学界 | MIT与Facebook提出SLAC:用于动作分类和定位的稀疏标记数据集
选自arXiv
作者:赵行等
机器之心编译
参与:刘晓坤、蒋思源
近日,MIT 与 Facebook 共同提出了用于动作分类和定位的大规模视频数据集的标注方法,新的框架平均只需 8.8 秒就能标注一个剪辑,相比于传统的标注过程节省了超过 95% 的标注时间,继而证明了该数据集可以有效预训练动作识别模型,经过微调后能显著提高在较小规模数据集上的最终评估度量。
数据集链接:http://slac.csail.mit.edu/
图像分类和目标检测领域近年来取得了重大的平行进展。可以认为,这些进展归功于数据集的质量提高和数量增长,进而逐步成功地应用到了更复杂的学习模型中。在图像分类中,我们有从 Caltech101(2004,只有 9146 个样本)到 ImageNet(2011,包含 120 万个样本)这样的数据集。在目标检测中,尽管收集边界框信息所需的额外人类标注成本提高了,但也出现了训练集规模逐渐扩展的相似趋势。Pascal VOC(2007)只包含 1578 个样本,而最近提出的 COCO 数据集包含超过 20 万张图像和 50 万个目标实例标注。
在视频领域,动作分类和动作定位的数据集的规模差距有逐渐扩大的趋势。几年前提出的动作分类数据集包含几千个样本(HMDB51 有 6849 部视频,UCF101 有 13000 部视频,Hollywood2 有 3669 部视频),而最近的基准将数据集规模提高了两个量级(Sports1M 包含超过 100 万部视频,Kinetics 包含 30 万 6 千部视频)。但是动作定位的数据集并没有同等的增长速度。THUMOS 在 2014 年提出,包含 2700 部修整过的(trimmed)视频和 1000 部未修整的视频,以及定位标注。而如今最大规模的动作定位数据集相比 THUMOS 仅扩大了一点。例如,ActivityNet 包含 2 万部视频和 3 万个标注,AVA 包含 5 万 8 千个剪辑,Charade 包含 6 万 7 千个视频片段。我们在表 1 中给出了不同视频数据集的细节对比。
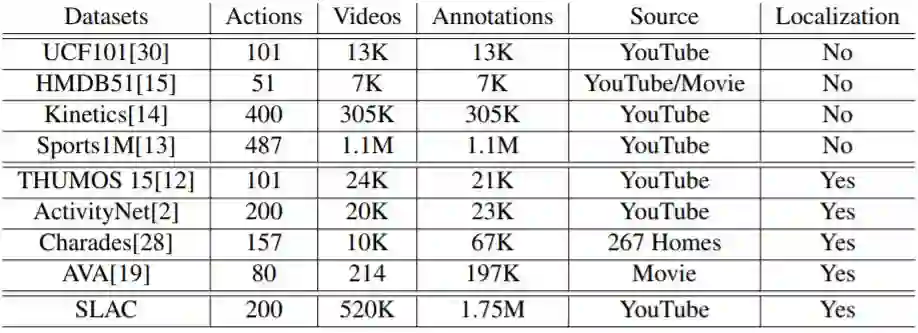
表 1:SLAC 和其它视频数据集的对比。注意,Sports1M 的标注通过分析和视频相关的文本元数据自动地生成,因此是不准确的。
为什么动作定位数据集的规模会比目标检测数据集小得多?为什么动作定位数据集的规模仍然比动作分类数据集小一个量级?在本文中,作者提出了两个猜想。首先,在视频上构建时间标注是很费时的。根据我们在专业标注员上做的实验,在视频中手工标注动作的起始和结束需要花费视频长度的 4 倍时间。为了给出准确的时间标注,标注员不仅需要观看整个视频序列,还需要来回重播视频的几个部分以寻找确定的边界。其次,动作标注的时间边界通常是模棱两可的。虽然目标边界由其物理延展所定义,但由于人类运动的平滑连续性以及动作构成定义的缺乏,动作的时间变化边界通常是模糊的。
在本文中,作者提出将时间标注任务改成更高效和更低模糊性的形式。即从每个视频中采样少量的短时剪辑提供给标注员。他们使用了一种主动学习(active learning)算法,以选择一个简单剪辑和几个硬剪辑用于标注。然后标注员需要确定这些剪辑中是否包含假定的动作。实验表明提供二值的「是/否」回答对于标注员来说更快更简单。该方法相比传统的观看整个视频并手工标注动作边界的方法节省了超过 95% 的时间。极少的人类干预允许他们构建包含高质量连续标注的大规模数据集。虽然他们的方法仅仅提高了标注剪辑的稀疏集合的质量,作者表明由这样的标注监督的模型在动作分类和动作定位任务中都获得了优越的泛化性能。
