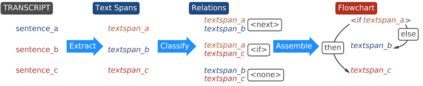
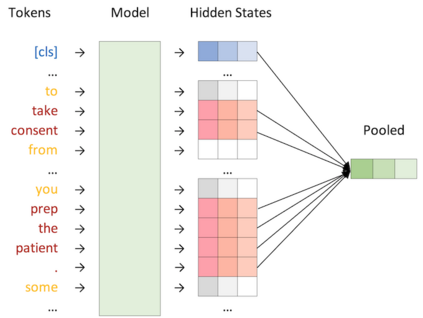
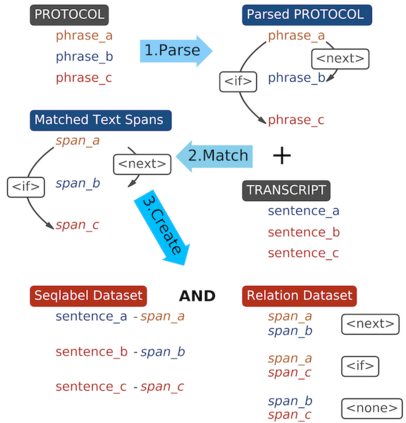
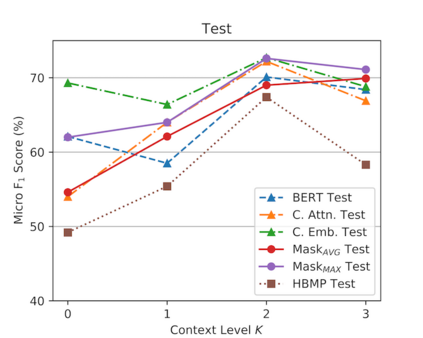
Cognitive task analysis (CTA) is a type of analysis in applied psychology aimed at eliciting and representing the knowledge and thought processes of domain experts. In CTA, often heavy human labor is involved to parse the interview transcript into structured knowledge (e.g., flowchart for different actions). To reduce human efforts and scale the process, automated CTA transcript parsing is desirable. However, this task has unique challenges as (1) it requires the understanding of long-range context information in conversational text; and (2) the amount of labeled data is limited and indirect---i.e., context-aware, noisy, and low-resource. In this paper, we propose a weakly-supervised information extraction framework for automated CTA transcript parsing. We partition the parsing process into a sequence labeling task and a text span-pair relation extraction task, with distant supervision from human-curated protocol files. To model long-range context information for extracting sentence relations, neighbor sentences are involved as a part of input. Different types of models for capturing context dependency are then applied. We manually annotate real-world CTA transcripts to facilitate the evaluation of the parsing tasks
翻译:认知任务分析(CTA)是应用心理学中的一种分析,旨在吸引和代表域专家的知识和思想过程。在CTA中,往往需要大量人力将面试记录解析成结构化的知识(例如,不同行动的流程图)。为减少人类的努力和规模,需要自动的CTA记录解析。然而,这项任务具有独特的挑战,因为(1) 它需要在谈话文本中了解长距离背景信息;(2) 标签数据的数量有限,而且间接地(即,背景觉悟、吵闹和低资源)。在本文件中,我们为自动的CTA记录解析提出一个弱于监督的信息提取框架。我们把分割过程分成一个顺序,标定任务和文本线段相关提取任务,与人类加密协议文件进行远程监督。要模拟用于提取判决关系的长距离背景信息,则将邻里判刑作为一部分投入。然后应用了不同类型的获取背景依赖性模型。我们手动的CTA记录记录本便利对现实世界记录进行评估。