

分享嘉宾:胡子牛 UCLA PHD 编辑整理:wei ai-fir 出品平台:DataFunTalk
**导读:**知识图谱是一种多关系的图结构,每个节点表示一个实体,每个边表示连接的两个节点之间的关系,可以将图谱中建模的节点和边表示为三元组。知识图谱有很强的符号化表征能力,但是还是会有不完整性,很难直接用于问答系统、语音助手等场景。神经网络可以自动抽取高语义的表征,可以更好地帮助解决各类问题。但是,神经网络缺少可解释性,将神经网络和知识图谱进行结合可以在不需要人工介入的情况下解决一些非常高层次的知识推理工作。 本文主要介绍作者过去一年中做的两个方向的工作:第一类是利用知识图谱中的结构化知识预训练神经网络模型,让这些预训练模型学习这些图谱知识;第二类工作是直接使用可微分神经网络进行复杂的知识图谱的推理工作。本文主要介绍生成式的自监督图神经网络预训练模型和可微分的知识图谱推理两方面的内容。 主要讲解内容包括一下几点: * 什么是知识图谱 * 使用知识图谱中的知识进行神经网络的预训练 * 可微分知识图谱逻辑推理 01****什么是知识图谱
1. 知识图谱
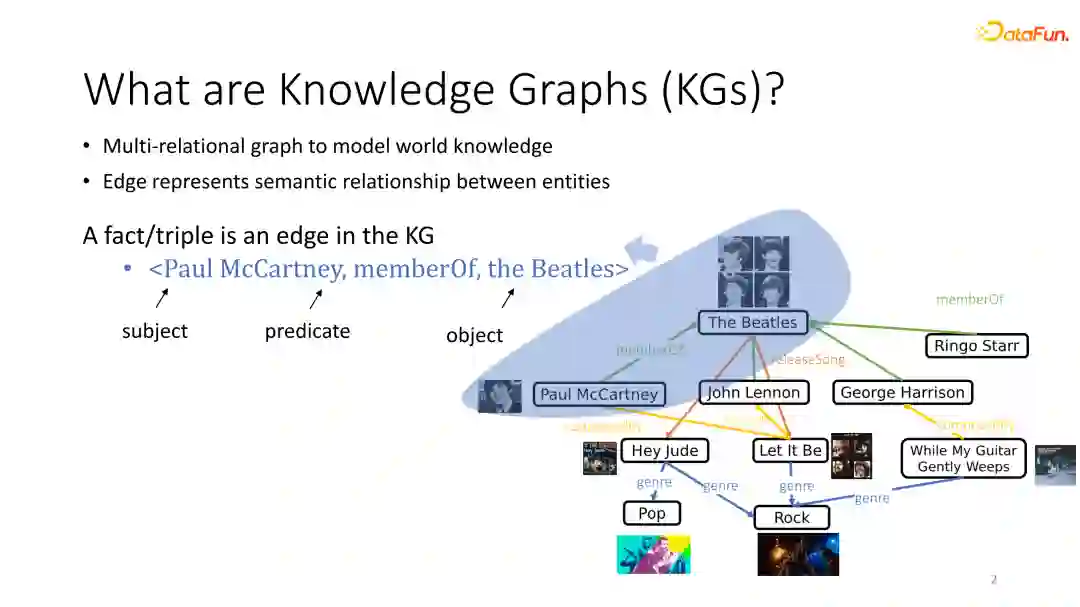
知识图谱是对现实世界的知识进行图结构建模,使用多关系图建模现实世界的知识,图中每个节点表示一个实体,每个边表示一种关系,边可以建模为众多的实体之间的语义关系,可以将实体对和对应的关系建模为三元组。
2. 知识图谱和神经网络结合

知识图谱和神经网络相结合,神经网络可以学习到知识图谱中的在结构化知识,可以将图中结构化的低阶的像素或者词信息知识自动提取出高阶的语义表征信息。02****使用知识图谱中的知识进行神经网络的预训练
1. 可生成的图神经网络预训练模型
① 什么是图神经网络
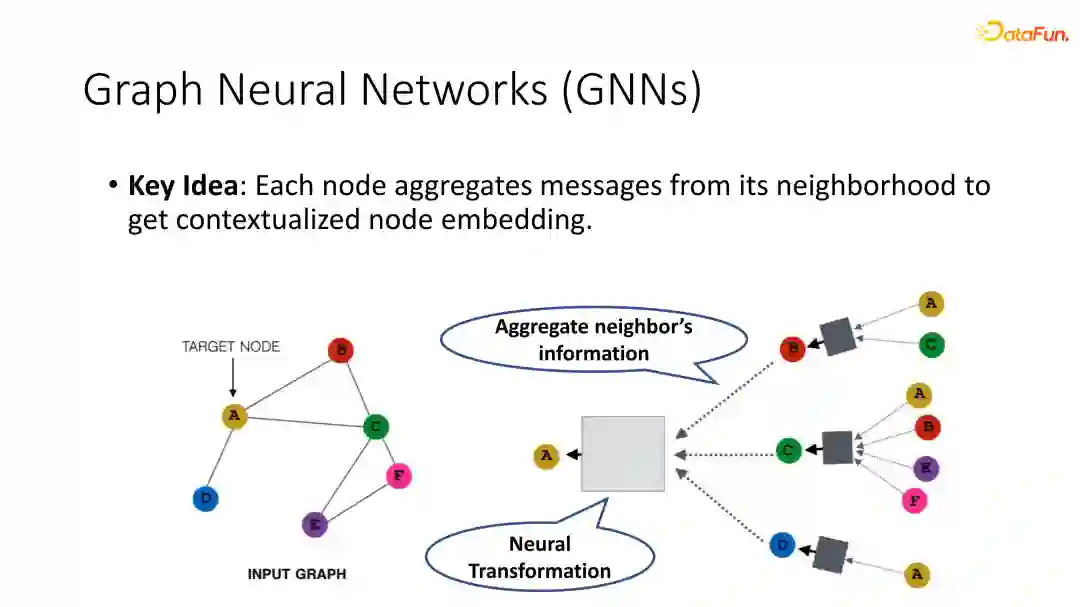
图神经网络的核心是将原本独立建模的每一个data point连接起来,考虑它们之间的一些相互之间的依赖关系,使得每对每一个节点聚集来自其邻居的信息,从而使其获得更全局并且符合语境的表征,让模型有能力去捕捉在图中的结构知识。
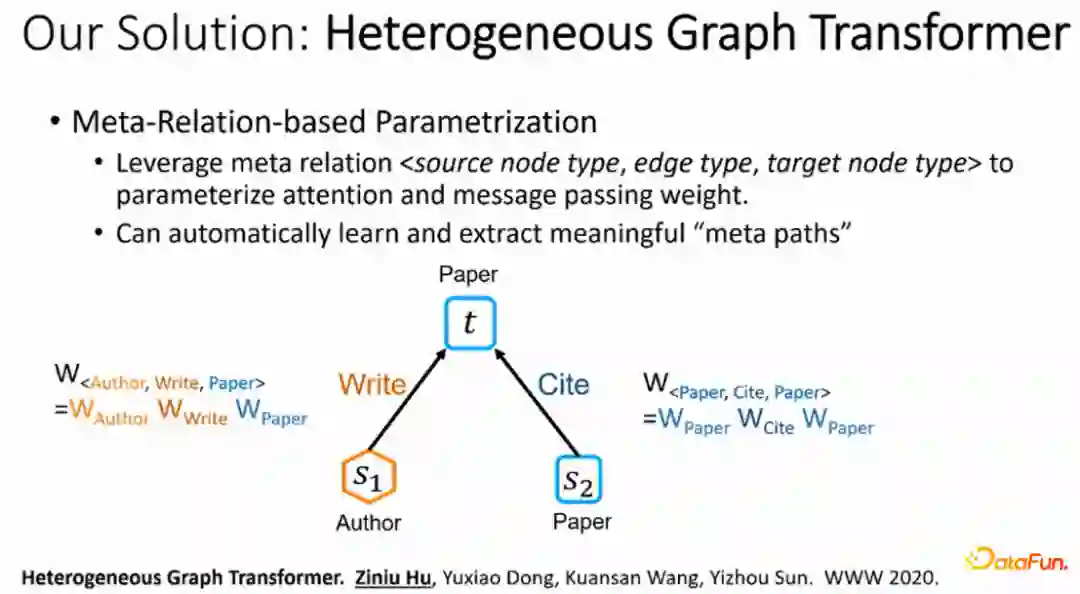
2020年,作者提出了异构图transformer模型(HGT),基本的思想是将异构图中meta relation <source node type, edge type, target node type>信息参数化为每一个从 source node 到 target node 注意力和信息传播权重矩阵,从而隐式地将图中的关系数据注入到模型当中。同时可以利用Transformer的自注意力机制,让每一个节点去选择对它最重要的邻居,自注意力机制在传播时与每个边上面的 meta relation 相关,它就和整体的图中的一些的语义是有关联的,因此除了对结果的提升以外,HGT模型不需要人为的设定就可以对每一个下游任务选取出最重要的meta path。
② 标签稀疏问题

