AAAI'21 | 对比自监督的图分类
Contrastive Self-supervised Learning for Graph Classification
论文地址:
https://arxiv.org/pdf/2009.05923.pdf
论文来源:AAAI 2021
1.论文介绍
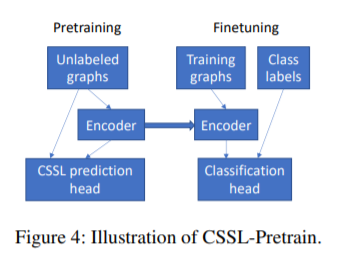
图分类是一个重要的应用,在现实中,带标签的图数量很少,导致模型的过拟合。本文提出了两种对比自监督学习的方法来避免这种过拟合的现象。一种方法先是在无标签的数据集上做预训练,再在带标签的数据集上做微调。
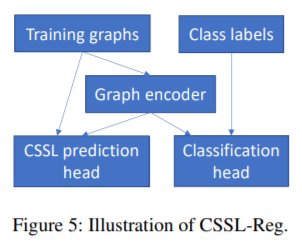
另一种方法是同时进行监督的分类任务和无监督的对比学习任务。
2.模型方法
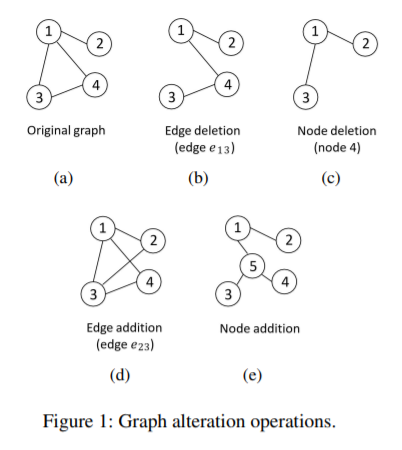
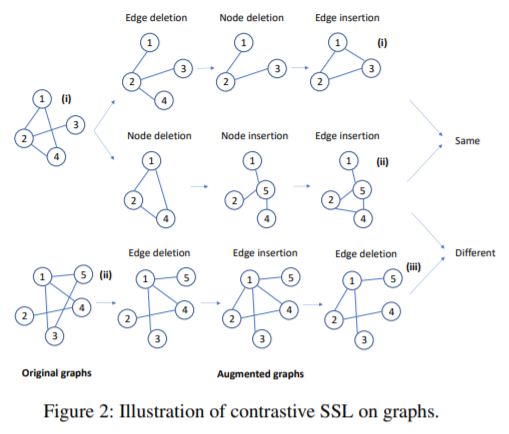
在对比学习之前要先对图进行数据增强,本文使用了四种方法。删除节点和边以及增加节点和边。在增加节点时,从图中选择一个强连通的子图(1,3,4),删除掉所有边,加入一个新节点(5),将新节点与子图的所有点相连。
每次数据增强时,从操作集中随机选择一个数据增强操作,经过t步迭代,最终得到一个增强后的图。如果两个图是由同一个图增强得到的,那么这两个图的标签应该相似。本文使用了一个图嵌入模块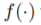
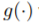
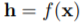
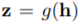
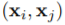
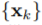
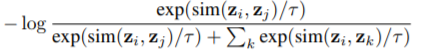
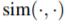
