再破新纪录!微软最新NLP模型3项评分全面超越人类水平!

新智元报道
新智元报道
来源:microsoft
编辑:大明
【新智元导读】近日,微软亚研院NLP团队和微软Redmond语音对话团队,在斯坦福大学的会话问答(CoQA)挑战赛中取得佳绩,三项评分全面超越人类水平
媲美人类对话水平!
由微软亚洲研究院(MSRA)的自然语言处理(NLP)团队和Microsoft Redmond的语音对话团队的研究人员在斯坦福大学的会话问答(CoQA)挑战赛中处于领先地位。
在CoQA挑战中,通过理解文本段落,并回答对话中出现的一系列相互关联的问题,来衡量机器的性能。微软目前是唯一一个在模型性能方面达到人类水平的团队。
CoQA是一个大规模的会话式问答数据集,由来自不同领域的一组文章的对话式问题组成。 MSRA的NLP团队之前使用斯坦福问题答疑数据集(SQuAD)在单轮问答上达到了人类水平。与SQuAD相比,CoQA中的问题更具会话性,答案可以是自由格式的文本,确保对话中答案的自然性。
CoQA中的问题很短,更倾向于模仿人类对话。此外,第一个问题之后的每个问题都取决于过去的对话内容,使得这些简短问题对于机器而言更难解析。例如,假设你曾问过系统,“微软的创始人是谁?”当提出后续问题“他什么时候出生的?”时,其实仍然在谈论同一话题。

来自CoQA数据集的一组对话,可以看到新问题与过去的问题之间的逻辑联系
CoQA是面向建立对话式问答系统的大型数据集,CoQA挑战的目标是衡量机器对文本的理解能力,以及机器面向对话中出现的彼此相关的问题的回答能力的高低(CoQA的发音是“扣卡”)。
CoQA包含12.7万个问题和答案,这些内容是从8000多个对话中收集而来的。每组对话都是通过众筹方式,以真人问答的形式在聊天中获取的。
CoQA的独特之处在于:
数据集中的问题是对话式的
答案可以是自由格式的文本
每个答案还附有对话段落中相应答案的理由
这些问题收集自七个不同的领域
CoQA 数据集旨在体现人类对话中的特质,追求答案的自然性和问答系统的鲁棒性。在CoQA 中,答案没有固定的格式,在问题中频繁出现指代词,而且有专门用于跨领域测试的数据集。
CoQA具备了许多现有阅读理解数据集中不存在的挑战,比如共用参照和实用推理等。因此,CoQA Challenge 也更能反映人类真实对话的场景。
此前,斯坦福大学的自然语言处理小组已经先后发表了 SQuAD 和 SQuAD2.0 数据集。该数据集包含一系列文本和基于文本的问题、答案。针对该数据集提出的任务要求系统阅读文本后判断该问题是否可以从文本中得出答案,如果可以回答则从文本中截取某一片段做出回答。
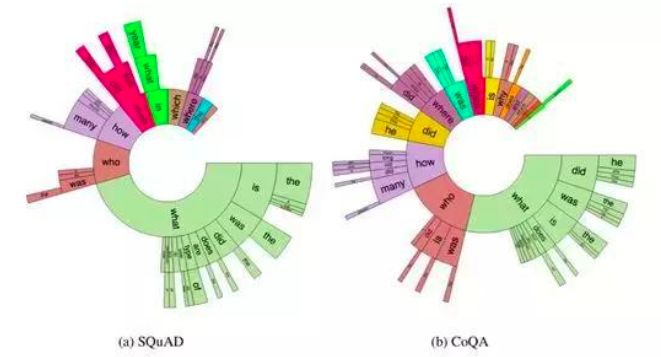
