【论文笔记】韩家炜团队无监督主题分类构建法
【导读】本篇论文是KDD2018韩家炜团队发表的一篇论文:基于自适应术语嵌入和聚类的无监督主题分类构建法,初次阅读,后续会结合代码进一步加深理解。
创新点:现存的基于模式的方法将每个术语视为独立的概念节点,这样会忽略主题之间的邻近性和语义相关性。为了解决这个问题,作者提出了一种构建主题分类法的方法。其中每个节点代表一个概念主题,并被定义为语义相关的概念集群。
方法:使用嵌入和聚类以递归方式构建主题分类。
现存方法中的每个节点表示的是独立的内容,通过获取上下位词对来分类,虽然准确率较高,但是会出现覆盖率低、高冗余、信息量低等问题。
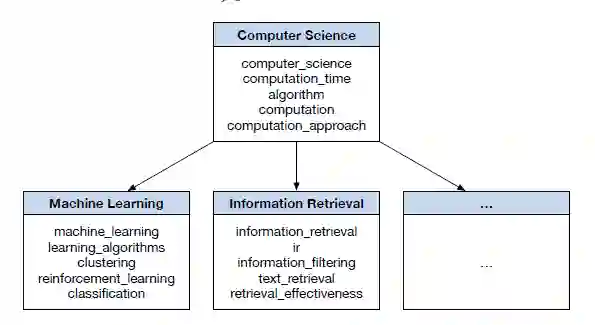
作者在论文中提到采用主题分类法,每个节点代表一个概念性主题,即语义上一致的概念性术语集。也就是说,对于“信息检索”主题,它的相关术语还包括“文本检索”“ir”等等。
在构建主题分类法时,采用名为TaxoGen的无监督方法。它将概念术语嵌入到潜在空间中以捕获其语义,并使用术语嵌入基于层次聚类来递归构造分类法。在此过程中,存在两个挑战:
确定不同概念的适当级别并非易事,父节点拆分时,并非全部都适合细化成子节点。
在较低级别上的全局嵌入的判别力有限。比如,在细分“机器学习”主题时,发现“机器学习”与“强化学习”的全局嵌入比较相似,因此划分机器学习主题时会有点困难
TaxoGen中的两个模块来解决上面提到的两个困难,分别为自适应聚类模块和局部术语嵌入模块。这两个会在后边详细介绍。
主要贡献:
采用递归方法构建主题分类
提出自适应聚类模块来划分模糊话题的等级
提出局部嵌入模块来提高嵌入识别能力
在真实数据上验证TaxoGen的有效性
此部分回顾现存的分类构建方法:基于模式的方法;基于聚类的方法和有监督方法。

基于模式的方法
基于模式的方法通常用来构造上下位分类法,首先使用预定义的词汇模式从语料库提取上下位词对,然后将所提取的对组织到分类树中。这种方法在查找基于手工规则或生成模式的关系方面十分有效,然而,对于构建主题分类却并不受用。主要原因在于:首先,主题分类法中的每个节点是代表概念性主题的一组术语;其次,由于基于自然语言的亲子关系表达差异很大,基于模式的方法通常会降低召回率。
基于聚类的方法
