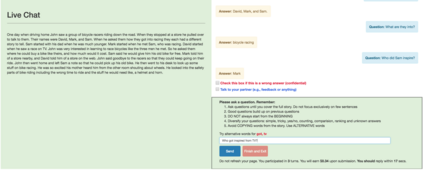
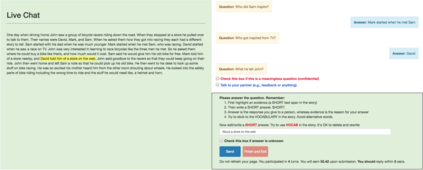
Humans gather information by engaging in conversations involving a series of interconnected questions and answers. For machines to assist in information gathering, it is therefore essential to enable them to answer conversational questions. We introduce CoQA, a novel dataset for building Conversational Question Answering systems. Our dataset contains 127k questions with answers, obtained from 8k conversations about text passages from seven diverse domains. The questions are conversational, and the answers are free-form text with their corresponding evidence highlighted in the passage. We analyze CoQA in depth and show that conversational questions have challenging phenomena not present in existing reading comprehension datasets, e.g., coreference and pragmatic reasoning. We evaluate strong conversational and reading comprehension models on CoQA. The best system obtains an F1 score of 65.1%, which is 23.7 points behind human performance (88.8%), indicating there is ample room for improvement. We launch CoQA as a challenge to the community at http://stanfordnlp.github.io/coqa/
翻译:人类通过一系列相互关联的问答对话来收集信息。 因此,对于协助信息收集的机器来说,对于帮助信息收集的机器来说,关键在于让他们能够回答对话问题。 我们引入了CoQA,这是一个用于建立对话问答系统的新数据集。 我们的数据集包含127k个问题,答案来自8k个关于7个不同领域的文本段落的8k个对话。 问题是交谈性的,答案是自由形式文本,其相应证据在段落中突出。 我们深入分析了CoQA, 并表明现有阅读理解数据集中不存在对对话问题的挑战性现象, 例如, 共同引用和务实的推理。 我们评估了在CoQA上强烈的谈话和阅读理解模式。 最佳系统获得了65.1%的F1分,这比人类表现(88.8%)落后了23.7分,这表明有相当大的改进空间。 我们在http://stanfordnlp.github.io/coqa/社区面临的挑战。