虽然在设计HGT模型时已经将图谱中的结构化数据包含进去,但是对于推理工作依然会存在缺少大量标注数据,比如QA问答任务:
即使是最大的QA数据集也有大概1万标注的问答对并且这些标注的问答对也只覆盖了一部分的关系数据。 * 是否可以指导模型去学习图谱中的未标注的结构化知识。 * 我们提出了使用结构化知识作为自监督方式去预训练推理模型。 * 预训练模型可以提取通用的语义知识并且可以很容易地在下游任务中使用少量的标注样本进行迁移训练。
③ 图自监督方式
有没有一种方法能够使图神经网络不依赖标注数据就能够去捕捉图中的结构化知识?基于这个想法,我们设计了一个重建每一个图的生成式目标,作为自监督信号来训练图神经网络。论文的名称叫Generative Pre-Training of Graph Neural Networks,中文名图神经网络的生成预训练。论文的思想是:如果我们通过预训练使得图神经网络能够掌握图中的一些基础结构信息以及一些规律的话,很多下游任务是非常依赖于图中的结构信息,比如link prediction model.在某种意义上,就算是图结构的一些生成。Community detection某种意义上是找寻这个图当中一些重要的子结构。

④ 使用生成式预训练图神经网络模型
如果在预训练阶段就获取了整个图的一些基础性质,在迁移到下游任务时,只需要非常少量的标注数据就能实现很好地迁移。我们的基本思想是尝试让图神经网络学会如何去重建一个图或者说是生成一个图。

如果说我们能够去预测一个网络随着时间如何变迁,那么我们也能学会它的一个生成的结构模式,这对下游任务的迁移有利。
⑤ 因子分解属性图生成
这类工作的一大难点在于如何合理地建模节点特征与边的生成概率。如果简单地认为对每一个新的节点,它的边节点的信息的生成概率以及它与其他节点的连边情况的概率是互相独立的,那会有很明显的问题。比如说,我们考虑每个生成节点的attribute和它的结构没有关系的话,任何一个新的节点,它的feature或者说attribute的生成概率都是完全一样的,因为它和连边情况完全没有关系。反而言之,如果说每个节点和它的连边情况和它的输入信息没有关系的话,那么没有足够多的信息去预测它会和哪一些节点去相连。

我们提出了一种介于中间的分解方式,引入了一部分已经观测到的边,假设在任何一个新的节点中,可能会有一部分边已经被观测到。比如说它本来有十条边,我们可能已经观察到其中的三条,然后将生存的概率分解成两部分:一部分是基于已经观测到的边来去预测它的attribute,第二部分是基于已观测到的边和attribute两部分预测剩余的一些连边信息。通过随机选取可能已经观测到的边,我们就能够获取每个节点的attribute以及它的连边之间的依赖。
⑥ 生成式预训练模型的前景
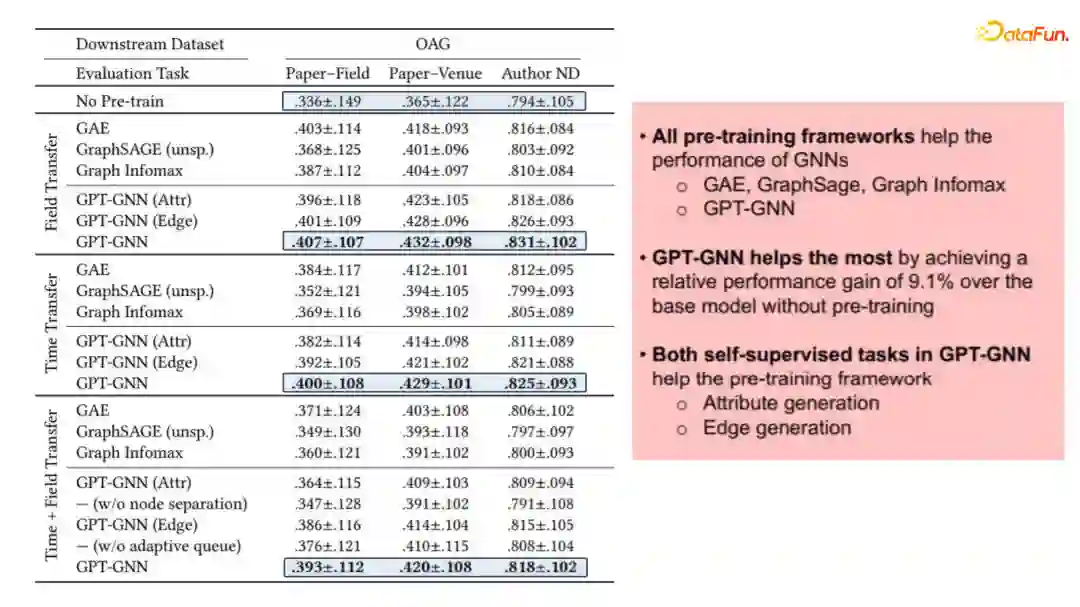
利用这一目标进行预训练初始化的图神经网络,对比它在迁移到下游任务时和其他的自监督学习的一些方法,比如和Graph Infomax和GraphSAGE一些对比,我们可以明显看出,基于重构的生成式模型的损失提升还是非常显著的。尤其和完全没有训练的baseline对比,平均取得9.1%的提升。
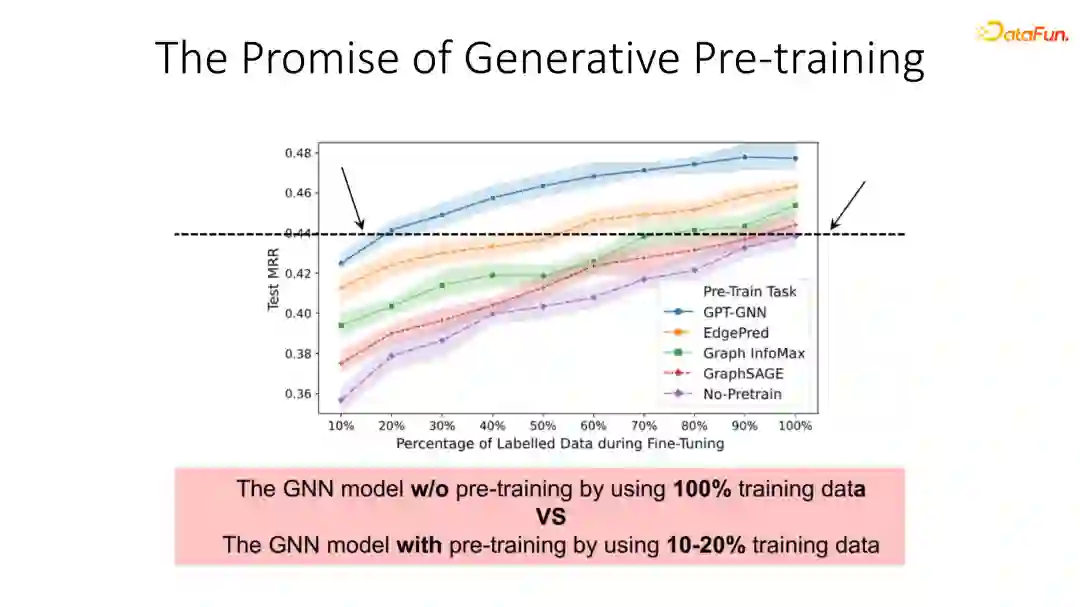
同时GPT-GNN仅需要利用10%到20%的数据上进行fine-tuning都能够取得其他模型在整个数据集上进行fine-tuning一样的效果。这表明通过这种生成式预训练方式,我们的模型可以极大地减少对下游任务标注数据的依赖。这部分代码已经开源换,换一个观看以及使用。

