ICLR 2020会议的16篇最佳深度学习论文

作者:Kamil Kaczmarek
编译:ronghuaiyang
给大家介绍一下今年的ICLR上的最佳16篇深度学习论文。

上周,我很荣幸地参加了学习表现国际会议(ICLR),这是一个致力于深度学习各方面研究的活动。最初,会议本应在埃塞俄比亚首Addis Ababa召开,但由于新型冠状病毒大流行,会议变成了虚拟会议。把活动搬到网上对组织者来说是一个挑战,但是我认为效果非常令人满意!
1300多名演讲者和5600名与会者证明,虚拟形式更容易为公众所接受,但与此同时,会议保持了互动和参与。从许多有趣的演讲中,我决定选择16个,这些演讲既有影响力又发人深省。以下是来自ICLR的最佳深度学习论文。
1. On Robustness of Neural Ordinary Differential Equations
2. Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity
3. Target-Embedding Autoencoders for Supervised Representation Learning
4. Understanding and Robustifying Differentiable Architecture Search
5. Comparing Rewinding and Fine-tuning in Neural Network Pruning
6. Neural Arithmetic Units
7.The Break-Even Point on Optimization Trajectories of Deep Neural Networks
8. Hoppity: Learning Graph Transformations To Detect And Fix Bugs In Programs
9. Selection via Proxy: Efficient Data Selection for Deep Learning
10. And the Bit Goes Down: Revisiting the Quantization of Neural Networks
11. A Signal Propagation Perspective for Pruning Neural Networks at Initialization
12. Deep Semi-Supervised Anomaly Detection
13. Multi-Scale Representation Learning for Spatial Feature Distributions using Grid Cells
14. Federated Learning with Matched Averaging
15. Chameleon: Adaptive Code Optimization for Expedited Deep Neural Network Compilation
16. Network Deconvolution
最佳深度学习论文
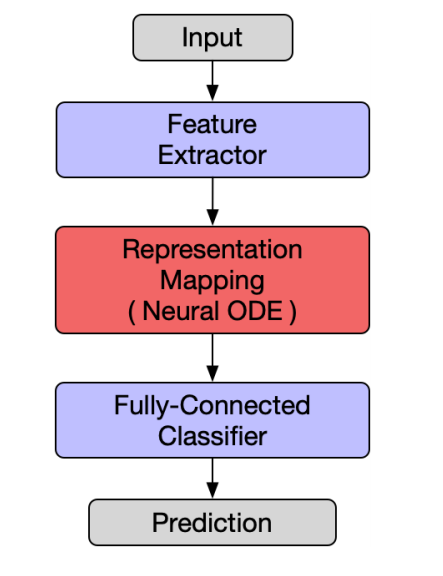
1. On Robustness of Neural Ordinary Differential Equations
深入研究了神经常微分方程或神经网络的鲁棒性。使用它作为构建更健壮的网络的基础。
论文:https://openreview.net/forum?id=B1e9Y2NYvS

2. Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity
证明梯度裁剪可加速非光滑非凸函数的梯度下降。
论文:https://openreview.net/forum?id=BJgnXpVYwS
代码:https://github.com/JingzhaoZhang/why-clipping-accelerates
第一作者:Jingzhao Zhang
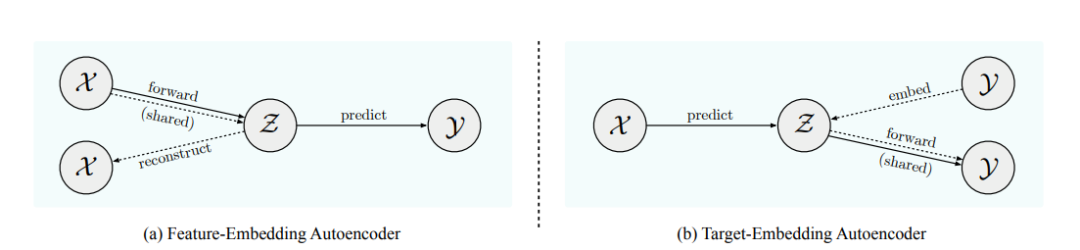
3. Target-Embedding Autoencoders for Supervised Representation Learning
新的,通用目标嵌入自动编码器或者说TEA监督预测框架。作者给出了理论和经验的考虑。
论文:https://openreview.net/forum?id=BygXFkSYDH

