微软机器阅读理解系统性能升级,刷新CoQA对话式问答挑战赛纪录

近日,由微软亚洲研究院自然语言处理组与微软雷德蒙语音对话组研究员组成的团队,在斯坦福大学发起的对话式问答挑战赛CoQA(Conversational Question Answering Challenge)中荣登榜首,成为目前排行榜上唯一一个模型分数超过人类分数的团队。
CoQA是由关于不同领域文章的一组组对话式问答构成的大型数据集,要求机器对文本进行阅读理解,然后对一系列相互关联的问题作出回答。此前,微软亚洲研究院自然语言计算组开发的系统在斯坦福大学发起的SQuAD(Stanford Question Answering Dataset)文本理解挑战赛中,取得了单轮问答媲美人类成绩的突破。与SQuAD相比, CoQA具有多轮问答的“对话”属性,而且机器的回答形式也更加自由,以确保对话的自然流畅。
由于人类在对话中的句子通常比较简短,为了更好地模仿这一表达特征,CoQA数据集中的问题也都非常简短。同时,在对话式问答中,首个问题后的每个问题都是基于前序对话展开的。CoQA的这些特性为机器的分析理解带来了更大的困难。比如,当你询问“微软的创始人是谁?”,并接着追问“他何时出生?”时,系统必须意识到你在就同一个话题进行讨论。

为了测试模型的泛化能力,CoQA数据集是从儿童故事、文学、初高中英语考试、新闻、维基百科、Reddit和科学等七个完全不同的领域进行收集的。其中,前五个领域的数据集用于训练、开发和测试,而后两个领域的数据集仅作为测试使用。 CoQA数据集使用F1值来衡量预测值和真实值之间的平均单词重合率,以评估模型的性能。其中,领域内(in-domain)F1值表示测试集数据与训练集数据来自相同的领域,领域外(out-of-domain)F1值表示测试集数据与训练集数据来自不同的领域,而综合(overall)F1值代表了整个测试集的最终得分。
为了破解这些挑战,微软研究人员采取了一种特殊的策略,利用机器阅读系统从几个相关任务中学习到的信息来改进它在目标机器阅读理解任务中的表现。在这种多阶段、多任务的精调方法中,研究人员首先在多任务场景下,让机器阅读系统从与目标任务相关的任务中学习背景信息,然后在目标任务上对模型进行精调。除此之外,语言建模在两个阶段中都起到了辅助作用,有效帮助对话式问答模型减少过拟合。该系统在CoQA挑战赛中的杰出表现证明了这一方法的有效性。
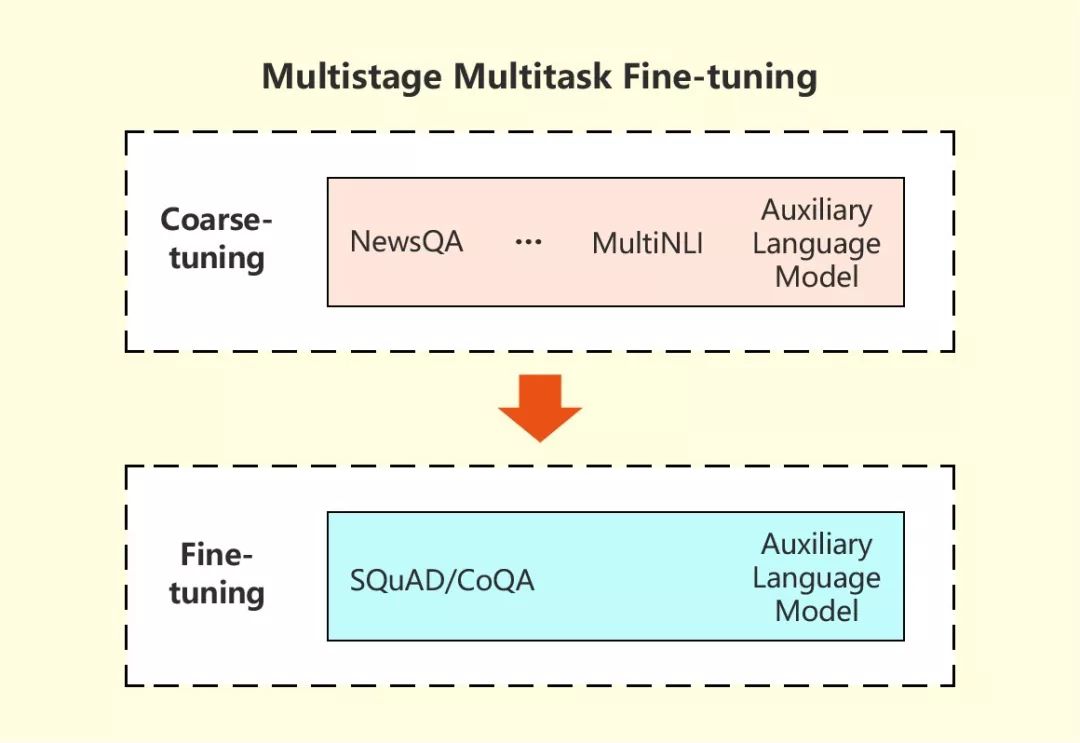
目前,微软团队在2019年3月29日提交的整合系统在领域内、领域外、综合F1值上的得分分别为89.9 / 88.0 / 89.4,均超越人类在同一组会话问答中的平均表现89.4 / 87.4 / 88.8,在CoQA挑战赛排行榜中位列第一。
这项突破标志着以Bing为代表的搜索引擎和以Cortana为代表的智能助手,将以类似于人类沟通一样自然的方式与人类进行互动和提供信息,成为人们工作生活的得力助手。尽管今天的技术正在飞速迭代和进步,广义的机器阅读理解和问答仍然是自然语言处理中悬而未决的难题。为了对这一问题进行更加深入的探索,微软研究团队正致力于开发更加强大的预训练模型,不断拓展机器阅读理解和自然语言生成的边界。
你也许还想看:



感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。