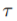
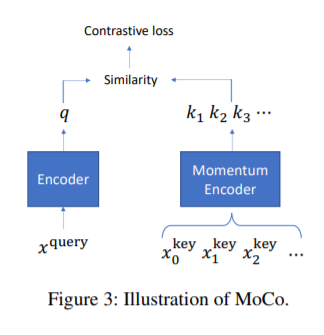
优化损失函数时,作者使用了MoCo的方法。一个队列中包含了一个增强后的图的集合,每次迭代将最近的一批图加入到队列中,最老的一批图出队。这些图使用动量编码器进行编码。给定一个增强后的图,如果与当前队列中的一个图来自同一个初始图,那么它们是正样本对,否则为负样本对。
本文提出了两种方法来避免过拟合。一种方法是在无标签的数据集上做预训练,再在带标签的数据集上做微调。
另一种方法同时进行监督任务和自监督任务。
优化问题表示为
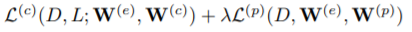
D表示训练图,L表示标签,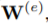
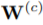
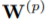
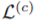
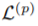
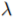
本文使用的图编码器是Hierarchical Graph Pooling with Structure Learning(HGP-SL),由图卷积和池化层构成,
3.实验结果
作者在多个数据集上与现有方法进行了比较
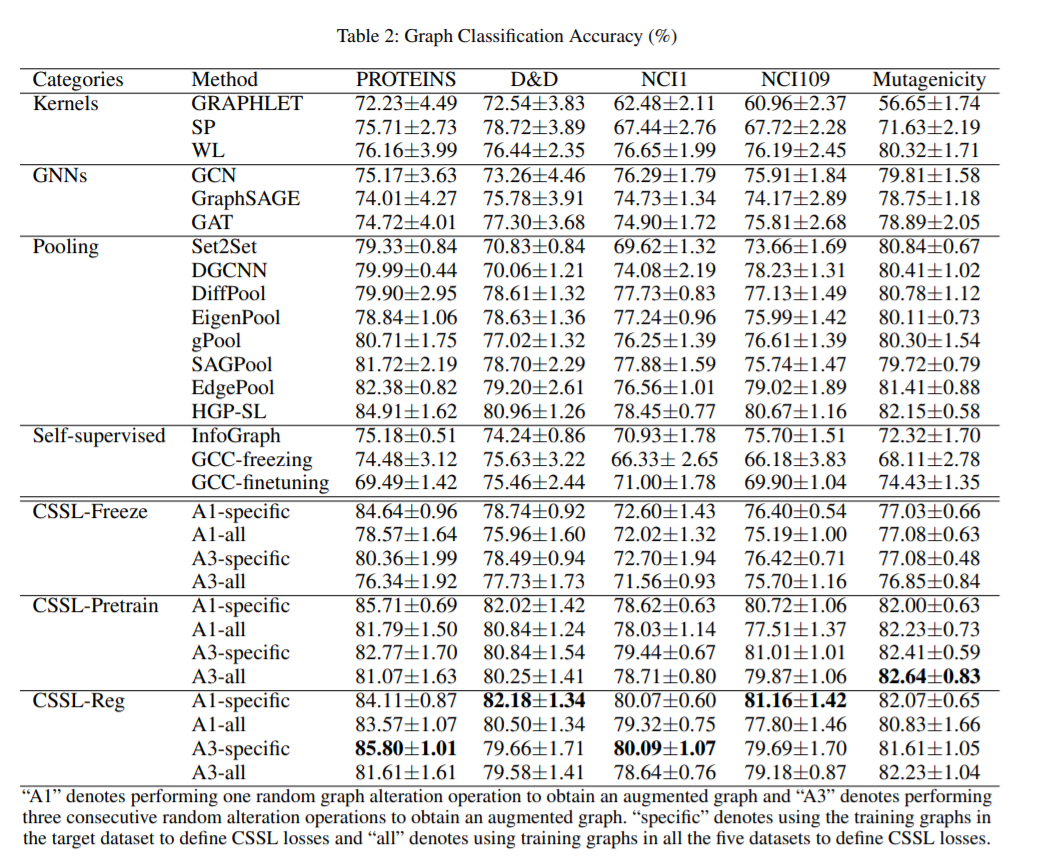
CSSL-Freeze表示预训练后直接用到分类任务中,不进行微调。
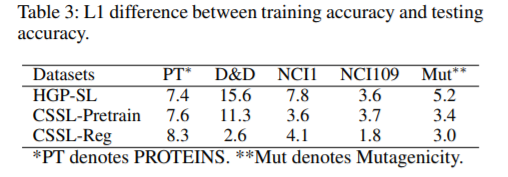
对不同的增强操作,作者也进行了比较
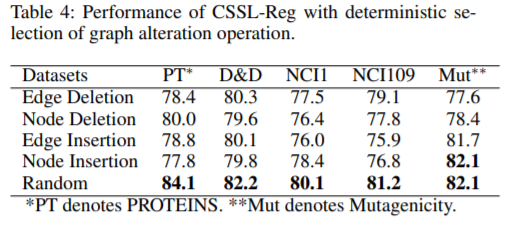
在CSSL-Reg方法中,不同的
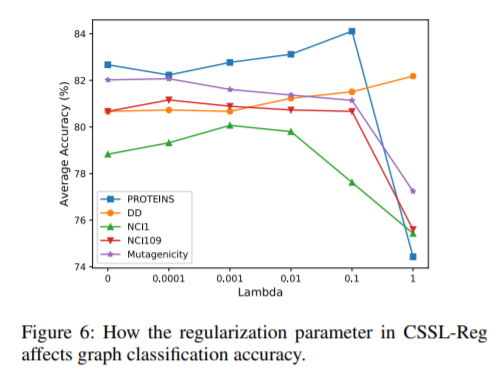
4.总结
本文在图分类任务上使用了对比自监督学习的方法,提出了两种不同的方法,与现有方法相比,本文方法有效的避免了图分类过拟合的问题。