2. 通过wiki-graph预训练开放域问答模模型
接下将介绍如何利用类似的方法从图中信息进行预训练的工作,目标是训练开放式问答系统,这篇论文被发表在findings of EMNLP’21上。论文题目是Relation-Guided Pre-Training for Open-Domain Question Answering。
① 背景介绍
大背景是很多开放式问答需要合理的建模实体之间的关系知识,从而获得准确答案。例如,当我们想要回答哪一位作者写了《水形物语》这本书的时候,我们需要从问题当中的writer这个词来准确地捕捉到这个问题,其实想要问的是书和它的作者之间的关系。
当我们能够推测推断出问题是想知道书的作者是谁这一关系时,很多情况下我们可以直接从结构化的知识图谱当中获得答案。例如在于这个问题,可以直接从WIKIDATA中找到《水形物语》的screenwriter目标就是Vanessa Taylor这位作家。一定程度上,我们就可以利用知识图谱来做一些有利于开放域问答任务的事情。
② 问答数据集的关系偏差
通过分析,我们发现Natural questions数据集中 40% 的open domain questions可以被直接被open data当中的一些条目所回答,说明了让模型充分合理地掌握关系知识对于解决这类开放式问答的重要程度。 然而,现有的数据集关系分布非常不均匀,在Natural questions数据集中只包含了WIKIDATA当中16.4%的关系类别,其余的80%多的relation类别是没有出现在其中的。那么,如果我们想要处理的一些问题包含这些新的relation时,模型很有可能没有办法解决。同时,即使数据已经包含了这些relation,它的relation分布也非常不均衡,其中30%的relation仅出现一次。因此我们也相应分析了最终的结果和relation出现的频率是否有关系。
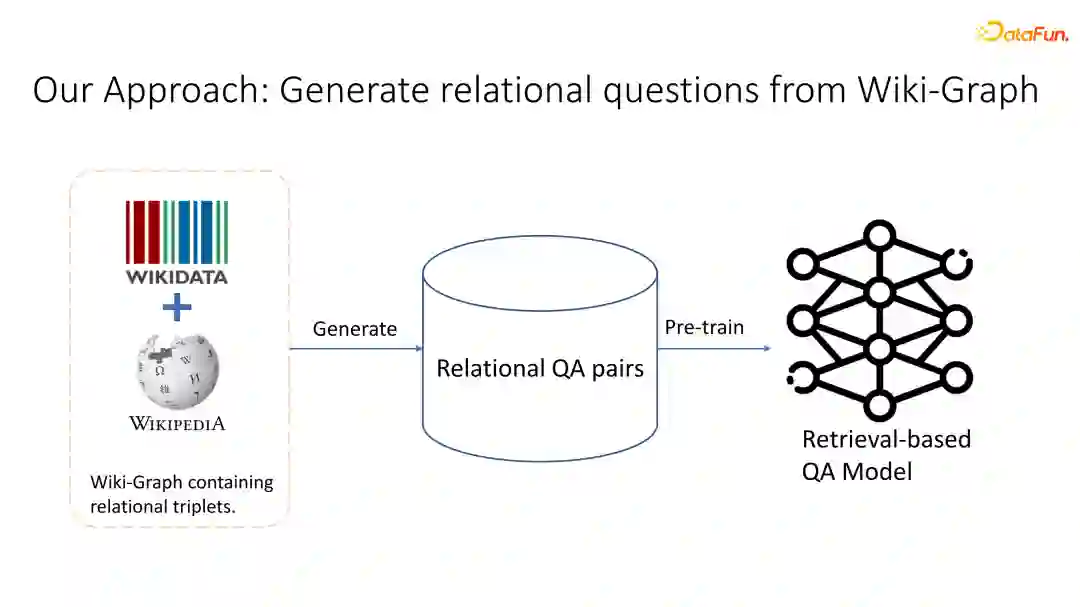
显而易见,我们发现training set中出现频率越低的relation,对应那些问题的问答最终结果也相应的较差。对于一些不频繁出现的relation,模型的结果较之平均有22.4%的下跌,这充分说明了现有数据中不均衡的关系型数据分布极大地影响了模型的泛化能力。
③ 从wiki-graph中生成关系问题
为了解决这一问题,我们自然而然可以想到,既然WIKIDATA知识图谱包含了非常多的关系型数据,那么是否利用它去生成出一些预训练的数据,基于此来预训练一个开放域问答模型,让模型取获取WIKIDATA数据中的各类关系型知识?如果我们能利用这些知识图谱中的知识生成大数据的话,就能让模型掌握更多在test set中可能会出现的一些新的关系的答案。
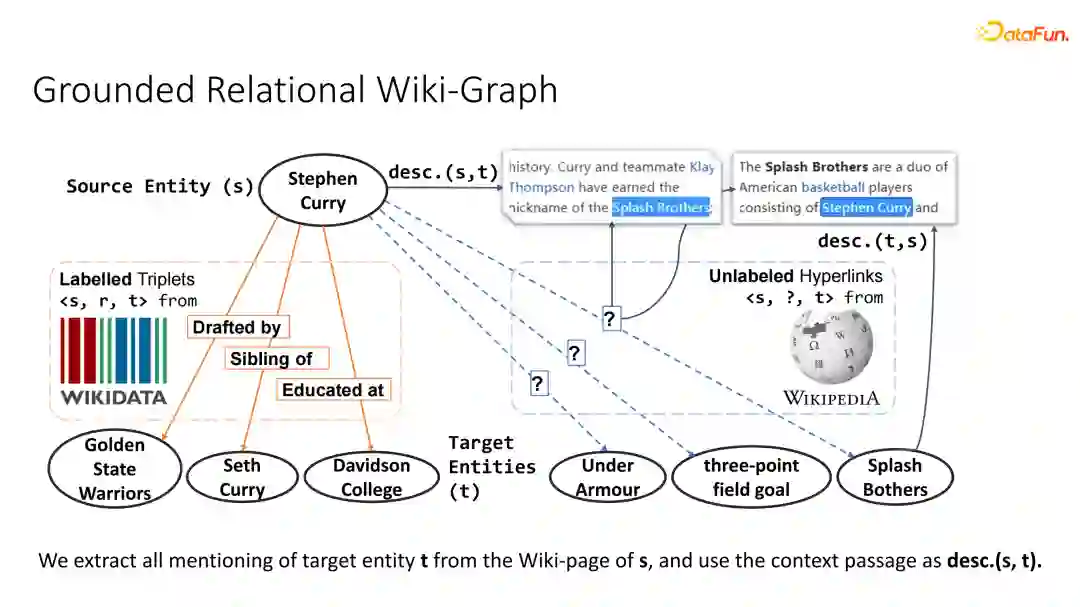
④ 真实关系的wiki-graph