对于动作分类,可以利用该数据集的大规模特性预训练视频模型。作者表明通过在公认的动作分类基准数据集(UCF101、HMDB51 和 Kinetics)上微调这些预训练模型,得到的结果显著优于从零开始训练。在 Kinetics、UCF101 和 HMDB51 基准数据集上,他们分别将基于 ResNet 的 3D 卷积网络基线结果提高了 2.0%、20.1% 和 35.4%。作者还证明在 SLAC 上预训练相比在 Sports1M 或 Kinetics 上预训练更加有效。Sports-1M 的标注由一个标签预测算法生成,不可避免会引入显著的噪声。此外,Sports1M 的视频长度平均超过 5 分钟,而标签预测的动作可能仅在整个视频的很小一部分时间中发生。这为学习良好的视频表征以进行动作分类带来了大量的困难。和 Kinetics 相比,SLAC 包含了近 6 倍的剪辑标注(175 万 vs 30 万 5 千),这可能是在该基准数据集上训练的深度学习模型拥有优越泛化性能的原因。
最后,作者表明 SLAC 中的稀疏剪辑标注也可以用于预训练动作定位模型,并可以在每一帧给出密集型的预测。在 THUMOS 挑战赛和 ActivityNet-v1.3 数据集上,他们分别将基线模型的 mAP 值提升了 8.6% 和 2.5%。
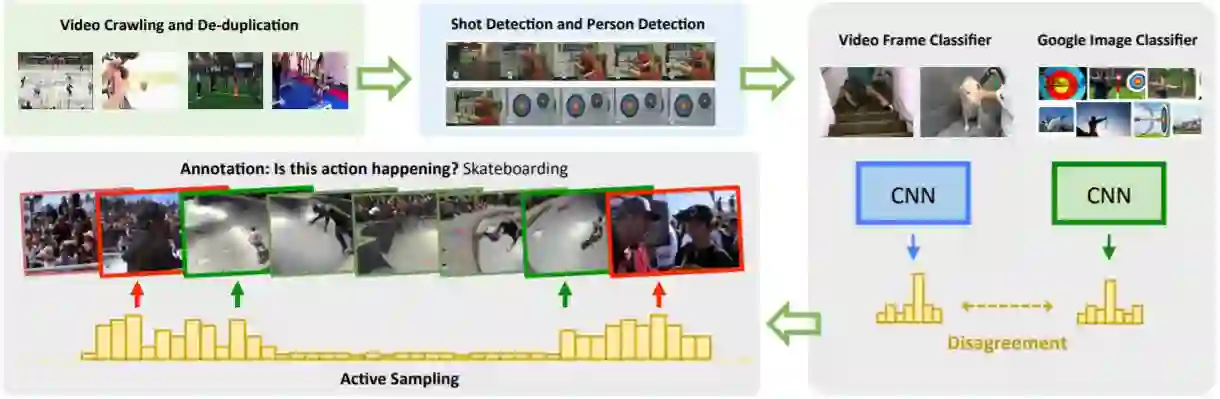
图 1:获得 SLAC 数据的收集过程。

表 7:在 SLAC 上预训练的 Res3D-34 模型与在 UCF101、HMDB51 和 Kinetics 上训练的当前最佳模型的对比。
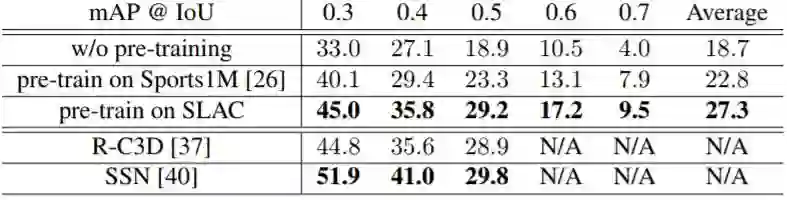
表 8:在不同数据集上预训练的模型以及当前最佳的模型,在 THUMOS14 测试集上的动作定位性能对比。
论文:SLAC: A Sparsely Labeled Dataset for Action Classification and Localization

论文链接:https://arxiv.org/abs/1712.09374
摘要:本文提出了一种从不受限的、真实的网络数据中创建用于动作分类和定位的大规模视频数据集的过程。我们创建了一个新的视频基准数据集 SLAC(Sparsely Labeled ACtions),该基准数据集由超过 52 万个未修整的视频和包含 200 种动作的 175 万个剪辑标注构成,进而证明了该过程的可扩展性。使用我们提出的框架平均只需要 8.8 秒就可以标注一个剪辑。这相比于传统的手工修整和定位动作的过程节省了超过 95% 的标注时间。我们的方法通过自动识别硬剪辑(即包含一致的动作,但不同的动作分类器会得到不同的预测结果)可以显著地减少人类标注数。人类标注者可以在几秒内辨别出这样的剪辑是否真正包含假定的动作,从而可以用很小的代价为信息丰富的样本生成标签。本文证明了我们的大规模数据集可以有效地预训练动作识别模型,经过微调后可以显著提高在较小规模基准数据集上的最终评估度量。在 Kinetics、UCF-101 和 HMDB-51 上使用 SLAC 数据集预训练的模型可以超越从零开始训练的基线模型,在使用 RGB 图像作为输入时,这三个预训练模型的 top-1 准确率分别提高了 2.0%、20.1% 和 35.4%。此外,我们还提出了一种简单的过程,它通过利用 SLAC 中的稀疏标签预训练动作定位模型。在 THUMOS14 和 ActivityNet-v1.3 基准上,我们的定位模型分别提高了 8.6% 和 2.5% 的基线模型 mAP 值。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论