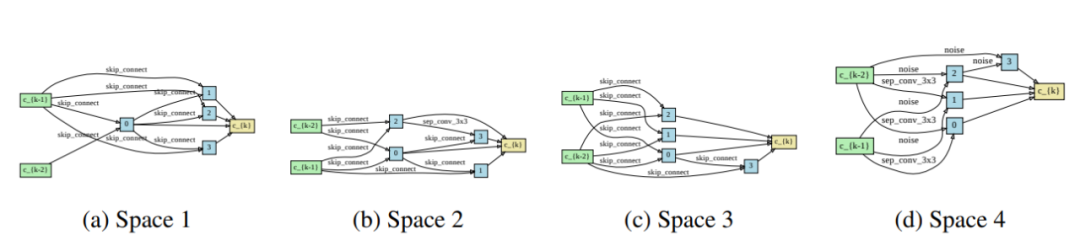
4. Understanding and Robustifying Differentiable Architecture Search
通过分析验证损失的海塞矩阵的特征值,研究了DARTS(可微结构搜索)的失效模式,并在此基础上提出了相应的对策。
论文:https://openreview.net/forum?id=H1gDNyrKDS
代码:https://github.com/automl/RobustDARTS

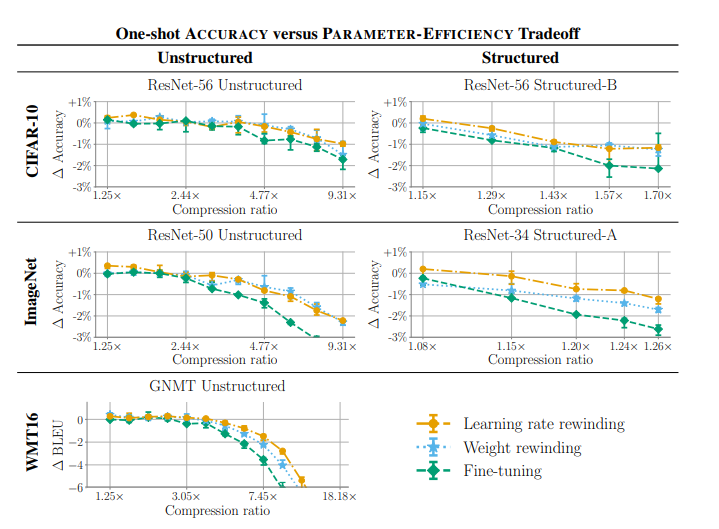
5. Comparing Rewinding and Fine-tuning in Neural Network Pruning
在修剪神经网络时,不需要在修剪后进行微调,而是将权值或学习率策略倒回到它们在训练时的值,然后再从那里进行再训练,以达到更高的准确性。
论文:https://openreview.net/forum?id=S1gSj0NKvB
代码:https://github.com/lottery-ticket/rewinding-iclr20-public

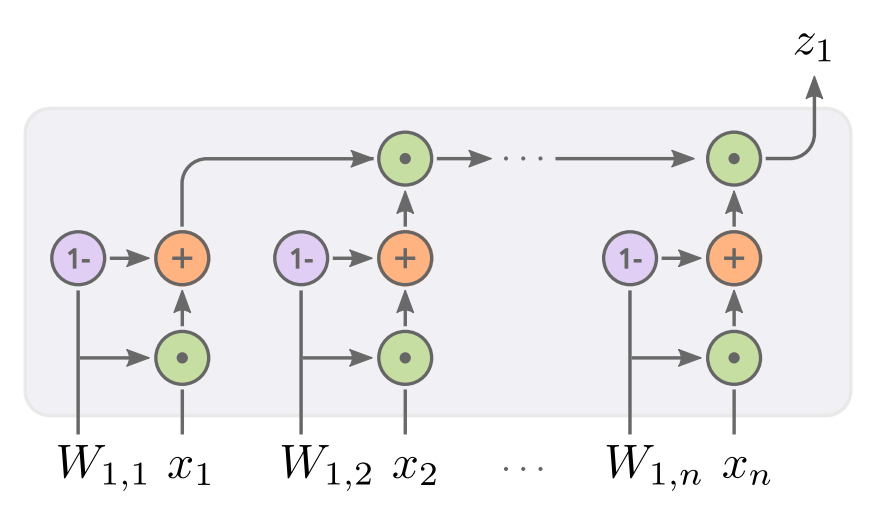
6. Neural Arithmetic Units
神经网络虽然能够逼近复杂的函数,但在精确的算术运算方面却很差。这项任务对深度学习研究者来说是一个长期的挑战。在这里,我们介绍了新的神经加法单元(NAU)和神经乘法单元(NMU),它们能够执行精确的加法/减法(NAU)和向量子集乘法(MNU)。
论文:https://openreview.net/forum?id=H1gNOeHKPS
代码:https://github.com/AndreasMadsen/stable-nalu

