微软创CoQA挑战新纪录,最接近人类水平的NLP系统诞生

新智元报道
新智元报道
来源:Arxiv/CoQA
编辑:大明,文强
【新智元导读】微软语音与对话研究团队开发的SDNet,在面向公共数据集CoQA的问答对话系统模型性能挑战赛中刷新最佳性能纪录,成功夺冠!SDNet成为目前世界上唯一在CoQA领域内数据集上F1得分超过80%的模型,达到80.7%。
近日,微软语音与对话研究团队在斯坦福机器对话式问答数据挑战赛CoQA Challenge中夺冠,并且单模型和集成模型分别位列第二和第一,让机器阅读理解向着人类水平又靠近了一步。
这也是继语音识别、机器翻译等成果之后,微软取得的又一项好成绩。
微软研究人员将自注意力模型和外部注意力相结合,并且用新的方法整合了谷歌BERT语境模型,构建了一个基于注意力的会话式问答深度神经网络SDNet,更有效地理解文本和对话历史。
一直以来,微软研究人员都有在机器阅读理解中使用自注意力模型加外部注意力的想法,终于在这项工作中首次得以实现。
CoQA是面向建立对话式问答系统的大型数据集,CoQA挑战的目标是衡量机器对文本的理解能力,以及机器面向对话中出现的彼此相关的问题的回答能力的高低(CoQA的发音是“扣卡”)。
CoQA包含12.7万个问题和答案,这些内容是从8000多个对话中收集而来的。每组对话都是通过众筹方式,以真人问答的形式在聊天中获取的。
CoQA的独特之处在于:
数据集中的问题是对话式的
答案可以是自由格式的文本
每个答案还附有对话段落中相应答案的理由
这些问题收集自七个不同的领域
CoQA 数据集旨在体现人类对话中的特质,追求答案的自然性和问答系统的鲁棒性。在CoQA 中,答案没有固定的格式,在问题中频繁出现指代词,而且有专门用于跨领域测试的数据集。
CoQA具备了许多现有阅读理解数据集中不存在的挑战,比如共用参照和实用推理等。因此,CoQA Challenge 也更能反映人类真实对话的场景。
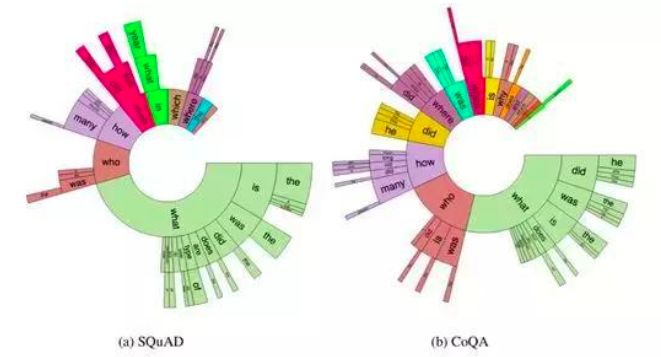
CoQA 与 SQuAD 两个数据集对比:SQuAD 中约一半都是what型,CoAQ种类更多;SQuAD中没有共识推断,CoQA几乎每组对话都需要进行上下文理解推断;SQuAD中所有答案均可从原文本中提取,CoQA中这一比例仅为66.8%。
此前,斯坦福大学的自然语言处理小组已经先后发表了 SQuAD 和 SQuAD2.0 数据集。该数据集包含一系列文本和基于文本的问题、答案。针对该数据集提出的任务要求系统阅读文本后判断该问题是否可以从文本中得出答案,如果可以回答则从文本中截取某一片段做出回答。
