图谱实战 | 再谈图谱表示:图网络表示GE与知识图谱表示KGE的原理对比与实操效果分析
转载公众号 | 老刘说NLP
知识图谱嵌入是一个经典话题,在之前的文章《知识表示技术:图谱表示VS图网络表示及基于距离函数的表示学习总结》中,围绕知识图谱嵌入学习这一主题,对比了知识图谱嵌入与图网络嵌入的异同。
而在实际工作中,我们通常会面临着对一个知识图谱进行嵌入的问题,并且要选择对应的方法进行处理。
先给一个草草的发现:
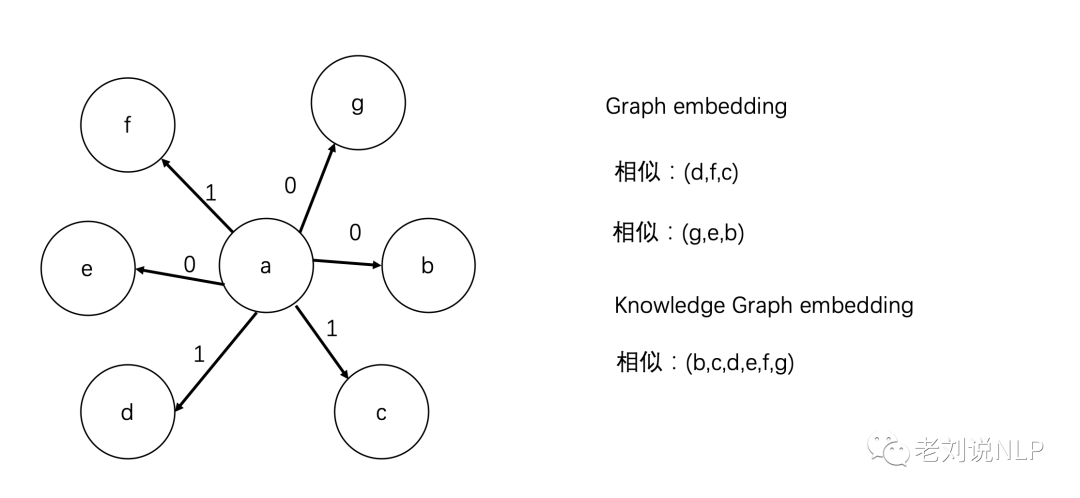
如上面图所示,给定一个图谱中,有a,b,c,d,e,f,g共7个实体,有两个关系类型0和1,两类embedding在嵌入的相似性上存在一定的差异性,例如:
Graphembedding中,相似的包括(d,f,c)、(g,e,b),其关系类型相似;
Knowledge Graph embedding中,由于b,c,d,e,f,g中都一个共同的上下文a,所以相似:(b,c,d,e,f,g)也是相似的一类。
为了说明这个问题,本文有两个目标:
一个是从理论层面来比较图网络嵌入graph embedding以及知识图谱嵌入knowledge graph embedding,就其产生方式进行介绍;
另一个是以实际的知识图谱嵌入任务出发对这两类方法进行训练,结合最终的嵌入结果进行比对说明,做理论与实践相结合。
供大家一起思考,并欢迎加入技术社区。
一、Graph embedding VS knowledge graph embedding
就图嵌入而言,分为图网络嵌入graph embedding以及知识图谱嵌入knowledge graph embedding两种。
而这两种图网络,虽然本身都是图结构,但其还是存在较大的差异点。下面援引一种种公开的观点加以说明:
“从起源看,这两个任务中最火的方法TransE和DeepWalk,都是受到了word2vec启发提出来的,只是前者是受到了word2vec能自动发现implicit relation (也就是大家常说的 king - man = queen - woman)的启发;而后者受到了word2vec处理文本序列、由中心词预测上下文的启发。
两者的相同之处是目标一致,都旨在对研究对象建立分布式表示。不同之处在于,知识表示重在如何处理实体间的显式关系上;而网络表示重在如何充分考虑节点在网络中的复杂结构信息(如community等)”。
进一步的,我们可以细分以下几点展开论述:
1、共同点与联系
两者都是表示学习,目标都是将实体或者关系或者结点表示成一个向量,用这个向量去做分类、聚类等;
知识图谱表示学习是特殊的网络表示学习;网络表示学习是更一般的知识图谱表示学习;
两种方法都可以统一在encoder-decoder的框架下,不过由于隐空间下的距离度量和设计的loss不同,模型有所变化;
两种方法的模型可以在相关任务通用,但算法性能差别较大;
异质信息网络和知识图谱都可以用图的形式进行表示。
2、学习目标上的不同
网络表示学习强调节点表示,这为下游任务节点分类,链接预测,网络重构,网络可视化等提供了方便。知识图谱表示学习强调节点之间的关系表示。
网络表示更加侧重度量图结构信息,其学习目标在于在低维空间中学习到的表征可以重构出原有网络结构,因此网络表示学习利用了网络的结构特征,之所以要将原始问题转化为图网络也是这个道理,从网络中可以发现传统方法发现不到的结构信息。学习到的表征可以有效地支持网络推断。
具体的,网络表示学习没有明显的结点之间的关系,网络中各个结点相互连接,所有结点是一视同仁。因此,更注重在嵌入空间保留(拓扑)结构信息,注重节点表示建模,之所以要将原始问题转化为图网络也是因为从网络中可以发现传统方法发现不到的结构信息。
网络表示比较注重在嵌入式空间中保留网络的拓扑结构信息,知识图谱的表示在保留结构信息的基础上,也同样注重于关系的重要性,以及它们的头尾关系。知识图谱表示学习更偏向关系建模,在保留结构信息的基础上强调关系和头尾关系,强调的是节点和关系的表示,节点和关系同样重要,因此,知识图谱表示学习中往往指明了关系,比如水果和猕猴桃之间是所属关系。
