KDD'21 | 如何评估GNN的解释性模型?

论文地址:https://dl.acm.org/doi/pdf/10.1145/3447548.3467283
Introduction
首先先介绍一下图解释性模型的流程。目前的图解释性模型基本是后验型的,即先有一个训练好的模型,然后用一种解释性方法,去看哪些子结构是可以对结果有突出性贡献的,模型流程图如下: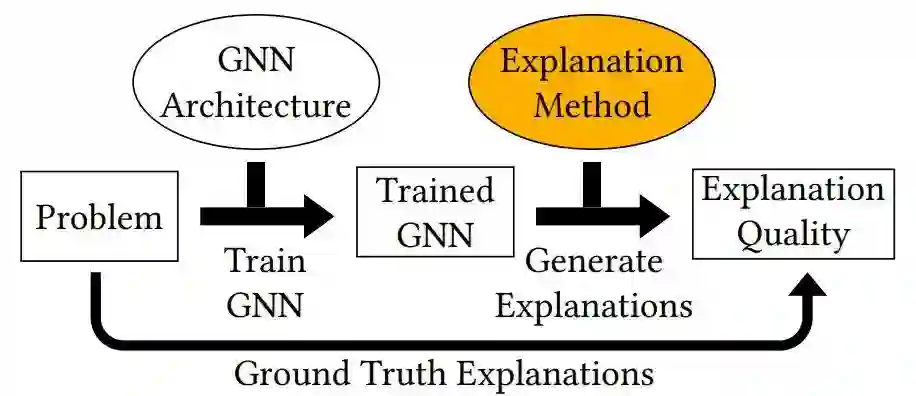
最近的一些解释性工作在设计数据集评估的时候大概率会忽略这些问题,因此这篇文章分析了为什么这些已有评估方法不大行的原因,并且针对这些原因提出了新的解释性数据集。
Method
可能面临的问题
1. 偏差项
在一些情况下,GNN模型本身可能仅学习了一种分类的表征,即这种情况下
,也就是对于另一个分类结果,模型根本不会管原始标签下的边
是怎么样的。这个时候任何现有的解释器都不应当解释出结果。作者采用了CYCLIQ数据集作为例子。这个数据集是一个图的二分类数据,目标是区分环形和团形图。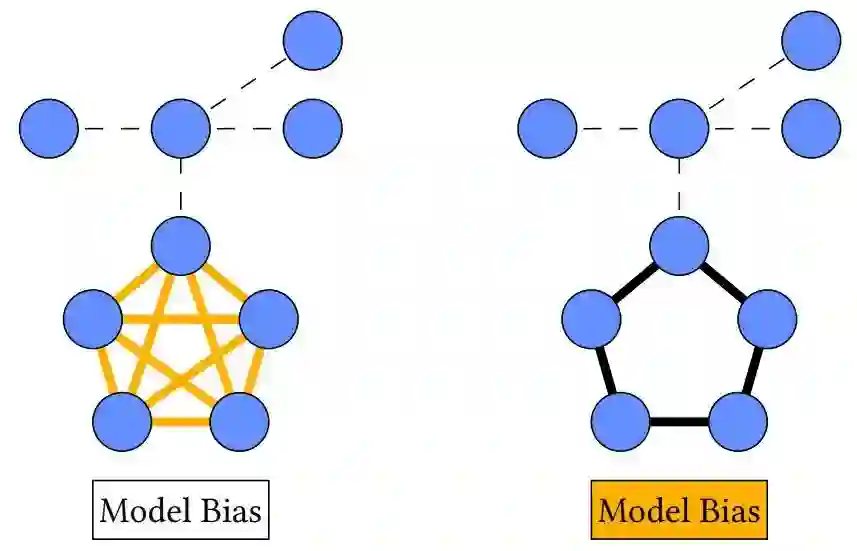