聚类方法与主题分类相似,通常,聚类方法先学习词的表示,然后根据它们的相似度和聚类分离将它们组织成一个结构。TaxoGen中的局部术语嵌入与现存的方法不同。首先,不需要给上下位词对标签;其次,仅使用与主题相关的文档来学习每个主题的局部嵌入。局部嵌入可以很好地分离具有细微语义差异的术语。TaxoGen中的自适应聚类模块将模糊的话题划分到适合的等级,这个模块将同一主题的术语归为一组,并以较大距离分割子主题。
有监督方法
通常,这种方法会根据上下位词对的训练数据,或从NLP工具中获取的上下文信息提取词特征并将术语对分为关系或非关系。此方法的最新技术利用了预训练的词嵌入,并学习关系分类器。但是这些方法的训练数据仅限于提供上下位词对的关系,并不能轻松地构建主题分类法。此外,对于特定领域的文本数据(例如文本中使用的科学出版物数据),几乎不能从专家那里收集到丰富的监督信息,因此,作者专注于无监督分类法构建中的技术发展。
构建的主题分类的输入包括两部分:文档语料库D和种子术语集T。论文中的T是由D中提取的常用名词短语。通过给定的D和T,来构建树形结构H。每个节点C表示一个概念性主题,用一组术语Tc∈ T来描述。节点C有一组子集合SC = {S1, S2, . . . , SN },每个Sn为C的子主题。
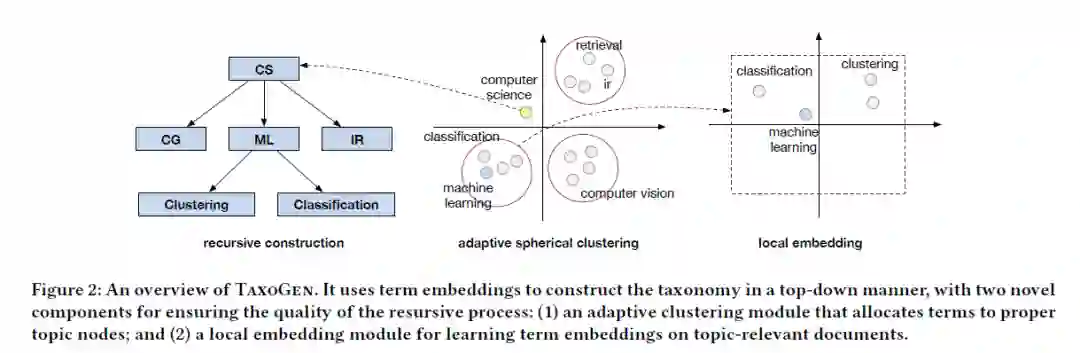
TaxoGen将所有的术语嵌入到潜在空间以获得其语义,然后进行递归分类。如上图,首先初始化包含T中所有术语的根节点,然后通过自上而下的圆形聚类进行细分。
接下来对TaxoGen中的两个模块进行详细介绍。
自适应聚类模块
此模块基于球形K均值算法,该算法将一组术语嵌入分为K个聚类,每个聚类的术语具有相似的嵌入方向。之所以选择球形K均值,是因为受到词嵌入之间的余弦相似度的影响。主题的中心方向作为单位球面上的语义焦点,并且该主题的词落在中心方向周围表示相近的语义。
关键思想是迭代确定通用术语并细化子节点,这个过程包括2个操作:在聚类过程中排除通用术语可以使子节点的边界更清晰;完善子节点边界可以检测到其他通用术语。

算法1中,给定父主题C,并将C的所有术语放入子主题术语集Csub中,然后进行迭代,获取子术语集Csub中的每个术语t的代表性分数,对于代表性小于阈值δ的术语t进行剔除,推高通用术语后,重新形成了子主题术语集Csub并为下一个球形聚类做准备。当在迭代过程中找不到通用术语的时候,迭代结束,最后的一组子主题作为返回值。