目前,微软语音与对话研究已经把他们在 CoQA Challenge上夺冠成果的预印本论文发在了Arxiv上。下面结合论文内容,对该团队的实验方法和研究成果做简单介绍。

在本文中,我们提出了SDNet,一种基于语境注意力的会话问答的深度神经网络。我们的网络源于机器阅读理解模型,但具备几个独特的特征,来解决面向对话的情境理解问题。
首先,我们在对话和问题中同时应用注意力和自我注意机制,更有效地理解文章和对话的历史。其次,SDNet利用了NLP领域的最新突破性成果:比如BERT上下文嵌入Devlin等。
我们采用了BERT层输出的加权和,以及锁定的BERT参数。我们在前几轮问题和答案之前加上了当前问题,以纳入背景信息。结果表明,每个部分都实现了显著提高了预测准确性的作用。
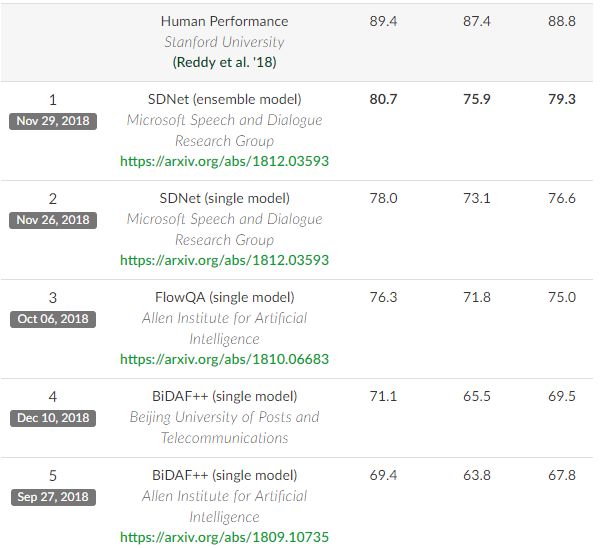
我们在CoQA数据集上对SDNet进行了评估,结果在全局F1得分方面,比之前最先进模型结果表现提升了1.6%(从75.0%至76.6%)。整体模型进一步将F1得分提升至79.3%。此外,SDNet是有史以来第一个在CoQA的领域内数据集上表现超过80%的模型。
我们在CoQA 上评估了我们的模型。在CoQA中,许多问题的答案需要理解之前的问题和答案,这对传统的机器阅读模型提出了挑战。表1总结了CoQA中的领域分布。如图所示,CoQA包含来自多个领域的段落,并且每个段落的平均问答超过15个。许多问题需要上下文的理解才能生成正确答案。
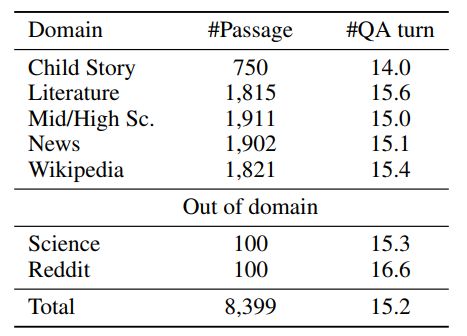
对于每个域内数据集,开发集中有100个段落,测试集中有100个段落。其余的域内数据集位于训练集中。测试集还包括所有域外段落。
基线模型和指标
我们将SDNet与以下基线模型进行了比较:PGNet(具有复制机制的Seq2Seq)、DrQA、DrQA +PGNet、BiDAF ++ Yatskar(2018)和FlowQA Huang等。 (2018)。与官方排行榜一致,我们使用F1作为评估指标,F1是在预测答案和基本事实之间的单词级别的精度上的调和平均。
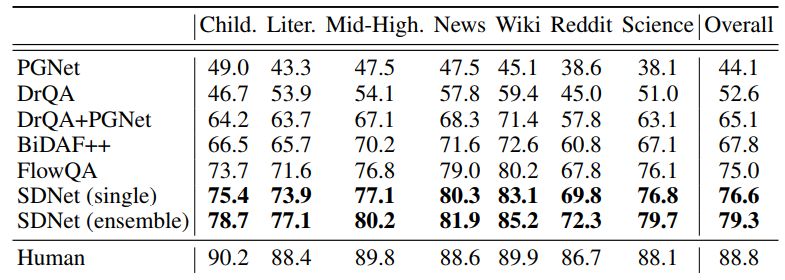
结果
上表所示为SDNet和基线模型的性能对比。如图所示,使用SDNet的实现结果明显好于基线模型。具体而言,与先前的CoQA FlowQA模型相比,单个SDNet模型将整体F1得分提高了1.6%。 Ensemble SDNet模型进一步将整体F1得分提升了2.7%,SDNet是有史以来第一个在CoQA的领域内数据集上表现超过80%的模型(80.7%)。
