中国AI军团争霸机器阅读理解大赛,搜狗创下全球新纪录

本文经AI新媒体量子位(公众号ID:qbitai )授权转载,转载请联系出处
本文约2500字,建议阅读5分钟。
最近搜狗AI团队在CoQA机器阅读理解大赛高分夺冠,本文为你介绍CoQA、搜狗模型以及未来前景。
全球AI竞技场,现在全方位成为中国公司实力展示台。
这不,2018年迭代上线的CoQA机器阅读理解大赛,一番你争我赶之后,最终还是形成了中国AI力量争霸之势。
而且更可喜的是,就在最近,搜狗AI团队脱颖而出,不仅高分夺冠,而且全面刷新CoQA所有评价指标。
不得不说:威武~
搜狗夺冠CoQA
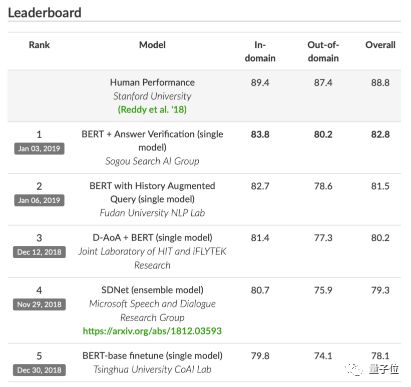
此次夺冠的搜狗团队来自搜狗搜索AI研究团队,模型则是BERT + Answer Verification(单一模型)。
从9月份发布到现在,CoQA大赛已经吸引了国内外众多知名研究机构和高校,包括微软、讯飞、清华、复旦,斯坦福等等,竞争异常激烈。
在不到一个月时间内,CoQA挑战赛榜首已经3次易主。
1月3日,搜狗以82.8%的成绩稳稳占据榜首位置,全面刷新CoQA所有评价指标。
并且,搜狗的算法是CoQA的领域外(out-of-domain)数据集上表现首个超过80%的模型。
CoQA之难
CoQA大赛究竟有何特别之处?
如果非NLP从业者,对于CoQA可能会有些许陌生。你可能会好奇,不到半年的时间里,为何各大公司、高校都在努力攻克CoQA?
这就要从去年自然语言处理(NLP)领域的快速发展谈起。
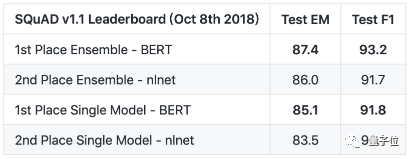
2018年是NLP取得重大进展的一年,BERT出现,横扫各大NLP测试,刷新了SQuAD成绩。
除了算法以外,NLP领域的一项重要应用问答系统(QA)也在这一年悄然改变。
SQuAD测试已经逐渐跟不上智能问答系统的发展,行业急需一个更具有挑战性、更智能的QA挑战。取而代之的是今年8月上线的CoQA。
如果说SQuAD像是做英文阅读理解,那CoQA更像是模拟真实的人类对话。
CoQA包含从8000多个对话中收集的127,000多个问答。每个对话都是通过将两个人配对,以问答对话聊天形式收集的。
CoQA的独特之处在于:
问题不是SQuAD的一问一答,而是多轮对话形式的;
答案可以是自由格式的文本;
每个答案还附有段落中的证据子序列;4、测试集包含七个不同领域的资料。
QA多轮对话更类似于人类,应用前景广阔。比如去年谷歌发布的AI打电话,甚至通过图灵测试,就是QA多轮对话的一个落地场景。