对于子主题Sk的术语代表性的计算,使用Sk的文档来衡量术语的代表性,作者通过TF-IDF来获取属于每个主题Sk的文档,通过这些文档,计算Popularity和Concentration来得到子主题Sk的术语代表性。
Popularity:Sk的代表词应经常出现在Sk的文档中。
Concentration:与Sk的同级主题相比,Sk的代表性术语应与Sk更相关。
定义主题Sk的术语代表性为:
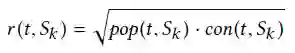
这里,pop(t,Sk)和con(t,Sk)分别为Sk的popularity和concentration分数,对于这两部分的计算如下:
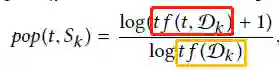
红色框中表示的是Dk中t出现的次数,黄色框是Dk的总数,Dk表示属于Sk的文档。
为了计算con(t,Sk),首先将Dk中的所有文档拼起来,为每个子主题Sk形成一个伪文档Dk,然后根据与伪文档Dk的相关性,进行如下计算:
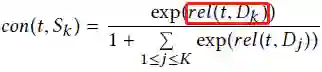
红色框表示t与伪文档Dk的BM25相关性。
举例说明:
例如figure 2中将“computer science”分为CG、ML、IR三个子话题。其中的一个子话题如ML,术语“clustering”和“classificiation”在聚类中获得了较高的代表性分数。相反,不代表任何子主题的术语“computer science”被视为通用术语,作为父节点。
局部术语嵌入模块
TaxoGen的递归分类构建过程依赖术语嵌入,该嵌入通过学习术语的固定大小矢量表示来对术语语义进行编码,作者使用SkipGram模型来学习术语嵌入 。
形式上,给定语料库D,对于任何标记t,都考虑一个以t为中心的滑动窗口,并使用Wt表示出现在上下文窗口中的标记。然后定义观察上下文的对数概率为:
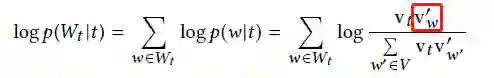
vt是术语t的嵌入,红色框是术语w的上下文嵌入,V是语料库D的词典。然后,在D中的所有标记上定义SkipGram的目标函数:
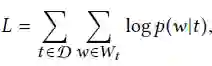
通过随机梯度下降和负采样最大化目标函数来学习术语嵌入。
然而,在训练数据时,对于较低等级的区分能力有限,比如 区分“machine learning”与“reinforcement learning”,它们有相似的上下文,在潜在空间的嵌入程度近似。因此,采用局部嵌入模块,来增强术语分类在较低等级中判别力。对于任意一个非根部话题C,将学习C的局部术语嵌入。首先,从语料库D中创建于主题C相关的子语料库Dc,在获得子语料库Dc时,有两个策略:
基于聚类。通过使用TF-IDF权重对d中的术语进行聚合,得出每个文档d ∈ D的聚类成员,聚集到主题C中的文档集合形成子语料库Dc。
基于检索。使用d中术语嵌入的TF-IDF加权平均值来计算文档d∈ D的嵌入,基于获得的文档嵌入,使用主题C的平均方向作为查询向量,以检索前M个最接近的文档并形成子语料库Dc。
举例说明:
如Figure 2中的“machine learning”。首先获得子语料库Dml,在Dml中,主题术语“machine learning”与“ml”出现在大量文档中,它们可以轻松地与更具体的术语分开,同时,不同于机器学习的子话题(如“classifcation”和“clustering”)在局部嵌入空间中也可以更容易区分。因为对局部嵌入进行训练以保留与主题相关的文档语义信息,因此,不同的术语在嵌入空间会表现出细微的语义差异。
实验设置
两个数据集:(1)DBLP包含1,889,656篇计算机科学的论文标题,分别来自信息检索、计算机视觉、机器人、安全与网络和机器学习。从这些论文标题中,使用现有的NP块来提取所有名词短语,然后删除不常见的名词短语以形成术语集,从而产生13,345个不同的术语。(2)SP包含94476篇信号处理的论文摘要。同样,提取这些摘要中的所有名词短语以形成术语集并获得6,982个不同的术语。
实验对比:HLDA、HPAM、HClus、NoAC、NoLE。其中NoAC和NoLE分别是不包括自适应聚类模块和局部嵌入模块的两个实验模型。
参数设置:在DBLP数据集上生成4层分类,在SP上生成3层分类。
TaxoGen实验中,聚类值K=5;阈值δ,在DBLP设置为0.25,SP上为0.15;