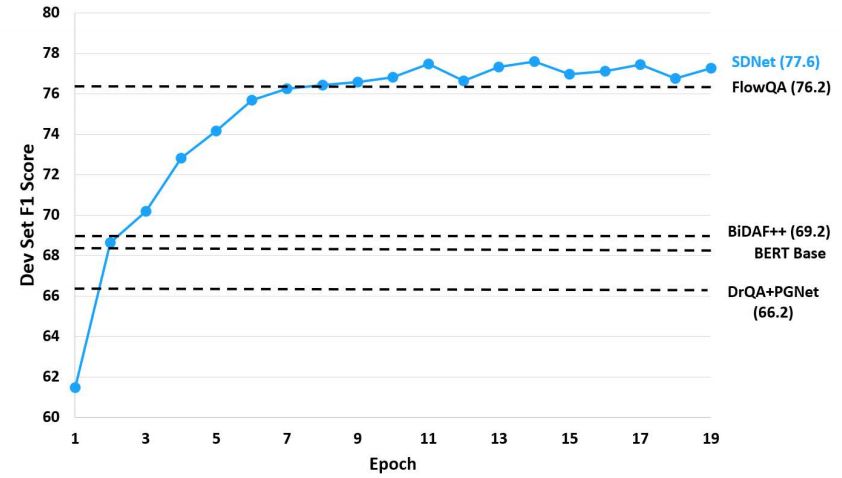
上图所示为开发集随epoch变化的F1得分情况。SDNet在第二个epoch之后的表现超越了两个基线模型,并且仅在8个epoch后就实现了最优秀的表现。

消融研究 (Ablation)
我们对SDNet模型进行了消融研究,结果在上表中显示。结果表明,正确使用上下文嵌入BERT是至关重要的。虽然移除BERT会使开发集的F1得分降低6.4%,但在未锁定内部权重的情况下加入BERT会使得F1得分降低13%。
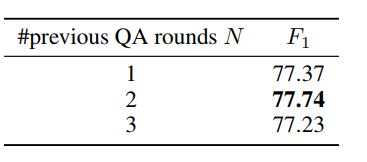
上下文历史
在SDNet中,我们将当前问题与前N轮问题和真实答案前置一致,来利用对话历史记录。我们试验了不同的N值的效果,并在表4中列出了结果。试验显示,我们的模型的性能对N的设置不是非常敏感。最后,我们的最终模型设置N = 2。
我们提出了一种新的基于情境注意的深度神经网络SDNet,以解决对话问题的回答任务。通过在通过和对话历史上利用注意力和自我关注,该模型能够理解对话流并将其与消化段落内容融合在一起。
此外,我们融入了自然语言处理领域 BERT的最新突破,并以创新的方式利用它。与以前的方法相比,SDNet取得了卓越的成果。在公共数据集CoQA上,SDNet在整体F1指标得分上的表现比之前最先进的模型高1.6%。
纵观CoQA Challenge排行榜,从今年8月21日到11月29日,短短3个月时间里,机器问答对话的总体成绩就从52.6提升到79.3,距离人类水平88.8似乎指日可待。
“最后一公里往往是最难的,很难预测机器能否达到人类水平。”论文作者之一、微软全球技术Fellow、负责微软语音、自然语言和机器翻译工作的黄学东博士告诉新智元。
未来,他们打算将SDNet模型应用于具有大型语料库或知识库的开放域中,解决多循环问答问题,这类问题中,目标段落可能是无法直接获得的。这和人类世界中的问答的实际情况可能更为接近。
更多阅读:
SDNet相关论文地址:
https://arxiv.org/pdf/1812.03593.pdf
关于CoQA Challenge的更多信息详见:
https://stanfordnlp.github.io/coqa/
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。