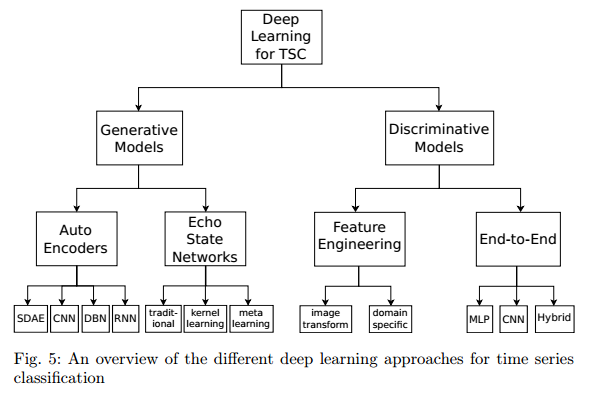
摘要:时间序列分类(Time Series Classification, TSC )是数据挖掘中的一个重要而富有挑战性的问题。随着时间序列数据可用性的提高,已经提出了数百种TSC算法。在这些方法中,只有少数考虑使用深度神经网络来完成这项任务。这令人惊讶,因为在过去几年里,深度学习得到了非常成功的应用。DNNs的确已经彻底改变了计算机视觉领域,特别是随着新型更深层次的结构的出现,如残差和卷积神经网络。除了图像,文本和音频等连续数据也可以用DNNs处理,以达到文档分类和语音识别的最新性能。在本文中,本文通过对TSC最新DNN架构的实证研究,研究了TSC深度学习算法的最新性能。在TSC的DNNs统一分类场景下,本文概述了各种时间序列领域最成功的深度学习应用。本文还为TSC社区提供了一个开源的深度学习框架,实现了本文所对比的各种方法,并在单变量TSC基准( UCR archive)和12个多变量时间序列数据集上对它们进行了评估。通过在97个时间序列数据集上训练8730个深度学习模型,本文提出了迄今为止针对TSC的DNNs的最详尽的研究。
Joint Multilingual Supervision for Cross-lingual Entity Linking
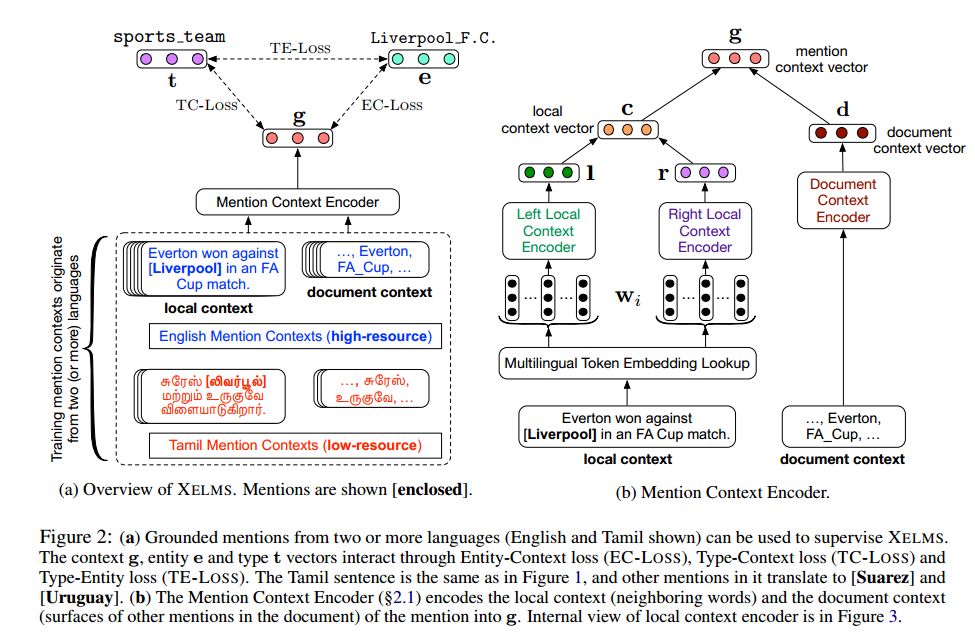
摘要:跨语言实体链接(Cross-lingual Entity Linking,XEL )旨在将以任何语言写的entity mention引向英语知识库(KB),如维基百科。XEL对大多数语言来说都很有挑战性,因为监督资源(resource as resource)有限。本文通过开发一种XEL方法来应对这一挑战,该方法将多种语言的supervision结合在一起。这使得本文能够: ( a )通过高资源语言(如英语)的额外监督,强化目标语言的有限监督;( b )为多种语言训练单一实体链接模型,改进每种语言单独训练的模型。对8种语言的3个基准数据集的评估实验表明,本文的方法比目前的技术水平有了显著提高。本文还在两种有限的资源场景下进行了分析: ( a )zero-shot场景下,当没有目标语言的资源可用时,以及( b )低资源场景下,当只有少量目标语言的资源可用时。本文的分析揭示了zero-shot XEL方法在现实场景中的局限性,并展示了在低资源环境下联合监督的价值。