7. The Break-Even Point on Optimization Trajectories of Deep Neural Networks
在深度神经网络训练的早期阶段,存在一个决定整个优化轨迹性质的“均衡点”。
论文:https://openreview.net/forum?id=r1g87C4KwB
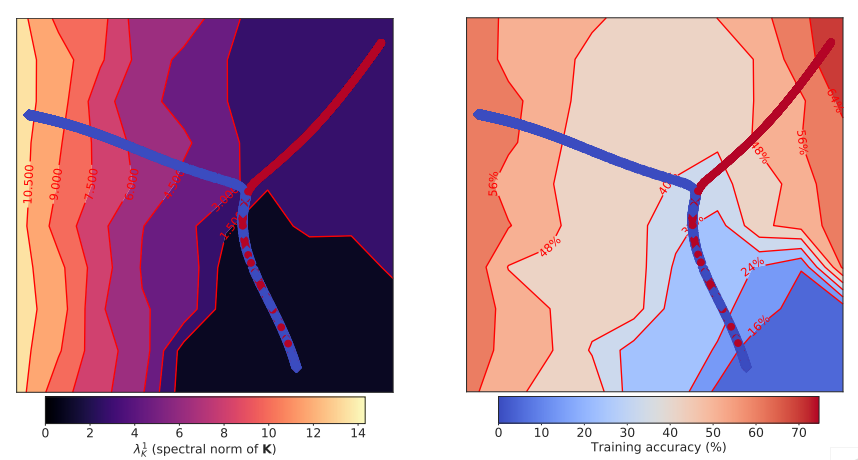
早期训练轨迹的可视化,CIFAR-10(之前训练精度达到65%)的一个简单的CNN模型优化使用SGD学习率η= 0.01(红色)和η= 0.001(蓝色)。训练轨迹上的每个模型(显示为一个点)通过使用UMAP将其测试预测嵌入到一个二维空间中来表示。背景颜色表示梯度K (λ1K, 左)的协方差归一化频谱和训练精度(右)。对于小的η,达到我们所说的收支平衡点后,对于同样的训练精度(右),轨迹是引向一个地区,这个区域具有更大λ1K(左)的特点。

8. Hoppity: Learning Graph Transformations To Detect And Fix Bugs In Programs
一种基于学习的方法,用于检测和修复Javascript中的bug。
论文:https://openreview.net/forum?id=SJeqs6EFvB