HLDA实验中,有3个超参数,分别为α = 0.1,γ = 1.0, η = 1.0;
HPAM实验中,设置上下主题的混合优先级,在两个数据集上均为1.5和1.0;
HClus、NoAC和NoLE的实验设置于TaxoGen相同。
定性结果
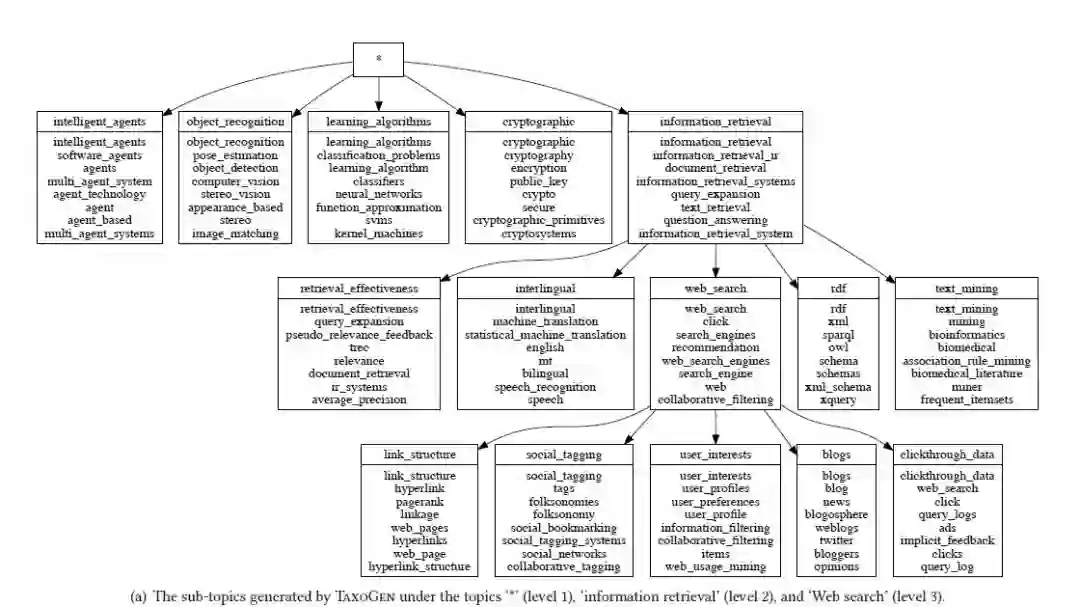
上图为TaxoGen在DBLP数据库中的结果,从图中可以看到将根话题分为5个子话题,唯一的缺陷是“对象识别”,这对于计算机视觉领域来说太具体,原因可能是“对象识别”一词在计算机视觉论文的标题中太流行了。
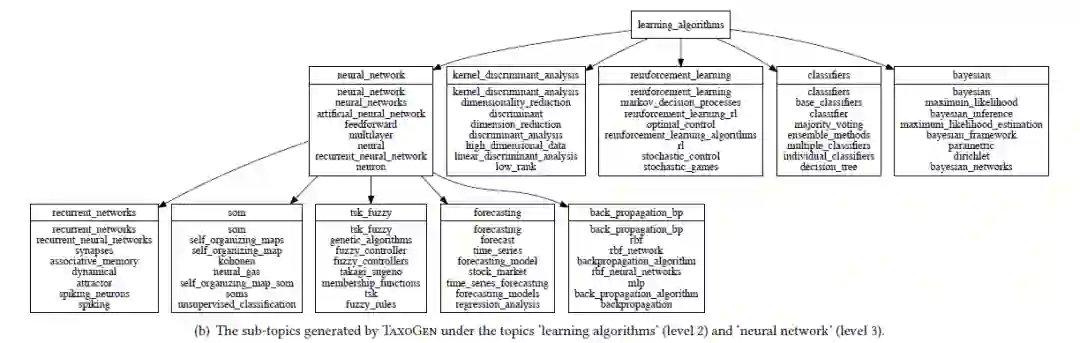
每个等级的主题划分质量良好以外,它们各自的主题在语义上也是连贯的,涵盖了同一主题的不同方面和不同表达。
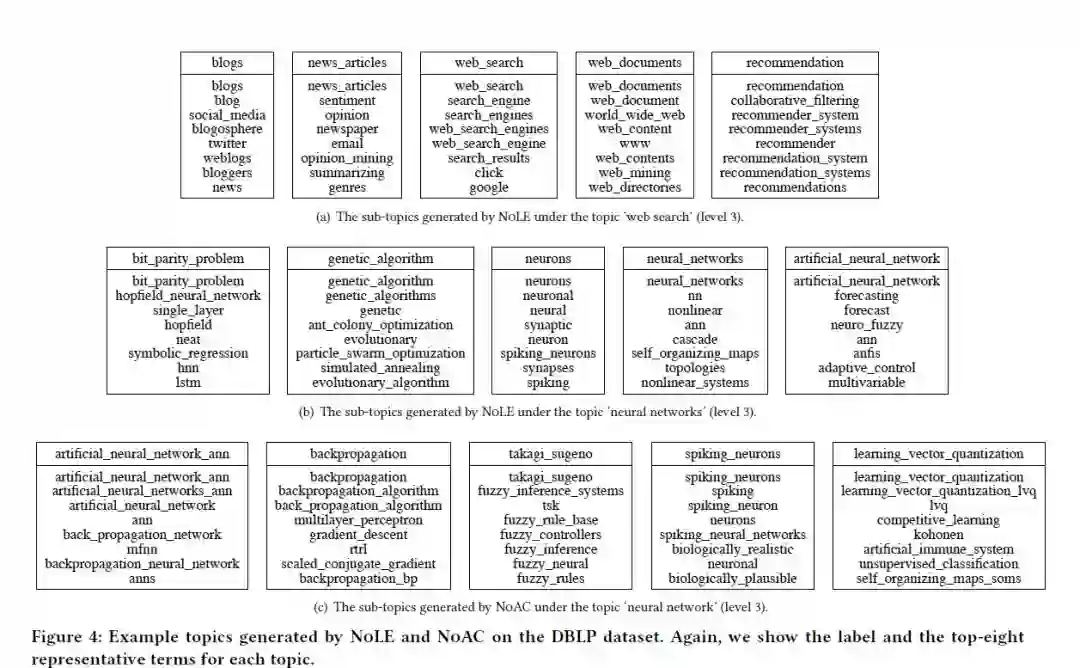
实验分别对比了NoAC 和NoLE。从Figure 4(a)中可以看出,NoLE也可以找到子话题,但是主要的缺点是大量子话题划分不正确,比如父子对‘web search’ 和 ‘web search’, ‘neural networks’和 ‘neural networks’。背后的原因可能是NoLE在所有的等级中都使用了全局术语嵌入,因此,不同语义的术语有相似的嵌入并且在较低的等级上比较难区分。同样,NoAC也出现类似的问题,但是原因不同,NoAC不会利用自适应聚类提炼属于父主题的术语。
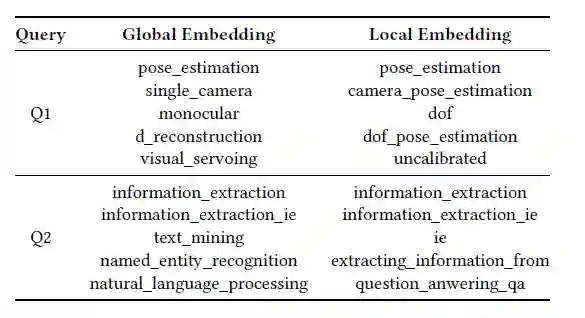
实验又对比了全局嵌入与局部嵌入的效果。对于同一个问题,分别用两种嵌入来获得前五的术语检索。对于 Q2=information_extraction,全局嵌入的效果明显没有局部嵌入的好
定性分析
从以下三方面进行定性分析:
关系准确性
术语一致性
集群质量
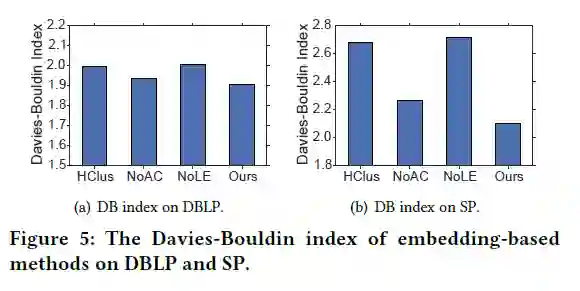
Figure 5中的DB越小,聚类效果越好。这种现象证实了自适应聚类模块和局部嵌入模块都可用于产生更清晰的聚类结构:
(1)自适应聚类过程逐渐识别并消除了位于不同聚类边界上的术语
(2)局部嵌入模块能够使子语料库完善术语嵌入,从而使子主题之间更好的分离