CoQA 与 SQuAD 两个数据集对比:SQuAD 中约一半都是what型,CoAQ种类更多;SQuAD中没有共识推断,CoQA几乎每组对话都需要进行上下文理解推断;SQuAD中所有答案均可从原文本中提取,CoQA中这一比例仅为66.8%。
为了更好地测试现有模型的泛化能力,CoQA从七个不同的领域收集数据:儿童故事、文学作品、初高中英语试题、新闻、维基百科、Reddit和科学文献。前五个来源用于训练、开发和测试集,后两个仅用于测试集。
CoQA使用F1指标来评估性能。该指标衡量预测答案和Ground truth答案之间的词汇平均重叠度。域内F1根据与训练集相同域的测试数据进行评分,此外还会对来自与训练集不同的域内的测试数据给出域外F1。总体F1是整个测试集的最终得分。
微软的研究人员采用了一种特殊策略,将机器从其他几个相关任务中学习的信息用于改进目标机器阅读理解(MRC)任务的表现。在这种多阶段、多任务的微调方法中,研究人员首先在多任务设置下从相关任务中学习MRC的相关背景信息,然后在目标任务上对模型进行微调。
在这两个阶段中都使用了语言建模来辅助任务,以减少会话式问答模型的过拟合。实验结果证明这种方法是有效的,模型在CoQA挑战赛中的出色表现进一步证明了这一点。
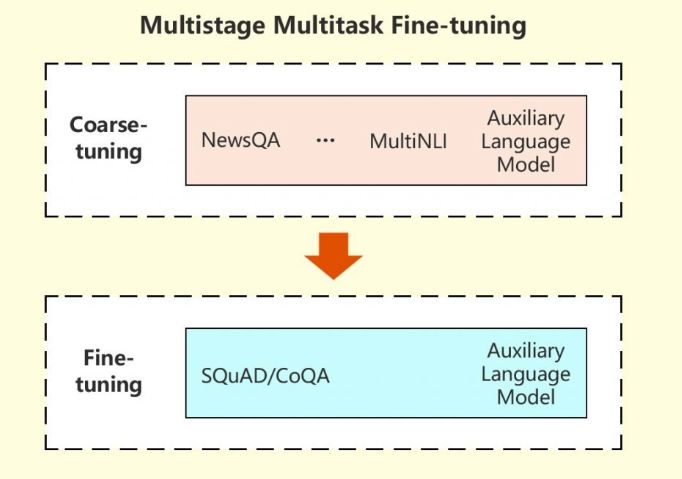
多级多任务微调模型原理示意图
在CoQA排行榜上,微软研究人员于2019年3月29日提交的集合系统的域内、域外和整体F1得分分别达到了89.9 / 88.0 / 89.4。同一会话问答下的人类表现为89.4 / 87.4 / 88.8。
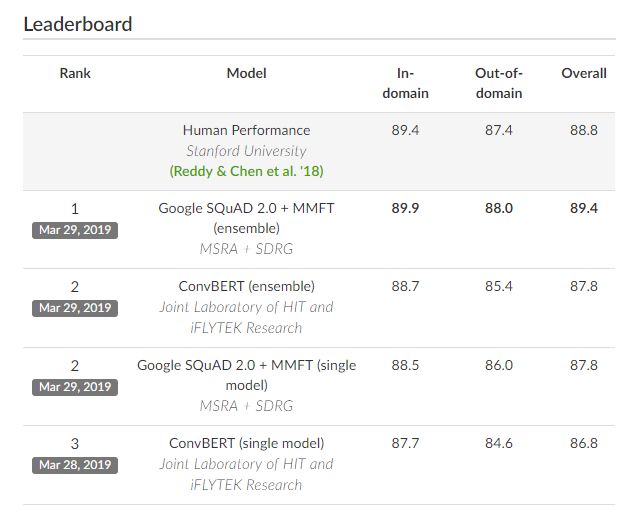
这项成就标志着微软在Bing等搜索引擎和Cortana等智能助手与人们更自然地互动和提供信息方面取得了重大进展,这些互动更接近于真人之间的交流。尽管如此,一般的机器阅读理解和问答仍然是自然语言处理中尚未解决的问题。
为了进一步突破机器的能力界限,理解和生成自然语言,微软团队表示将继续致力于打造更强大的预训练模型。
参考链接:
https://www.microsoft.com/en-us/research/blog/machine-reading-systems-are-becoming-more-conversational/?from=groupmessage&isappinstalled=0
相关论文:
https://arxiv.org/abs/1808.07042
新智元春季招聘开启,一起弄潮 AI 之巅!
岗位详情请戳:
.png")
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。