3、学习方法上的不同
网络表示学习通常包括三种:基于矩阵分解的模型,比如SVD;基于随机游走的模型,比如DeepWalk;基于深度神经网络的模型,包括CNN、RNN等;此外还有同质网络、异质网络的区分,还有属性网络、融合伴随信息的网络等。
与此不同的是,典型的知识图谱表示算法包括trans系列的算法,如TransE、TransR、TransH等,通过这个三元组去刻画实体和关系的向量表示。
二、Graph embedding与knowledge graph embedding的实践
为了对比两类嵌入在训练效果上的实际表现,我们选用一个公开知识图谱数据集进行实验,并分别利用典型的deepwalk图嵌入算法以及transe图谱嵌入算法进行处理。
1、数据来源
在之前的文章《重磅开源:面向上市公司的十万级产业链图谱构建思路与数据开放》中,老刘公开了一个节点 100,718,关系边 169,153 的十万级别产业链图谱。包括 A 股上市公司、行业和产品共 3 类实体,包括上市公司所属行业关系、行业上级关系、产品上游原材料关系、产品下游产品关系、公司主营产品、产品小类共 6 大类。
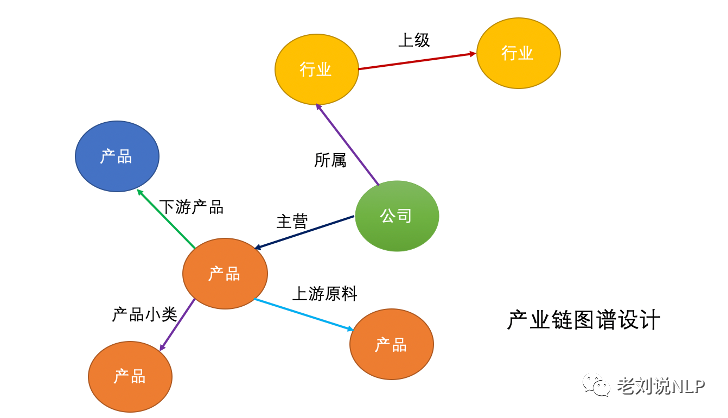
项目地址:https://github.com/liuhuanyong/ChainKnowledgeGraph
2、Graph embedding训练
github中开放了许多优秀的Graph embedding训练项目,如地址中的开源项目,给出了包括deepwalk、node2vec、struc2vec、line等经典模型的实现。
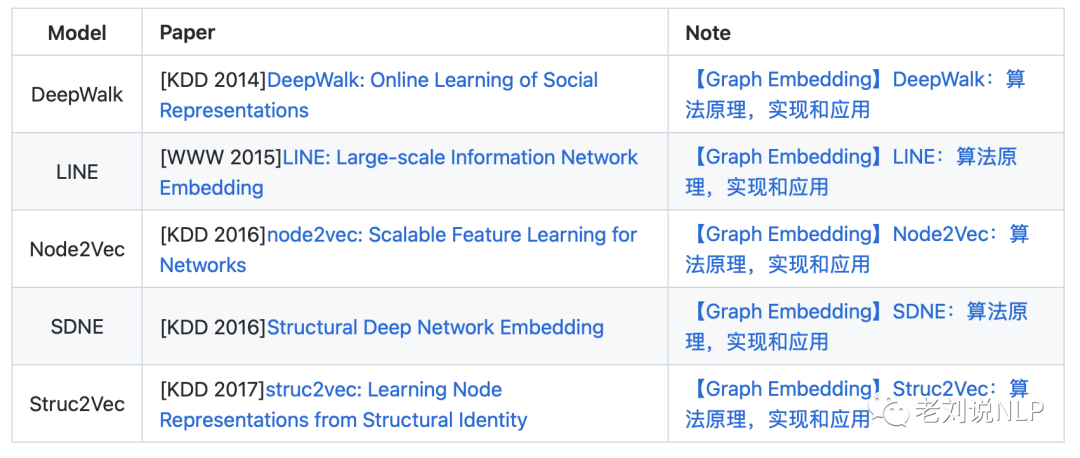
项目地址:https://github.com/shenweichen/GraphEmbedding
2、knowledge graph embedding训练
由亚马逊开源的知识图谱嵌入平台DGL-KE中,给出了当前主流的一些知识图谱嵌入模型,包括transe、transr, rotate等,并给出了很好的封装,可以一键调用。
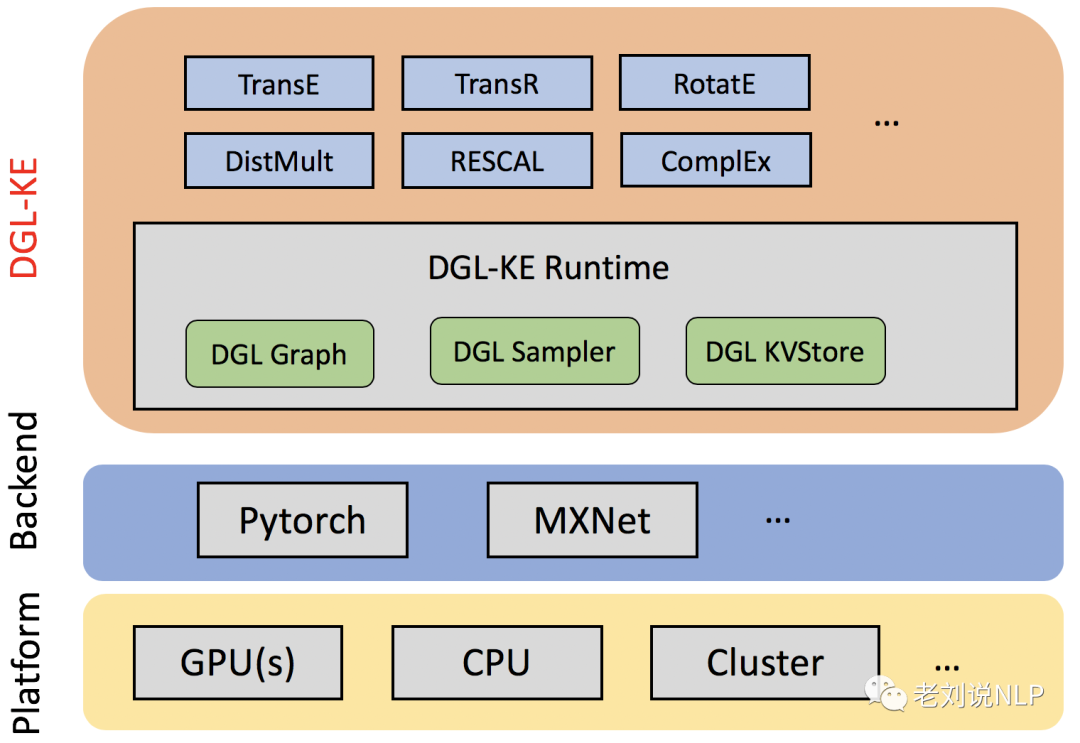
项目地址:https://github.com/awslabs/dgl-ke
三、Graph embedding与knowledge graph embedding的结果分析
通过分别构造模型所需的数据格式,并设定相应参数,即可以生成对应的嵌入结果,其中,由于DGL-KE生成的节点向量是numpy形式,不方便进行实体查询和结果比对,所以,我们参考开源工具gensim的数据样式进行构造,生成相应的向量文件,这可以作为我们进行结果分析的基础。
1、评估方式
相似节点查询是实体节点向量效果比对最直观的方式之一,通过gensim内置的model.most_similar函数,我们可以快速得到结果。
def test():
transe_path = "chain_ent_embedding_new.bin"
deepwalk_path = "deepwalk_vec_chain.bin"
model_transe = gensim.models.KeyedVectors.load_word2vec_format(transe_path, binary=False)
model_deepwalk = gensim.models.KeyedVectors.load_word2vec_format(deepwalk_path, binary=False)
while 1:
a = input("enter an wd to search:").strip()
try:
res_transe = model_transe.most_similar(a, topn=10)
print("res_transe:", res_transe)
except:
print("res_transe:", "no such word")
try:
res_deepwalk = model_deepwalk.most_similar(a, topn=10)
print("res_deepwalk:", res_deepwalk)
except:
("res_deepwalk:", "no such word")
print('*****'*5)
2、评估结果
我们通过输入任意的知识图谱实体,基于这种评估方式,得到前10个相似度最高的实体来进行展示。
由于图谱中包好行业、公司、产品等实体,因此,我们分别选择这几类实体进行验证:
1)行业类节点
下面展示了“农林牧渔”和“快递”两个行业,分别在图谱嵌入res_transe以及图嵌入res_deepwalk的结果。
enter an wd to search:农林牧渔
res_transe: [('家用电器', 0.8359084129333496), ('种植业', 0.8331279754638672), ('渔业', 0.8123003244400024), ('农业综合Ⅱ', 0.8077237606048584), ('社会服务', 0.8002400398254395), ('饲料', 0.7963002920150757), ('非银金融', 0.7957480549812317), ('轻工制造', 0.7932610511779785), ('美容护理', 0.7880131006240845), ('动物保健Ⅱ', 0.78370201587677)]
res_deepwalk: [('110000', 0.952837347984314), ('养殖业', 0.8291857242584229), ('农业综合Ⅱ', 0.8285440802574158), ('种植业', 0.8179373741149902), ('农产品加工', 0.8166170716285706), ('110900', 0.8165562152862549), ('110700', 0.8071088790893555), ('110901', 0.805849015712738), ('农业综合Ⅲ', 0.8029723167419434), ('110500', 0.7892771363258362)]
*************************
enter an wd to search:快递
res_transe: [('综合Ⅲ', 0.9114058017730713), ('其他橡胶制品', 0.9024503231048584), ('底盘与发动机系统', 0.8978883028030396), ('贸易Ⅲ', 0.895858108997345), ('调味发酵品Ⅲ', 0.8938626050949097), ('油气开采Ⅲ', 0.8924946784973145), ('硅料硅片', 0.8916640281677246), ('大宗用纸', 0.8897657990455627), ('其他种植业', 0.8896182775497437), ('其他饰品', 0.888943076133728)]
res_deepwalk: [('仓储物流', 0.8327362537384033), ('原材料供应链服务', 0.8325503468513489), ('420806', 0.8241574168205261), ('输变电设备', 0.8141449093818665), ('航空装备Ⅲ', 0.81296306848526), ('氯碱', 0.8119686841964722), ('公路货运', 0.8114577531814575), ('贸易Ⅲ', 0.8103259801864624), ('会展服务', 0.8083575963973999), ('焦炭Ⅲ', 0.8078569173812866)]
*************************
从这两个结果上看,在“快递”行业上,图嵌入res_deepwalk除了有相似的行业外,还包括了一些氯碱、输变电设备等产品节点。