9. Selection via Proxy: Efficient Data Selection for Deep Learning
通过使用一个更小的代理模型来执行数据选择,我们可以显著提高深度学习中数据选择的计算效率。
论文:https://openreview.net/forum?id=HJg2b0VYDr
代码:https://github.com/stanford-futuredata/selection-via-proxy
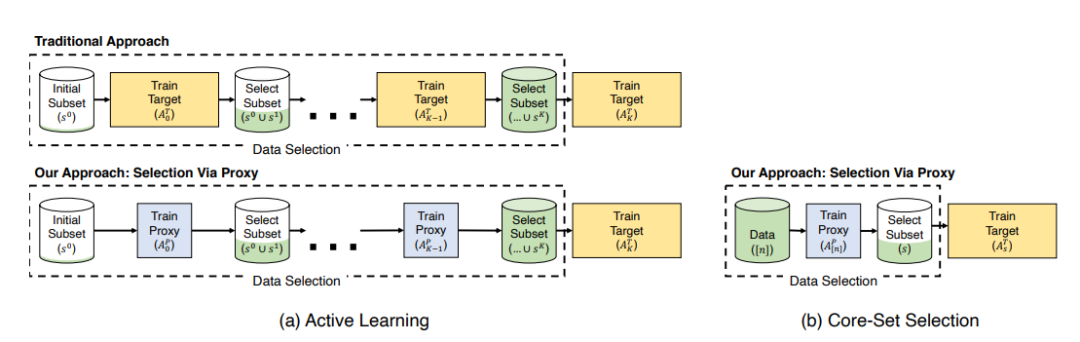
SVP应用于主动学习(左)和核心集选择(右)。在主动学习中,我们遵循了相同的迭代过程,即训练和选择标记为传统方法的点,但是用计算成本更低的代理模型代替了目标模型。对于核心集的选择,我们学习了使用代理模型对数据进行特征表示,并使用它选择点来训练更大、更精确的模型。在这两种情况下,我们发现代理和目标模型具有较高的rank-order相关性,导致相似的选择和下游结果。

10. And the Bit Goes Down: Revisiting the Quantization of Neural Networks
采用结构化量化技术对卷积神经网络进行压缩,实现更好的域内重构。
论文:https://openreview.net/forum?id=rJehVyrKwH
代码:https://drive.google.com/file/d/12QK7onizf2ArpEBK706ly8bNfiM9cPzp/view?usp=sharing
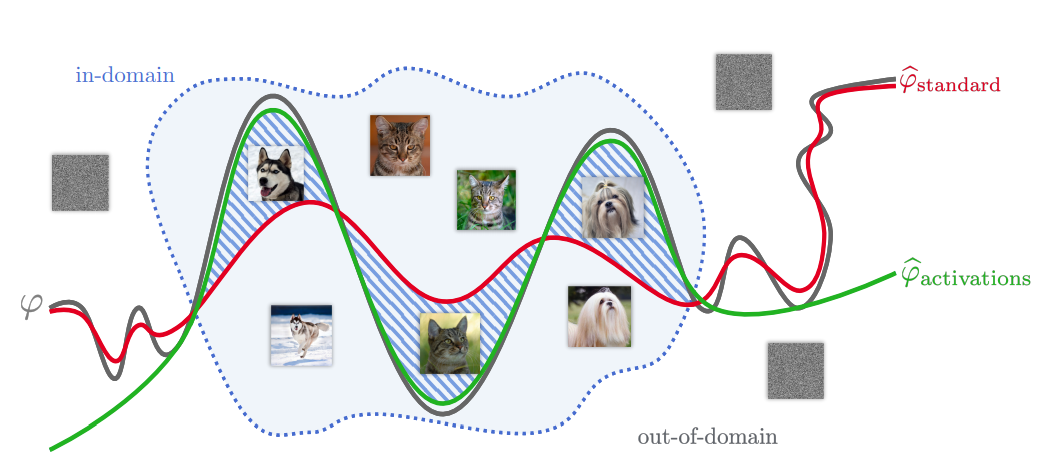

11. A Signal Propagation Perspective for Pruning Neural Networks at Initialization
我们正式描述了初始化时有效剪枝的初始化条件,并分析了得到的剪枝网络的信号传播特性,提出了一种增强剪枝网络可训练性和剪枝效果的方法。
论文:https://openreview.net/forum?id=HJeTo2VFwH
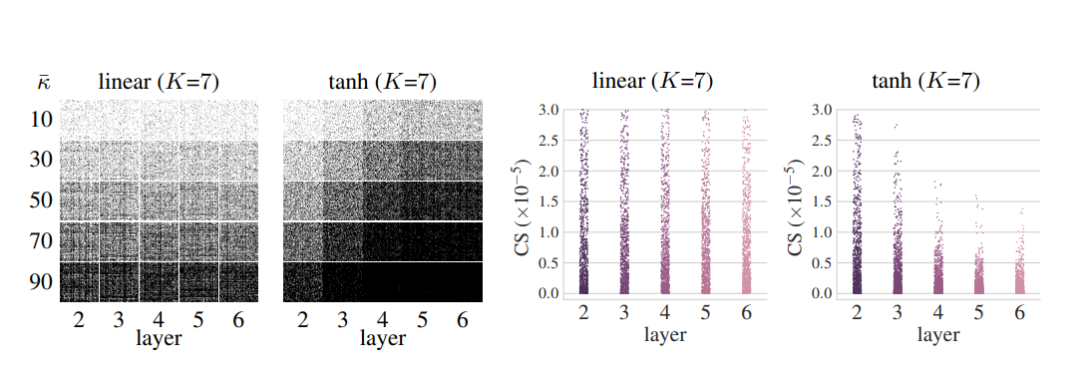