Model Selection Techniques—An Overview
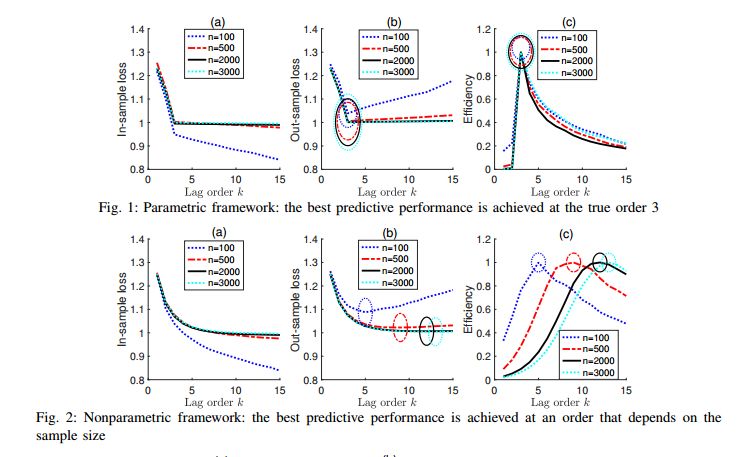
摘要:在“大数据”时代,分析师通常会探索各种统计模型或用于观测数据的机器学习方法,以便于科学发现或获得预测的能力。无论采用何种数据和拟合过程,关键的一步是从一组候选集中选择最合适的模型或方法。模型选择是数据分析中可靠和可再现的统计推断、预测的关键因素,因此对生态学、经济学、工程学、金融学、政治学、生物学和流行病学等领域的科学研究至关重要。从统计学、信息论和信号处理的研究中产生的模型选择技术有着悠久的历史。已经提出了相当多的方法,遵循不同的原理,表现出不同的性能。本文的目的是从动机、大样本性能和适用性方面对它们进行全面概述。本文提供了关于最先进的模型选择方法的理论特性的综合和实际相关的讨论。本文还分享了对模式选择实践中一些有争议的观点的想法。
Learning From Positive and Unlabeled Data: A Survey
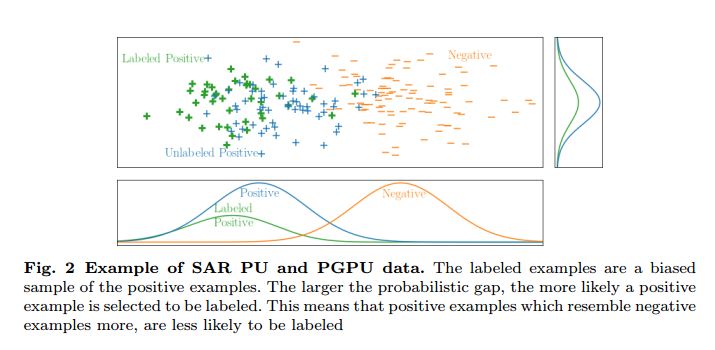
摘要:从正样本和未标记数据中学习或者PU学习通常出现在只有正样本和未标记的数据的场景下。假设未标记的数据可以包含正面和负面的例子。这种场景在机器学习领域中吸引了越来越多的关注,因为这种类型的数据自然会出现在医学诊断和知识图谱补全等应用中。这篇文章概述了PU学习的现状。它提出了这一领域常见的七个关键研究问题,并提供了这一领域如何试图解决这些问题的广泛概述。
论文下载地址
链接: https://pan.baidu.com/s/1HS2Zve1PU7NexuWX2v3vvw
提取码: wp76
往期精品内容推荐
机器学习泰斗- Michael I.Jordan-机器学习前景与挑战
UC Berkeley-18-最新深度强化学习课程(中英字幕)
吴恩达-中文完整版《Mechine Learning Yearning》分享
<深度学习优化策略-3> 深度学习网络加速器Weight Normalization_WN



DeepLearning_NLP


深度学习与NLP
商务合作请联系微信号:lqfarmerlq