2. 多余的结构
多余的结构是指边集合 不唯一,可能还存在一个 也是对当前预测的解释,甚至存在不相交的集合 。举一个Tree-Cycle的模拟数据作为例子,模型需要判断图中的节点是属于树形图的还是环形图的。作者认为这个数据用2层GNN就能够达到和3层GNN一样的效果,这意味着图网络不需要再去寻找2跳以后的结构信息。因此,作者认为这种多跳会引入额外的边信息,并且会干扰到真正有用的结构信息的选择,这就是多余的结构。基于这种分析,作者认为benchmark需要是唯一的边集合(PS:个人感觉这个观点可能有点问题,在真实复杂场景下这种多跳的选择一般也会选择到一个对结果更好的值吧,这种事情谁说的准呢。。。)
3. 简单的解释
在以往的图像解释器的论文中,出现过一个边缘滤波器就能提供一个比较好的解释。因此,作者认为图的解释器方法也需要一种简单的解释,比如在Tree-Cycles数据里边是一种可以直观理解的信息。作为延伸,还能考虑最近邻,Page-rank等具有直观表征的解释数据集作为benchmark。
4. GNN本身的预测能力
在GNN的预测结果较差的时候是不能被解释的。即使有一部分标签被预测正确了,仍然不知道GNN是否是真正考虑了结构信息。因此,GNN本身需要达到最优的结果。作为研究解释性,这种精度需要尽可能达到100%,这样解释性模型才有可能达到最好的效果。
5. GNN的结构
不同GNN遵循不同的体系结构,会导致其关注图的侧重点会不一样。如图展示了一个样例: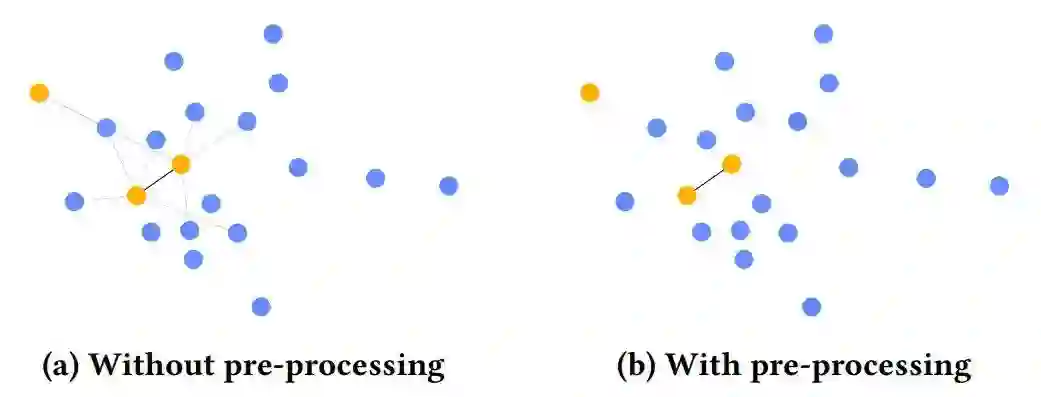
新的benchmark
针对以上的5个问题,作者针对性的提出了一些新的benchmark来评估解释性方法。目前已有的解释性方法很多都是在一些真实数据上进行操作的,尤其是生物数据非常多,但是为了解决前文提到的几个问题,作者提出了一些数据集作为解释性模型新的benchmark。
1) 感染检测数据集:这种数据集建立的方法是创建一个随机有向图,定义每个节点都可以为健康节点或者被感染节点,任务目标为节点分类,预测感染节点到当前节点的最小距离,且上限为5。