第一步是将WIKIDATA和WIKPAGE两部分耦合在一起,生成一个WIKIGRAPH,其中WIKIDATA包含了很多的triplets,而WIKPAGE包含了一些triplets没有relation的hyperlinks以及对应的文本。 在这个图当中,任意两个节点的关系可能是来自Wikipedia的标注,也可能来自WIKPAGE无标注的超链接。对每条边,我们可以从起始节点的WIKPAGE当中找到目标节点的一些描述。比如在Stephen Curry和Splash Bothers之间的连边当中,我们就可以将从Stephen Curry中找到哪些句子出现了Splash Bothers,而这个句子当中的一些context信息其实在某种意义上包含了一些描述两个实体之间关系信息。同理,我们也可以从target entity比如说Splash Bothers的页面当中找到有关于Stephen Curry的一些描述,而它前后的一些context也同样包含了他们两个之间的关系。我们将这一类从起始页面找到的对目标实体的描述称为description S2T,反之称为description T2S。基于这一WIKIGRAPH我们就可以去生成关系型的问题。
⑤ 关系问答对生成
在这一处理步中,我们只利用了一个最简单的模板就已经取得不错的结果了。在描述一个问题的时候,我们可以这么去生成:对于任何一个起始的节点,在给定了一个目标页面关于它的描述description T2S的情况,我们希望这个问题能够引导模型去找到目标entity,而在一个retrieval QA 模型中,我们还需要一个true passage来包含目标entity,具体在这个工作当中,我们选取的是在起始entities中的description S2T作为true passage。
举个例子,当我们想要去生成关于Stephen Curry? Splash Bothers问题的时候,可以问出这么一个问题:[KASK(r)>] of [Stephen Curry] which [the Stephen Curry are a duo of American basketball players consisting of Stephen Curry and Klay Thompson],通过这个问题,我们希望模型能够识别出Stephen Curry以及目标Splash Bothers二者之间的relation,并且基于此找到答案Splash Bothers。

⑥ 屏蔽实体的方式防止信息短路
为了避免模型仅仅通过一些简单的词语就找到准确答案,需要从问题和段落当中去掩盖掉目标实体P以及提及实体S。具体来说,我们在question当中选取出了T2S很有可能就包含了目标答案,在这种情况下,仅通过我们找到重要的答案,模型可能就能够知道答案是什么。因此我们必须从question中把target entity T给去掉。同理,我们在true passage中为了防止只根据source entity就能找想要的passage,我们也需要将source entity从true passage中给mask掉。

**⑦ 关系指导的QA预训练模型 **
基于此生成的关系型问答数据集,可以预训练一个基于检索的问答模型。本文中选取2020年Facebook research发表的一篇叫DPR的paper作为基础模型进行预训练的实验,我们将进行relation prediction、dense retrieval、reading comprehension三部分的预训练,后面两部分和DPR原文的预训练方式基本一致,主要的区别在于第一部分。

⑧ 关系预测的预训练模型
第一部分是relation prediction,我们刚刚在生成问题过程中,发现每个问题的最开始有一个[MASK(r)]这一token,我们希望模型对于此token的输出能够预测出这一问题所需要用到的关系是什么。
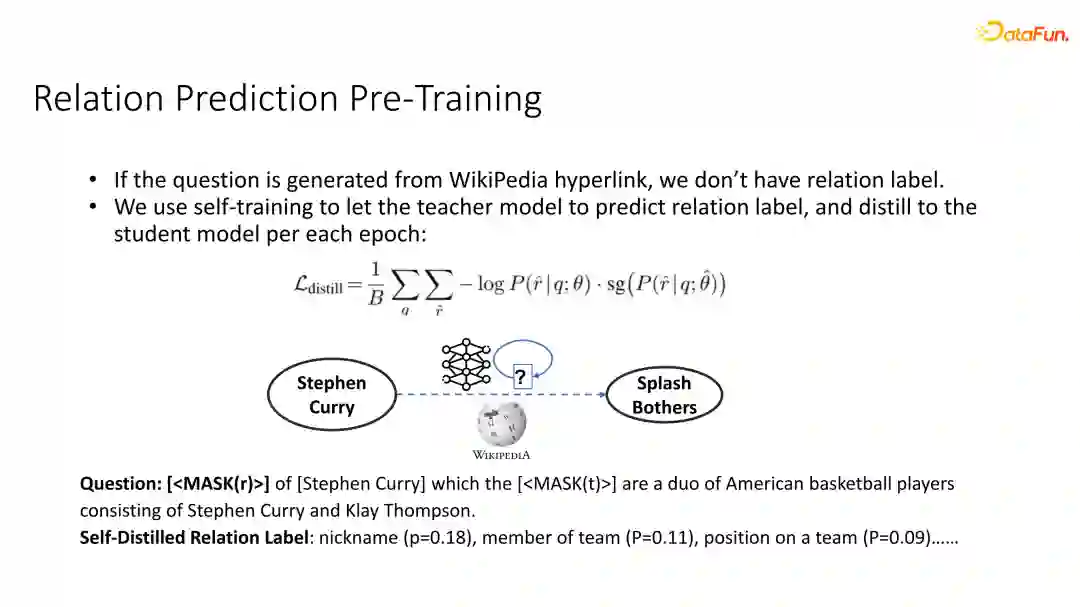
如果说我们的问题是通过WIKIDATA生成的,WIKIDATA天然具有关于relation的标注。比如Stephen Curry和Golden State Warriors之间是选秀关系,就是被招募的关系,因此我们要预测的ground truth relation 是 Drafted by,我们就可以直接通过模型的输出来预测出对应的一些question真实的relation。
然而,如果说数据是从DPR模型中得到的,那么每一条边其实是一个hyperlink,我们并不知道它真实的relation是什么。对这一类数据我们利用了一个自学习self training的方式进行训练。在每一个epoch周期,我们使用上一轮的模型作为teacher model生成关系标签,并将其作为source label蒸馏到student 模型。