2)公司类节点
下面展示了“比亚迪”和“多瑞医药”两个公司,分别在图谱嵌入res_transe以及图嵌入res_deepwalk的结果。
enter an wd to search:比亚迪
res_transe: [('中国低碳指数', 0.7312461137771606), ('3D眼镜', 0.6752729415893555), ('永高股份', 0.6689516305923462), ('ST东电', 0.6587803959846497), ('手机部件', 0.6586169004440308), ('新疆金风', 0.6519711017608643), ('ST中侨', 0.6483029127120972), ('租赁与售后服务', 0.6471531391143799), ('苏常柴A', 0.6415383219718933), ('万邦德', 0.6392924785614014)]
res_deepwalk: [('公交汽车', 0.5316087007522583), ('赛轮轮胎', 0.5296618342399597), ('300817', 0.525831937789917), ('浙江双飞无油轴承股份有限公司', 0.5145944356918335), ('新疆金风', 0.512606143951416), ('421100', 0.5095815658569336), ('厦门国贸', 0.4983369708061218), ('京新药业', 0.4946969747543335), ('中海集运', 0.4938409924507141), ('卤香火鸡翅', 0.4876548647880554)]
*************************
enter an wd to search:多瑞医药
res_transe: [('上海艾录', 0.8094831109046936), ('联科科技', 0.799593448638916), ('彩虹集团', 0.7880364656448364), ('君亭酒店', 0.7843733429908752), ('博汇股份', 0.7780767679214478), ('鸿富瀚', 0.7695952653884888), ('森赫股份', 0.753787636756897), ('泰林生物', 0.7454162836074829), ('果麦文化', 0.7449325323104858), ('兰卫医学', 0.740646481513977)]
res_deepwalk: [('中捷精工', 0.7282382249832153), ('半绝缘体', 0.6029156446456909), ('华尔泰', 0.6018751859664917), ('片剂含乳糖', 0.5897696018218994), ('科技服务', 0.5813080668449402), ('豆豉子鸡', 0.5700823664665222), ('片剂阿米三嗪', 0.5684384107589722), ('双反面面料', 0.568382978439331), ('辅料均匀混合后压制而成', 0.5565216541290283), ('原花色素', 0.5498427152633667)]
我们发现,图谱嵌入res_transe得到的更多是类型相同的结果,得到的是一个公司;而图嵌入res_deepwalk则更多的是共现上下文相似性,没有明显的区分性。
3)产品类节点
下面展示了“蜂蜜菊花茶”和“铁矿石”这两个产品,分别在图谱嵌入res_transe以及图嵌入res_deepwalk的结果。
enter an wd to search:蜂蜜菊花茶
