Word2Vec 与 GloVe 技术浅析与对比
前言
学习word representation的模型主要分为两类:以LSA (latent semantic analysis)为代表的global matrix factorization methods,也称为 count-based methods; 以及以word2vec为代表的 prediction-based methods。哪类模型的性能更好,自然成为了人们关注的焦点。最近,有学者的实验证明prediction-based methods在多种任务上都具有更优秀的表现。后续提出的GloVe[1] 模型,结合了count-based methods 和 prediction-based methods 的优势,在性能上超越了Skip-Gram[2]、CBOW[2] 等经典的prediction-based methods。
本文主要分为4部分:
(1) 简要介绍count-based methods和prediction-based methods的特点;
(2) 从基础的模型目标函数角度对 GloVe 和 word2vec 进行对比,得出的结论是二者本质上是类似的,但word2vec模型中包含些许缺陷;
(3) 分析证明GloVe的模型的计算复杂度小于word2vec;
(4) 列举在三种任务上的实验结果,对前述分析进行了验证。
(1) 两类主要模型
Count-based methods 以矩阵分解方法为基础,通过对包含整个语料统计信息的矩阵进行分解,得到每个单词对应的实数向量。例如LSA (latent semantic analysis)是对一个“term-document”矩阵进行分解;HAL(Hyperspace Analogue to Language) 对一个“term-term”矩阵进行分解。这类方法的缺点在于,它较难学得词之间的类比关系。
Prediction-based methods 使用一个在语料上滑动的窗口进行学习,主要包含两种方式:
(1) Skip-Gram: 使用当前词预测它的context words;
(2) CBOW: 使用context words 预测当前词。
这类方法的缺点在于没有直接利用语料的统计信息。
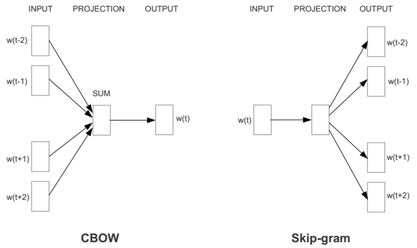
(2) GloVe model vs. Skip-Gram model
Cost function of GloVe:



与 word2vec cost function 的关系
Skip-Gram的目标是随着窗口在语料上滑动,最大化word j 出现在 word i context中的概率(Qij),故其目标函数可表示为:
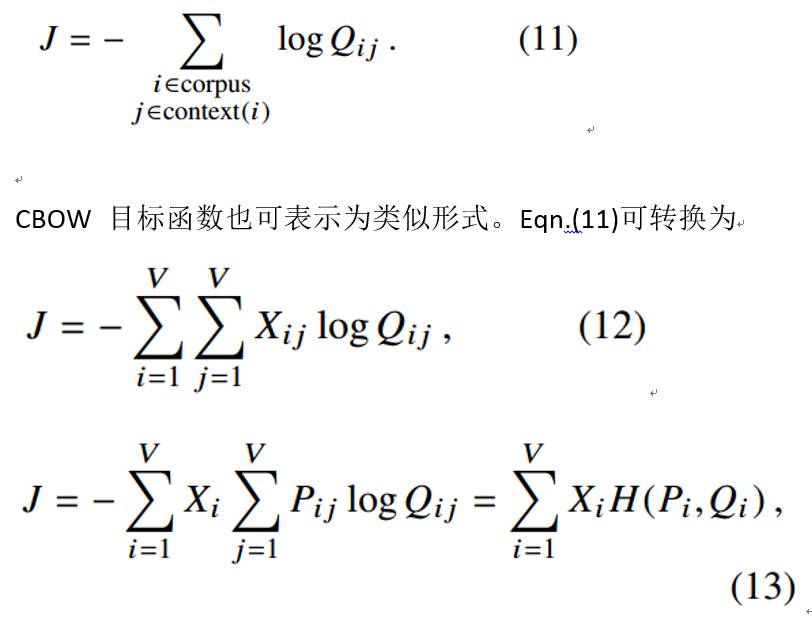

十分类似,即二者并无本质差别。
(3) Complexity of the GloVe model
GloVe 的计算复杂度主要依赖于X矩阵中的非零项,所以不会超过O(|V|^2),但 |V|^2 通常是一个远大于语料词数的值,所以需要为X矩阵的非零项寻找一个更小的上界。
我们假设 X_ij 可以表示为以下形式,其中 r_ij 表示单词对的frequency rank。


(4) Experiments
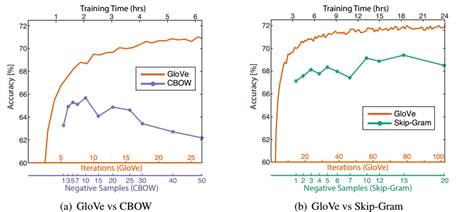
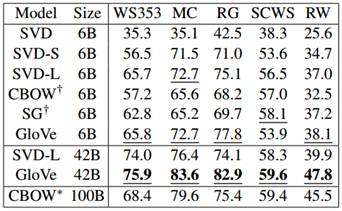
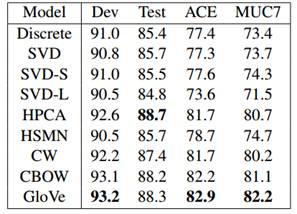
实验在word analogies、word similarity、named entity recognition 三个任务上对GloVe 、Skip-Gram、CBOW 以及其他baseline进行了对比,GloVe在大部分情况下都超过了其他模型的性能。
Word analogies result
Spearman rank correlation on word similarity tasks:
F1 score on NER task:
总结
虽然前述内容论证了GloVe模型相对于word2vec的优势,但有些学者的实验结果[3]表明GloVe并非总是能更胜一筹。所以对于具体的数据集适合使用哪种模型,还需要我们亲自做实验来验证。
猜你喜欢
参考文献
[1] J. Pennington et al. Glove: Global vectors for word representation. EMNLP, pages 1532–1543, 2014.
[2] Tomas Mikolov et al. Efficient Estimation of Word Representations in Vector Space. ICLR Workshop, 2013.
[3] Omer Levy et al. Improving Distributional Similarity with Lessons Learned from Word Embeddings. Transactions of the Association for Computational Linguistics, 3 (0), 211–225, 2015.