2)社交数据集:图网络本身在社交网络里是非常常见的模型,包括购物,学者引用都属于这一类。而这里的社区交互网络则是判断社交的人是否在一个圈子里,这样,这个社区网络的交互可以简单分为内部交互和外部交互。作者采用随机块模型(stochastic block model, SBM)定义社区交互网络,这里有一个示意图: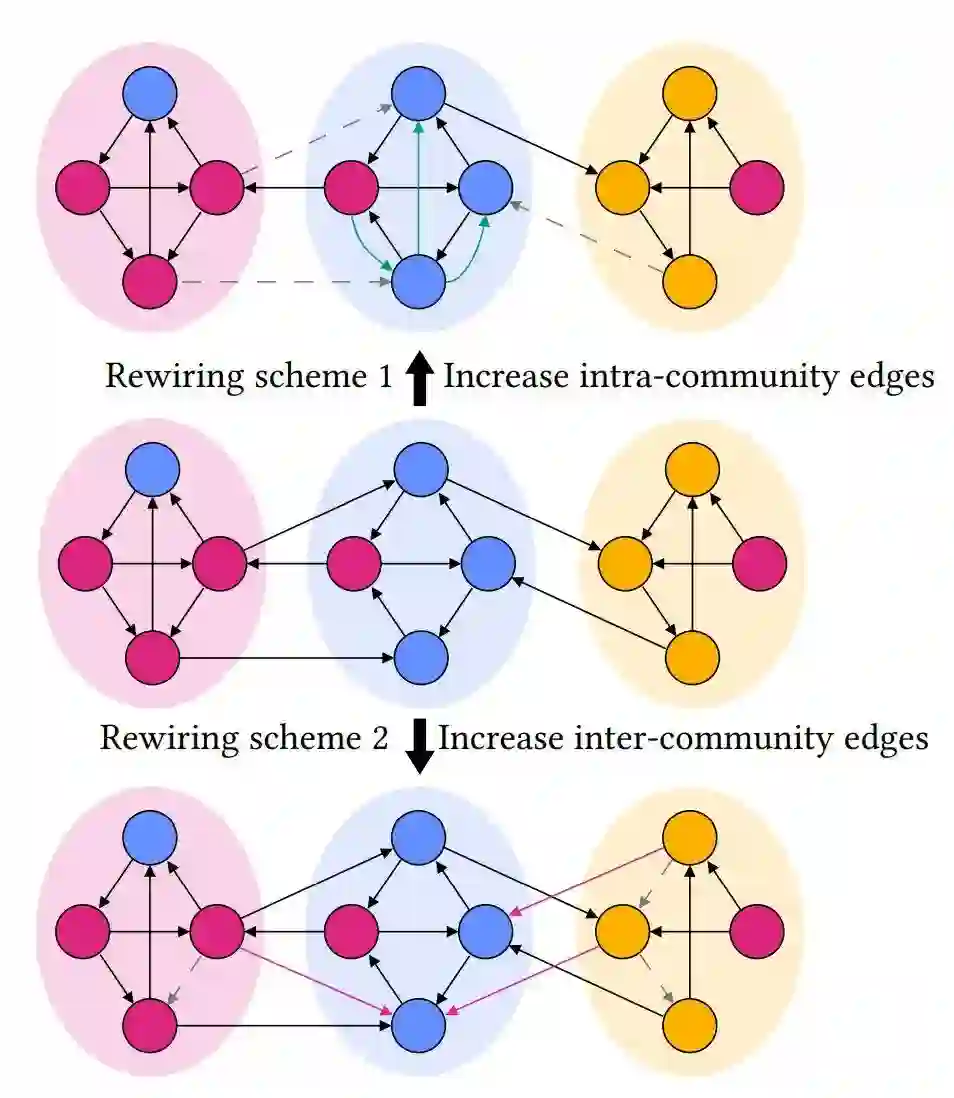
2) 负样本评估:这种评估数据集非常直接了当,定义了图中的节点是否真的有存在重要信息,然后对这些节点进行分类。作者设置了一些红色、蓝色和白色的节点,如图所示: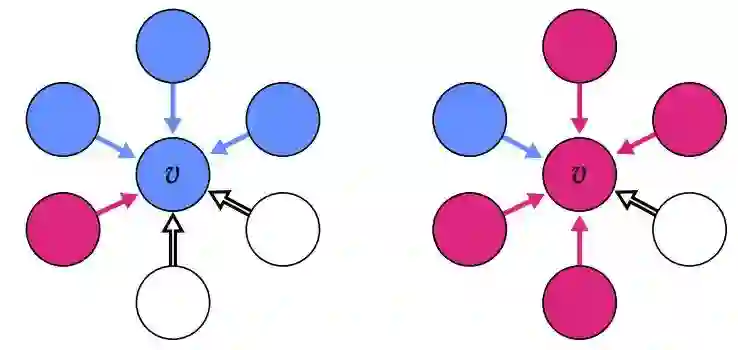
Experiment
首先看一下在作者给出的几个数据集上的GNN准确率: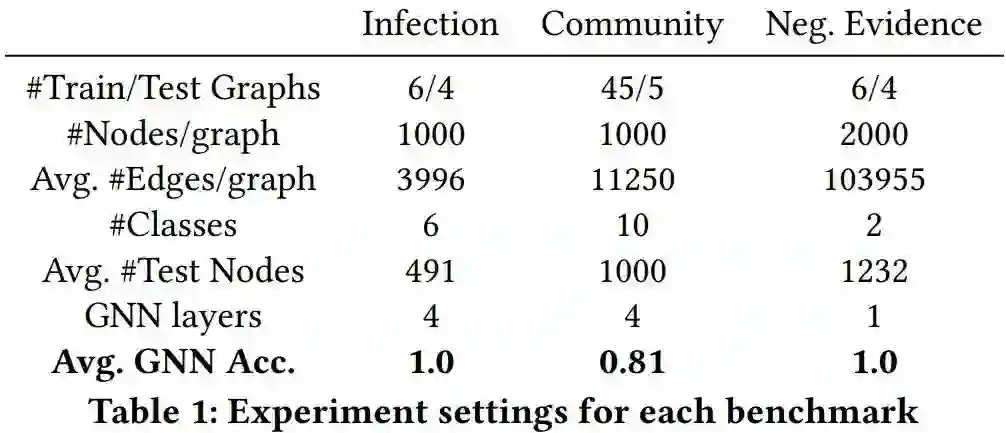
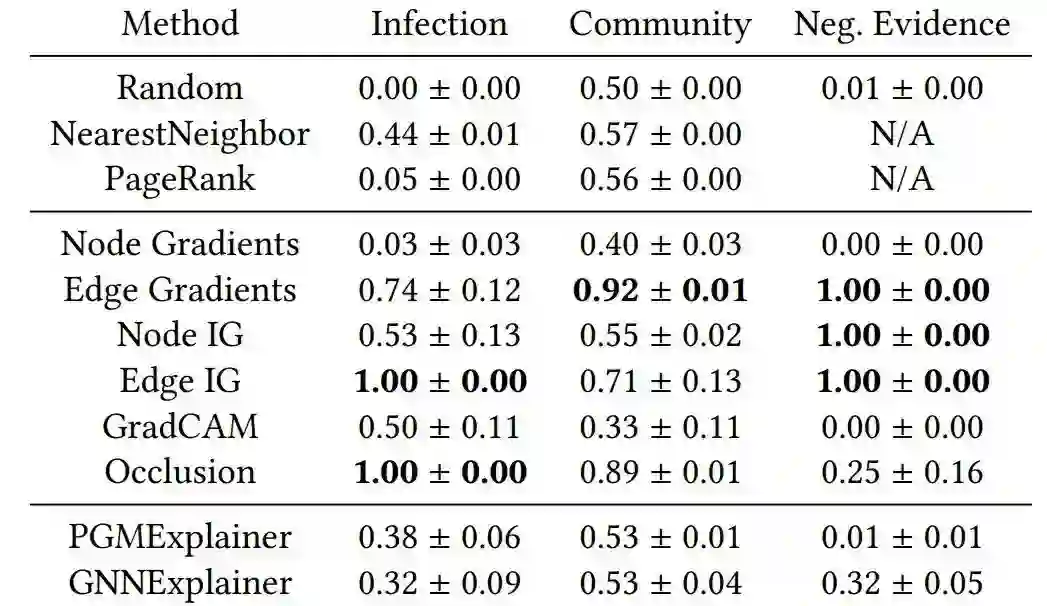
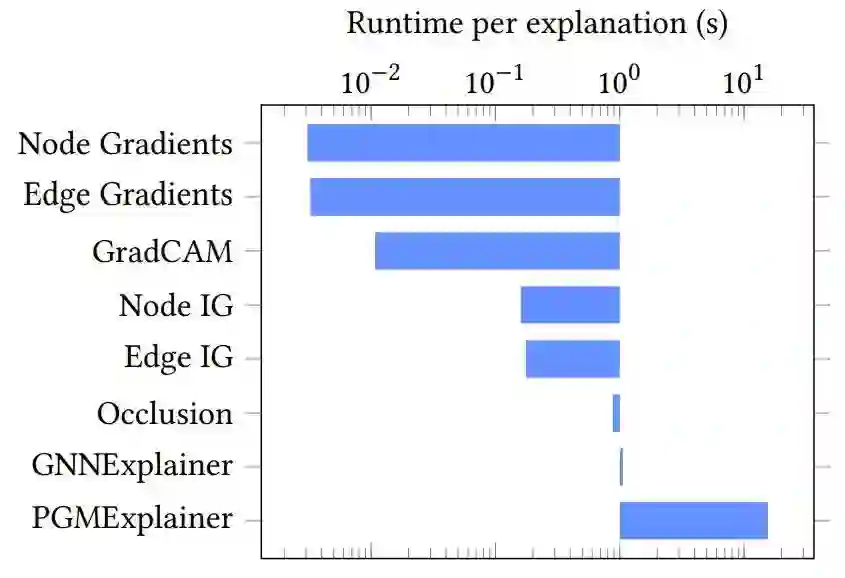
也就是说Gradient-based 方法可能才是图解释性问题解决的终极方案?