例如在,关于Stephen Curry和Splash Bothers pair的问题中,我们并不知道他们真实的relation是什么。通过上一轮的模型预测出来的标签,我们可以看到预测出来的有nickname、member of team、position on a team,三个标签还比较符合这两个实体之间的一些关系,那么我们可以利用上一轮的模型的输出作为source label指导下一轮模型的学习。因为在模型中我们已经有一部分基于WIKIDATA的标注数据,因此模型可以在初始化的时候能学到一些不错的relation的prediction的结果,因此self training都能够让student越做越好。

⑨ 密集检索预训练模型
接下来是关于dense retrieval triple的预训练,这部分训练的objective和DPR基本一致,不同在于我们选取负样本时,一个很重要的准则是选取的负样本需要足够难。如果说选取是很随机的负样本,比如说基于一个question,我们随机从WIKIPAGE中选取出来一个句子的话,模型很容易就能判别出来它与question不相干。因此我们希望负样本尽可能和true passage在语义上有一定的相关联度,但同时它又不包含真实的答案。
我们的做法是可以利用图的结构信息来帮助我们获得更难的负样本。
首先我们在图上进行随机游走获得B entity,因为通过随机游走获得B entity是互连的,因此它们互相之间的语义也是相对接近的。对于每个entity,我们再随机选取出的K个passages作为负样本passages,对于两个entity来说,其中一个entity相对于另外一个来说,也是相对来说比较难的,因为这两个entity是比较接近的。通过把所有的entity的 passage拼在一起进行一个 in-batch negative sample,我们就可以获得最终的loss。
⑩ 阅读理解的预训练模型
接下来是关于reading compression pre-training,这部分和DPR的监督学习supervised training的过程基本一致,在此就不多做赘述。
⑪ 实验分析
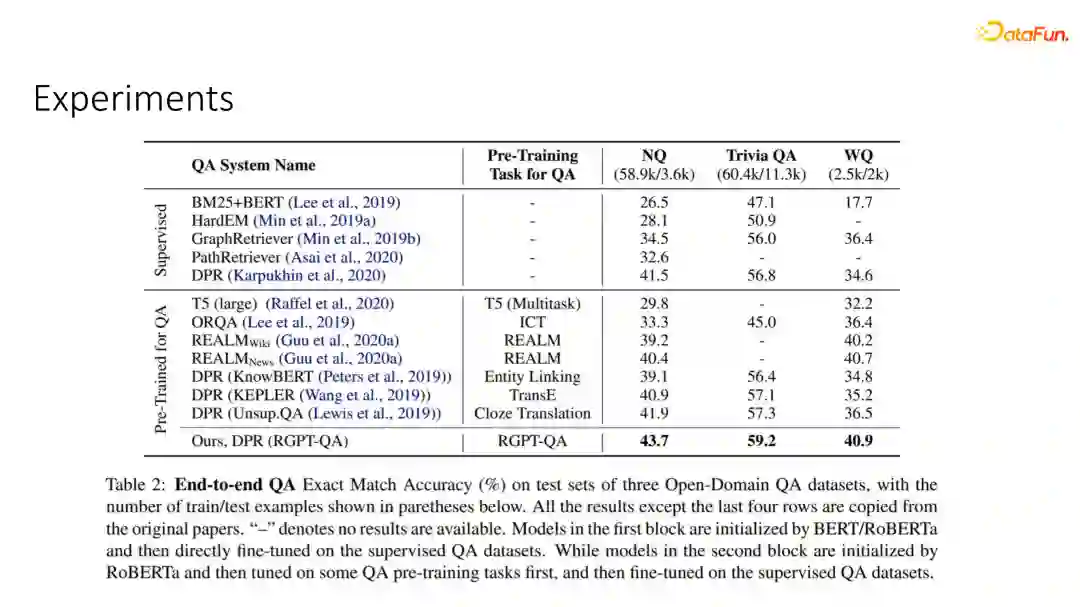
我们可以看一下最终的实验结果,除了和不预训练baseline进行比较以外,我们也和之前在QA问题上进行预训练工作包括T5、ORQA、REALM等进行了比较,我们可以发现在三个open domain QA data set中,基于RGPT-QA进行预训练的模型最终都能取得非常显著的提升。

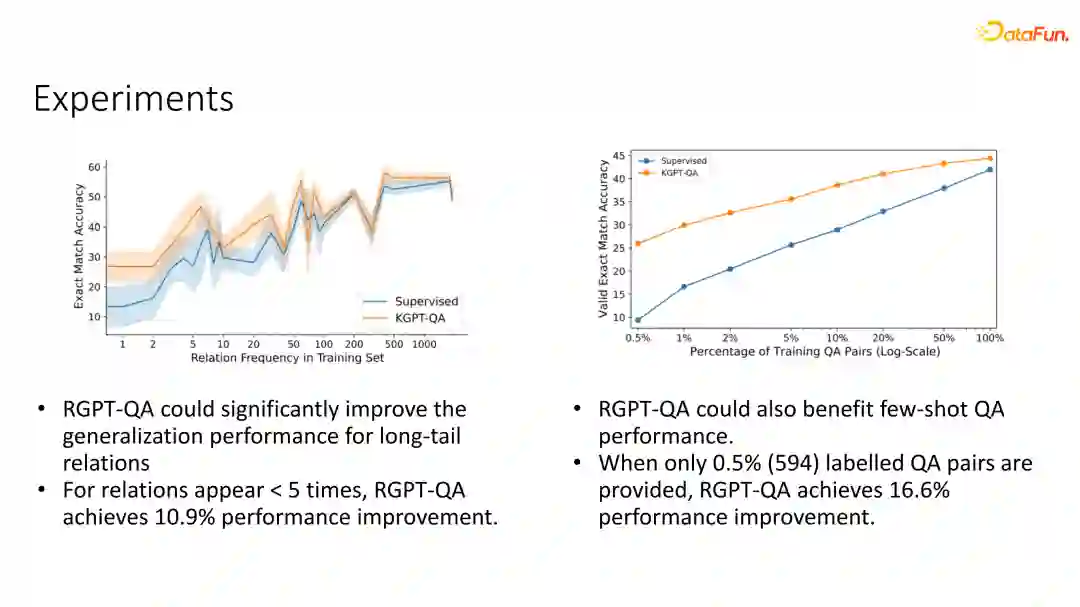
回到我们最初的分析,我们研究这个问题的初衷是对于一些出现不频繁的一些relation,模型泛化能力会比较弱,因此我们想要去分析RGPT-QA是否能够解决这个问题。