res_transe: [('蜂蜜土豆汁', 0.8974578380584717), ('才溪蜂蜜', 0.8953100442886353), ('沁水蜂蜜', 0.8899521827697754), ('菖河蜂蜜', 0.88847815990448), ('蜂蜜', 0.8854463696479797), ('蜂蜜姜汤', 0.8825937509536743), ('蜂蜜盐水饮', 0.8820458054542542), ('蜂蜜解酒法', 0.8816487193107605), ('蜂蜜马芬', 0.8810160160064697), ('蜂蜜茶', 0.8797472715377808)]
res_deepwalk: [('蜂蜜提神饮料', 0.8896908164024353), ('蜂蜜美容法', 0.8784072995185852), ('蜂蜜膏', 0.8772760629653931), ('蜂蜜山楂饮', 0.8771719336509705), ('才溪蜂蜜', 0.8747637271881104), ('蜂蜜盐水饮', 0.8732129335403442), ('蜂蜜蒸糕', 0.8700040578842163), ('苦瓜蜜枣蜂蜜', 0.8688480257987976), ('沁水蜂蜜', 0.8688011765480042), ('菖河蜂蜜', 0.8655701279640198)]
*************************
enter an wd to search:铁矿石
res_transe: [('焦煤', 0.9499651789665222), ('纯碱', 0.9485215544700623), ('粘胶', 0.947385311126709), ('风力发电', 0.9428291320800781), ('炭黑', 0.94170743227005), ('钛白粉', 0.9395027160644531), ('板材', 0.9383281469345093), ('动力煤', 0.9348404407501221), ('无机盐', 0.9337700009346008), ('焦炭Ⅲ', 0.9337491393089294)]
res_deepwalk: [('230301', 0.929090142250061), ('铁矿石破碎机', 0.9160501956939697), ('冶钢原料', 0.9119194746017456), ('原铁矿', 0.9072051644325256), ('230300', 0.9033198952674866), ('螺纹钢', 0.8959557414054871), ('铁矿石燃料', 0.8865805864334106), ('炼铁生产', 0.8853598833084106), ('铁矿石干选机', 0.8850772976875305), ('河钢资源', 0.8794035911560059)]
从中我们可以看到,在“蜂蜜菊花茶”上,两个嵌入都结果区分度不大。但在“铁矿石”上,res_deepwalk的结果山出现了“铁矿石破碎机”等实体。
从上面的结果看,我们发现,由于knowledge graph embedding在学习的过程中实际学习的是关系类型,所以偏向于学习节点的类型相似性,体现在他们都有类似的关系类型,而graph embedding则因为采用word2vec的思想,窗口上下文一致的实体在嵌入上也彼此接近。
总结
本文围绕两个目标进行了论述,一个是从理论层面来比较图网络嵌入graph embedding以及知识图谱嵌入knowledge graph embedding,就其产生方式进行介绍;另一个是以实际的知识图谱嵌入任务出发对这两类方法进行训练,结合最终的嵌入结果进行比对说明,做理论与实践相结合。
关于Graph embedding 与 knowledge graph embedding的差异,我们需要有更多深入的分析,期待有相关的分析工作出现。
关于老刘
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
就职于360人工智能研究院、曾就职于中国科学院软件研究所。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。