
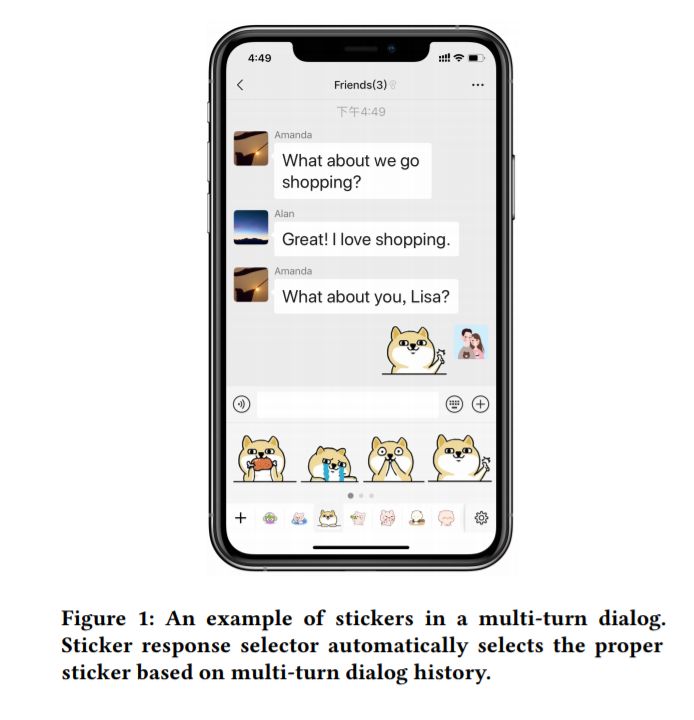
表情生动、引人入胜的表情包在网络短信应用中越来越受欢迎,一些作品致力于通过将表情包的文本标签与之前的话语进行匹配,自动选择表情包响应。然而,由于数量庞大,要求所有贴纸都有文字标签是不切实际的。因此,在本文中,我们建议在不使用任何外部标签的情况下,根据多回合对话框上下文历史向用户推荐合适的标签。这项任务面临两大挑战。一是学习没有对应文字标签的贴纸的语义。另一个挑战是使用多回合对话框上下文联合建模候选标签。为了解决这些挑战,我们提出了一个贴纸响应选择器(SRS)模型。具体来说,SRS首先使用一个基于卷积的贴纸图像编码器和一个基于自我注意力的多回合对话编码器来获取贴纸和话语的表示。接下来,我们提出了深度交互网络,将标签与对话历史中的每个话语进行深度匹配。然后SRS通过融合网络学习所有交互结果之间的短期和长期依赖关系,输出最终的匹配分数。为了评估我们提出的方法,我们从最流行的在线聊天平台之一收集了一个带有贴图的大型真实世界对话数据集。在该数据集上进行的大量实验表明,我们的模型在所有常用指标上都达到了最先进的性能。实验还验证了SRS各组成部分的有效性。为了便于贴纸选择领域的进一步研究,我们发布了340K多回合对话框和贴纸对数据集。
成为VIP会员查看完整内容
相关内容

专知会员服务
37+阅读 · 2020年4月10日
专知会员服务
33+阅读 · 2020年2月29日
Arxiv
14+阅读 · 2020年3月10日


相关VIP内容
专知会员服务
37+阅读 · 2020年4月10日
专知会员服务
33+阅读 · 2020年2月29日
相关资讯
相关论文
Arxiv
14+阅读 · 2020年3月10日