通过这张图我们可以看出,对于一些出现不频繁的,例如只出现一次两次的一些relation对应的一些问题,泛化能力的提升会更加显著,尤其是对于那些出现少于五次的relation对应的问题,我们能够取得超过百分之10.9%的高效提升。同时,和其他预训练工作一样,我们这个模型也能够显著提升少样本问答的性能,从而减少对于每一个task的标注数据的依赖。
⑫ 结论
作为总结,在这个工作当中,我们提出了一个可以将知识图谱当中的关系型事实注入到问答模型的一种预训练方式,这一方法在提升整体问答系统性能的同时,能显著提升那些出现非常少的关系的问答的结果。

03****可微分的知识图谱逻辑推理
1. 基于模糊推理的知识图谱逻辑推理
接下来介绍如何在知识图谱上进行可微分的逻辑推理。比较有意思的一个工作叫fuzzy logic based logical reasoning on KG。这论文的标题是fuzzy logic based logical query answering on knowledge graph。
① 面临的问题
我们想解决的问题是在知识图谱上进行一阶逻辑的推理。例如一个问题是:列出所有从未举办过奥运会的欧洲城市的总统。为了完成这一查询句,除了要准确地进行关系建模,也就是我们上一节工作想要处理的问题以外,模型还需要进行一些逻辑操作,例如与或非。
传统的方法通常是采取在知识图谱上进行游走的方式来搜索最终的答案,但这种方法会有两类很明显的问题:一类是时间消耗非常大,尤其是对于一些关系和节点数非常多的知识图谱,随着query长度增加,游走的时间开销是指数级增长的。

第二个非常明显的一个问题,即大多数knowledge graph是不太完整的。因为它不太完整,当我们在问题中包含的某个relation在KG当中不存在的时候,这一类的query就完全没有办法被回答。
② Answer the FOL Query by Query Embedding
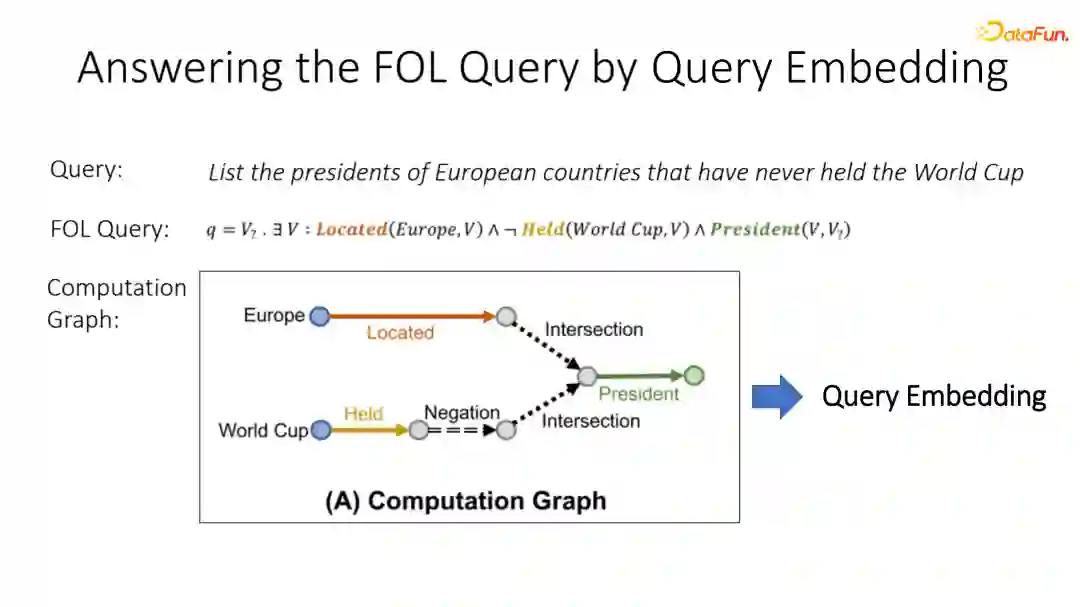
为了解决这些问题,近年来有一系列称为query embedding的工作,他们的基本思想是将一个复杂的FOL query先转化成一个computation graph。

例如图中FOL query ,我们可以将它的所有node取出来,它与目标的一些entity mentioned node 之间 relation 可以作为一条边。如果说它只包含操作,那就自己到自己;如果包含一些union exist操作, 就将若干个节点合在一起生成一个新的节点。
通过这种computation graph建模,我们可以将一个复杂的逻辑查询串转化成一个类似GNN foreword path一样的东西。如果我们能够像GNN一样,获得每个节点的表征以及每个边上的projection的表征,我们就可以将一个逻辑逻查询串转化成一个continuous embedding,在回答逻辑查询串的时候,不需要进行搜索,只需利用一个continuous embedding和现有KG中每一个entity embedding进行相似度计算进行top搜索,就可以直接在O(1)时间内找到答案,而不需要进行非常复杂的搜索。
③ 现有的方法
同时,由于实体的embedding在 continuous space里的similarity是可以去inference一些missing edges,哪怕我们在KG中有一部分边是不存在的,只要我们embedding足够好,我们也能够复原回那些缺失掉的边,因此这一类的工作可以去解决这种问题。

这一类的query embedding有其缺陷。
第一,在所有这些快query embedding工作中,每一个logical operation都是被特定的neural network建模的,并且它也有对应的一些参数,那么为了训练好每一个对应的logical operation,他们需要有非常大量的、准确的complex first of logical queries作为训练数据,才能够得到非常准确的逻辑推理,这极大地限制了这类工作在真实场景里面的应用,毕竟在真实的数据集里面,很多情况下并不会拥有这么多的准确的first of logical queries。
第二个问题是,我们在工作当中发现了之前设置的很多逻辑操作并不符合基本的逻辑操作公理,因此他们在处理逻辑操作的时候会出现一些fundamental的错误,从而影响他们的推理性能。