另外,比赛官方提供的训练数据来自5个领域的文章,而测试集还多出两个其他领域(reddit论坛、science网站)的文章,更考验NLP“举一反三”的能力。
比赛榜单包含两个部分,领域内(In-domain)是指测试集“考题”与训练集来自相同领域,领域外(out-of-domain)是测试集“考题”来自训练集之外的2个领域,测试的是模型推理能力。
搜狗这两个测试的得分分别是83.8和80.2,都是排名第一,并且两部分分差在所有参赛团队中最小,体现了搜狗模型在阅读理解上的通用泛化能力。
如何评价搜狗模型?
没有随随便便的成功。
从去年BERT模型横空出世以来,搜狗就开始思索将其与自家的研究成果结合起来。
本次参加CoQA比赛的模型就是BERT与Answer Verification的结合。搜狗创新性地在BERT的输出层中加入推理判断网络,用于解决原文中无法直接找到答案的情形。
这个推理判断网络就是搜狗采用的有证据支撑的“答案抽取网络”(Answer Verification)。它能应用注意力(Attention)和自注意力(Self-attention)机制,将对话问题和材料进行整体编码,推理出答案。
搜狗认为人在阅读理解的过程中,寻找支撑答案的文本和选择精准答案的过程是相互交织进行的,因此“答案抽取网络”也效仿人类的思考模式,使得答案抽取有更强的上下文支撑。
为了让AI对当前轮对话问题有更好地理解,搜狗模型将历史对话的问题和答案同当前轮问题一起输入到网络中,从而提升在多轮对话中的表现。
同时,搜狗在训练中对BERT的预训练参数进行了微调。
实验结果表明,搜狗团队的上述设计策略显著提升了在CoQA测试上的效果。
这种算法能综合考虑答案抽取和证据对答案的支撑作用,同时融入对话历史的问题和答案信息,极大提升了对当前问题的理解和回答的准确性。其有两大亮点:
1) 有证据支撑的答案选择:
人类做阅读理解是一个找回答了问题的句子和提炼精确答案同时进行的过程,搜狗的算法创新性的模拟了这一过程,做到了有证据文本支撑的答案选择。
2) 推理类答案的理:
CoQA比赛的问题中,有相当部分的问题是原文中无直接答案,需要通过推理才能得出。搜狗的算法将推理转换成分类问题,通过问题-材料的整体编码,找到推理答案。
前沿技术已落地
当然,或许你也好奇,搜狗拿下这样的“冠军”有何用?
搜狗方面回答,从去年9月决定参赛到称霸榜首,搜狗投入大量时间和人力物力参加CoQA大赛,并非只看重“跑分”。
因为搜狗一直坚持探索以语言为核心的人工智能战略,AI问答之于搜狗的重要意义,不言自明。
而且以技术和产品知名的搜狗,已将前沿技术成果在产品中落地。
搜狗搜索的智能回答
智能音箱
比如去年大热的智能音箱,就是问答服务的一个天然应用场景,BAT等公司都在布局。去年华为也杀入战场,而背后正是有搜狗问答技术的支持。
然而世面上不少智能音箱产品,只能用在简单问答的鸡肋场景。

华为AI音箱,在各种方案PK后,选择了搭载搜狗的智能问答服务。用户只需用自然语言提问,系统即可“听懂”用户的话,并直接“回复”用户想要的信息。让智能音箱真正做到高效便捷,而不是让人去迁就产品。
这就是前沿技术+快速产品落地能力的牛刀小试。
专业搜索
此外,更重要的是搜狗核心业务的进一步强化。
搜索是搜狗的起点,王小川相信搜索的未来是问答,而机器阅读理解是现今问答技术发展的核心之一。

将AI问答用在专业领域的搜索会擦出怎样的火花?
目前搜狗在法律、医疗领域做出了尝试。
在法律领域,搜狗律师问答机器人具备逻辑分析和推理能力,能够基于事实和法律诉求,给用户提出可能的判决结果、法律建议或相似案例等丰富的咨询结果,充当人类的法律小顾问。
在医学领域,搜狗搜索智能分诊功能,首创引入了基于人工智能技术的智能诊断助手,模拟医生与病人对话的模式与用户进行病情沟通,并提供可能的疾病范围,供用户参考。
全球视角看未来
如上文所述,除了搜狗以外,参加CoQA的还有微软、艾伦研究院(AI2)、斯坦福大学、清华大学COAI实验室、北京大学、复旦大学、北京邮电大学、中国科技大学等知名顶级公司和机构。
全球科技公司都在研发前沿的问答技术。去年谷歌的AI打电话订餐轰动全球,标志着AI已经开始攻克图灵测试。
刷榜夺冠CoQA大赛,对搜狗来说只是技术实力证明的牛刀小试,也是搜狗搜索团队在前沿技术研究、应用和产品落地方面的答卷。
智能问答领域的头雁争夺,未来还会更激烈。
CoQA大赛是起点,但也是目前该领域全球范围内最权威的参照之一。
搜狗夺冠,展示的不仅是AI领域头号玩家的潜力和能力,也是对中国AI实力的又一次介绍。
在全球科技进程中,这是大历史性的一刻。