12. Deep Semi-Supervised Anomaly Detection
我们介绍了Deep SAD,一种用于一般性的半监督异常检测的深度方法,特别利用了异常的标记。
论文:https://openreview.net/forum?id=HkgH0TEYwH
代码:https://github.com/lukasruff/Deep-SAD-PyTorch
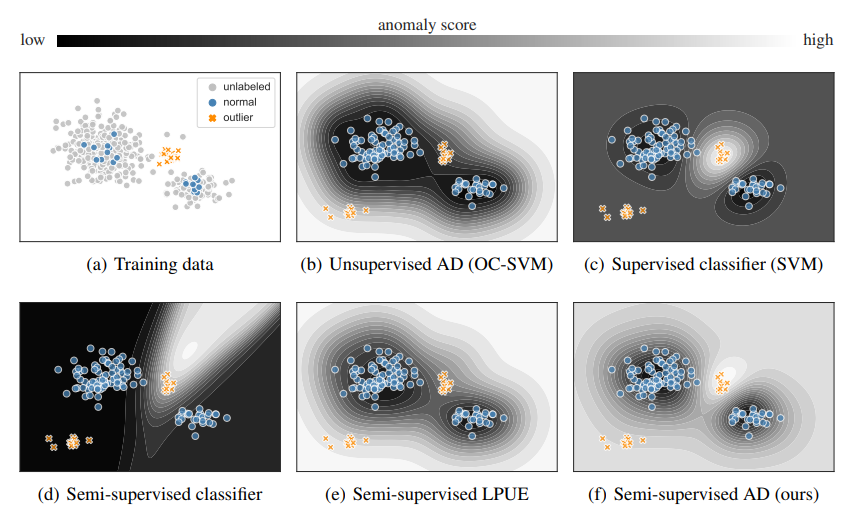

13. Multi-Scale Representation Learning for Spatial Feature Distributions using Grid Cells
我们提出了一个名为Space2vec的表示学习模型来编码位置的绝对位置和空间关系。
论文:https://openreview.net/forum?id=rJljdh4KDH
代码:https://github.com/gengchenmai/space2vec

第一作者:Gengchen Mai
14. Federated Learning with Matched Averaging
使用分层匹配来实现联邦学习的高效交流。
论文:https://openreview.net/forum?id=BkluqlSFDS
代码:https://github.com/IBM/FedMA

15. Chameleon: Adaptive Code Optimization for Expedited Deep Neural Network Compilation
深度神经网络优化编译的增强学习和自适应采样。
论文:https://openreview.net/forum?id=rygG4AVFvH


16. Network Deconvolution
为了更好地训练卷积网络,我们提出了一种类似于动物视觉系统的网络反卷积方法。
论文:https://openreview.net/forum?id=rkeu30EtvS
代码:https://github.com/yechengxi/deconvolution


总结
ICLR的深度和广度相当鼓舞人心。在这里,我只介绍了“深度学习”主题的冰山一角。然而,这一分析表明,有一些是很受欢迎的领域,特别是:
-
深度学习(本文涵盖) -
强化学习 -
生成模型 -
自然语言处理/理解
为了更全面地概述ICLR的顶级论文,我们正在撰写一系列文章,每一篇都集中在上面提到的一个主题上。

英文原文:https://neptune.ai/blog/iclr-2020-deep-learning
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