④ Logical laws and model properties逻辑规则和模型属性
这部分我们不多展开,大家感兴趣的可以去看我们paper。简单来说就是我们根据一些logical law最基本的性质总结出了query embedding 需要符合的对应的一些性质。在这里总共有八条性质。
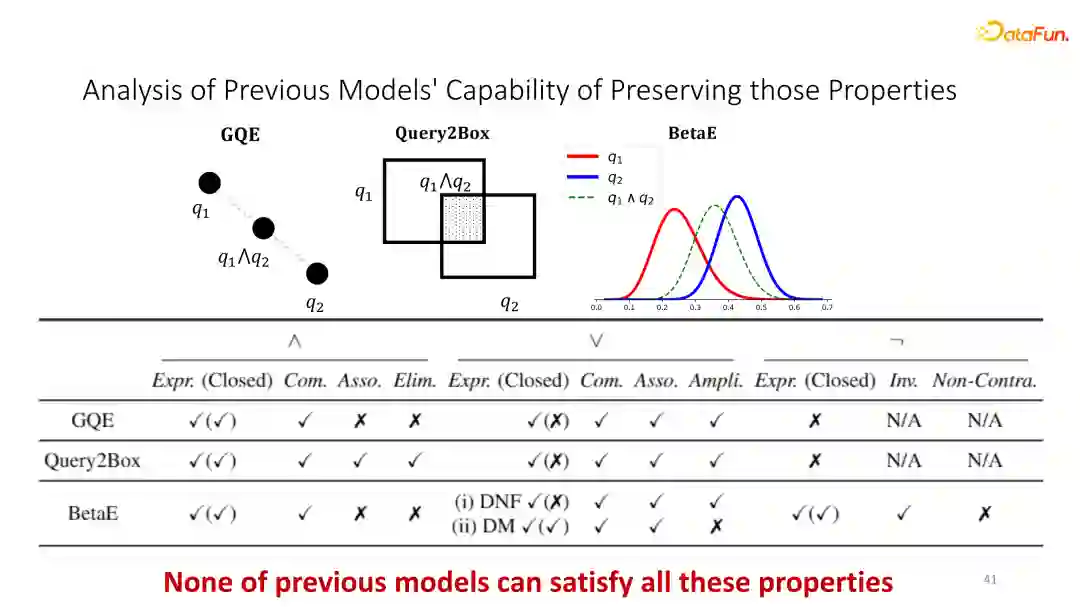
⑤ 模糊逻辑模型性质对比
我们同时做了一个理论分析去判断之前的所有 query embedding 是否符合其中的每一条logical law。有研究者指出每一个query embedding的工作都或多或少缺失掉其中的某一些性质。

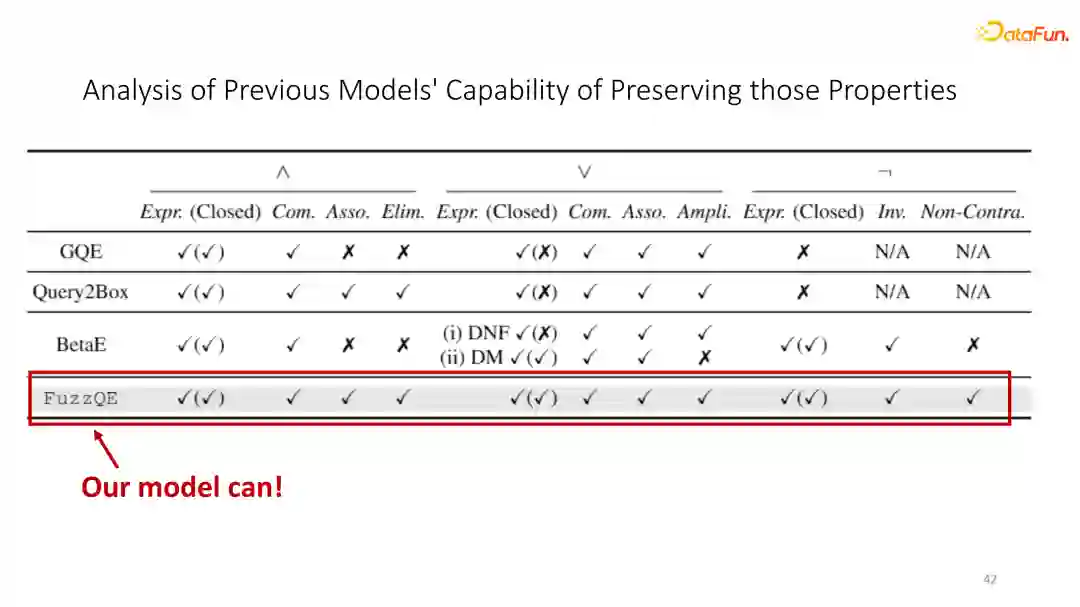
基于这一些challenge,我们提出了一个 fuzzy logic 新的 query embedding 模型。这一模型借鉴了 fuzzy logic 的基本操作来实现逻辑运算,且这些操作没有我们不需要的任何的额外参数,意思就是说我们再去进行逻辑运算的时候,我们是不需要额外的标注数据来进行学习的,只要模型的 entity embedding 和 relation prediction 足够好,就可以直接进行任何复杂逻辑推理。
⑥ 我们的FuzzQE模型
同时,由于fuzzy logic operation本身的性质,我们的模型天然地符合了之前提到的所有的基础的逻辑规则,从而从本质上提升推理的结果。

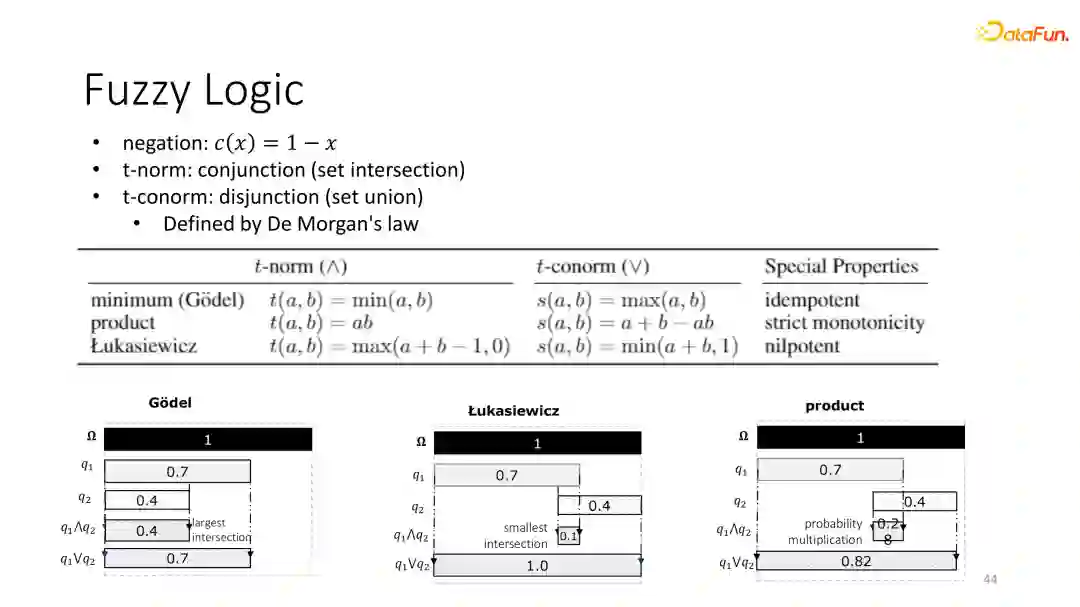
⑦ 模糊逻辑
我们工作的核心是基于t-norm based的fuzzy logic,可以推导出不同的逻辑运算。在本工作当中,我们主要选用的是Product fuzzy logic,因为它实现起来比较简单,所有这些操作都符合之前提到的的logic law,这是被t-norm logic 本身的性质所证明的。

⑧ 基于模糊逻辑的问题嵌入
我们将每一个查询语句和对应的答案集合预设为Sq,也就是一个向量,其中的每一个元素被映射在零到一之间,从而方便进行fuzzy logic 的operation,而每一个实体是否属于其中某一个集合,我们可以表征为一个embedding和Sq之间相似度,也可以被表征为一个概率。

⑨ 模糊逻辑的问题嵌入方法
对于关系型建模,我们借鉴了RGCN的设计,将关系矩阵分解成多个base matrix的加权之和,并在数据输出层利用logistic activation转化到零到一之间,辅助我们之后的一些操作。
所有的logic operation都是最基础的不需要额外参数的两个set embedding之间基本操作。比如基于product的logic时,与逻辑操作就是直接的点乘,或逻辑就是A加B减去A乘B,非逻辑就是1减去S。利用这些逻辑operation,只要模型拥有足够好的基础的entity embedding和relation projection,它就可以直接泛化任何复杂的逻辑推理。
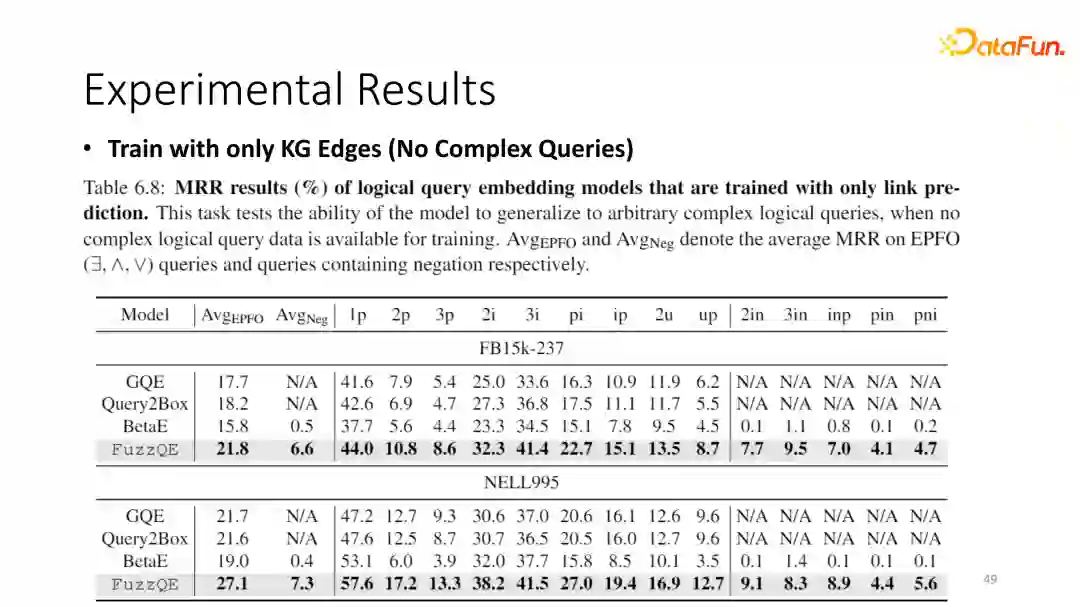
⑩ 实验结果
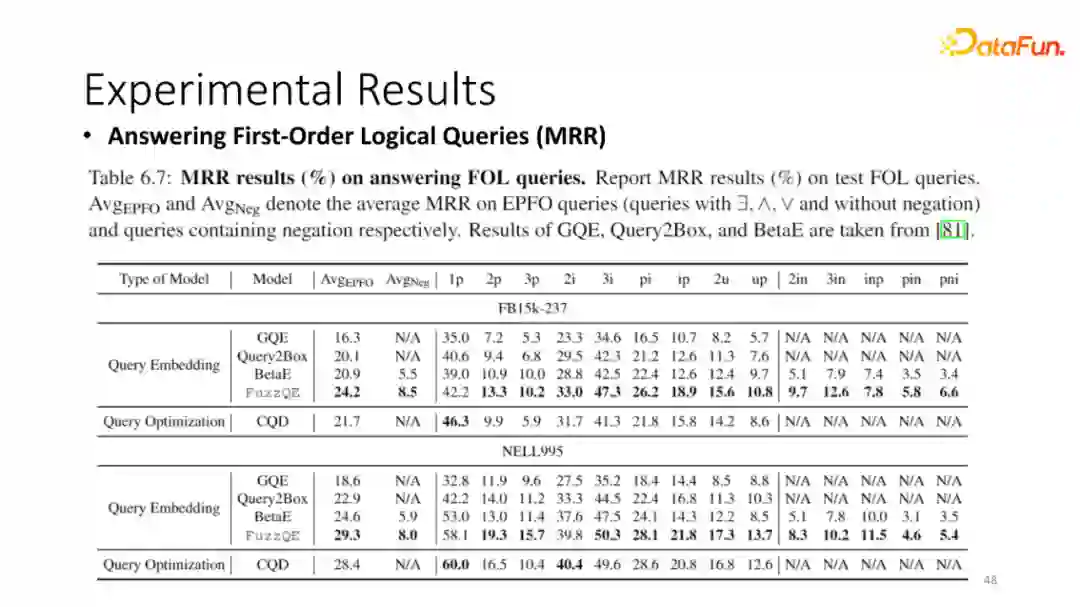
为了验证我们模型的表现,我们首先在标准的数据集上,也就是包含了很多complex fol query的数据集上进行训练。可见 fuzzy logic query embedding 的结果相较于之前的 query embedding 工作有非常显著的提升,并且它与best paper就是耗时较长的CQD paper也有非常接近的结果。同时,我们可以解决包含在内的所有的逻辑操作。

我们重点提到了框架的逻辑操作是不包含任何参数的,理论上只要模型拥有足够好的entity embedding和relation prediction参数,我们就可以直接进行逻辑推理。为了验证这一点,我们对每一个KG只利用了它的edge去训练entity embedding和relation prediction,而不利用任何的复杂逻辑作为训练数据训练每一个模型。
对于所有的baseline,我们选择一些非常简单的操作替换掉他们的一些parameter。从结果可以看到,我们的方法基本可以获得跟之前运用所有Fuzzy logic query得到的模型比较类似的结果。
例如之前我们fuzzy QE的结果是24.2,而betaE模型是20.9,当我们只用edge embedding 训练的时可以达到21.8,也就是即便只用了它的边信息,我们也能得到运用了所有query作为训练数据的betaE的结果。同时,我们相比于其他的所有的baseline,当他们在只有edge作为训练数据的情况下有非常显著的提升。

⑪ 总结
作为总结,我们提出的fuzzQE符合所有最基本的逻辑公理,并可以在没有复杂语句作为训练数据的情况下能取得很好的结果。当然这个工作暂时还是只在knowledge graph上进行推理,我们接下考虑能否将工作运用到真实的QA set去处理一些需要复杂的逻辑推理才能解决的问答数据。

