论文公布啦!腾讯AI Lab开源最大规模多标签图像数据集,刷新行业数据集基准
【导读】2018年9月腾讯AI Lab开源“Tencent ML-Images”项目,该项目由多标签图像数据集ML-Images,以及业内目前同类深度学习模型中精度最高的深度残差网络ResNet-101构成。 近日腾讯在arxiv上发布论文详细介绍了数据集的构成以及评价标准等内容,对Tencent ML-Images数据集的理解很有帮助。
腾讯AI Lab公布的图像数据集ML-Images,包含了1800万图像和1.1万多种常见物体类别,在业内已公开的多标签图像数据集中规模最大,足以满足一般科研机构及中小企业的使用场景。此外,腾讯AI Lab还提供基于ML-Images训练得到的深度残差网络ResNet-101。该模型具有优异的视觉表示能力和泛化性能,在当前业内同类模型中精度最高,将为包括图像、视频等在内的视觉任务提供强大支撑,并助力图像分类、物体检测、物体跟踪、语义分割等技术水平的提升。
题目: Tencent ML-Images: A Large-Scale Multi-Label Image Database for Visual Representation Learning
作者:Baoyuan Wu, Weidong Chen, Yanbo Fan, Yong Zhang, Jinlong Hou, Junzhou Huang, Wei Liu, Tong Zhang

【摘要】在现有的视觉表示学习任务中,深度卷积神经网络(CNN)通常是针对带有单个标签的图像进行训练的,例如ImageNet。然而,单个标签无法描述一幅图像的所有重要内容,一些有用的视觉信息在训练过程中可能会被浪费。在这项工作中,我们建议对带有多个标签的图像进行训练,以提高训练后的CNN模型的视觉表示质量。为此,我们构建了一个大规模的多标签图像数据库,其中包含18000000个图像和11000个类别,我们称之为Tencent ML-Images。我们基于大规模分布式深度学习框架,即TFplus,在Tencent ML-Images上高效训练ResNet-101多标签输出模型,共60个epoch,耗时90小时。 通过ImageNet和Caltech-256上的单标签图像分类、PASCAL VOC 2007上的对象检测、PASCAL VOC 2012上的语义分割三个迁移学习任务,验证了Tencent ML-Images checkpoint的视觉表示质量良好。腾讯ML-Images数据库,ResNet-101的checkpoint以及所有训练代码已在https://github.com/Tencent/tencent-ml-images 上发布。它有望推动研究领域和工业界的其他视觉任务的发展。
参考链接:
http://www.zhuanzhi.ai/paper/6739b07a77caf14d1cfec55db21272a3
https://arxiv.org/abs/1901.01703
作者简介

第一作者是吴保元,现在是腾讯AI Lab的高级研究员,2014年8月至2016年11月在KAUST进行博士后学习,与Bernard Ghanem教授一起工作。2014年6月获得中国科学院自动化研究所模式识别国家重点实验室博士学位,导师为胡包钢教授。作者研究兴趣包括机器学习、计算机视觉和优化,包括图像标注、弱/无监督学习、结构化预测、概率图模型、视频处理和整数规划。
https://sites.google.com/site/baoyuanwu2015/home
其他作者包括樊艳波、张勇也都是博士毕业于中科院自动化研究所,师从胡包钢教授。
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“TML” 就可以获取最新论文下载链接~
专知《深度学习:算法到实战》今晚8点开讲,聚焦深度学习基础与前沿技术及实战,欢迎报名!
专知开课啦!《深度学习: 算法到实战》, 中科院博士为你讲授!
文章简介
这项工作在新建的多标签图像数据库(称为Tencent ML-Images)上展示了大规模的视觉表示学习。文章从讨论以下两个问题开始。
为什么我们需要大规模的图像数据库?深度学习一直处于长期低谷,直到2012年,AlexNet 在ILSVRC2012挑战的单标签图像分类任务中取得了令人惊讶的成绩。深度神经网络的潜力是通过大规模的图像数据库释放出来的,即ImageNet-ILSVRC2012 。此外,对于许多视觉任务,如目标检测和语义分割,获取训练数据的成本是非常高的。由于训练数据不足,需要在其他大型数据库上预先训练好的视觉呈现良好的checkpoint作为初始化,用于其他视觉任务(如针对单标签图像分类的ImageNet-ILSVRC2012)。
为什么我们需要多标签图像数据库?由于在大多数自然图像中存在多个对象,单个标注可能会遗漏一些有用的信息,从而误导CNN的训练。例如,同时包含牛和草的两个视觉上相似的图像可能分别被标注为牛和草。合理的方法是“告诉”CNN模型这两幅图像同时包含牛和草。
这项工作的主要贡献有四个方面:
建立了一个包含一千八百万张图像和一万一千个类别的多标签图像数据库,被称为Tencent ML-Images,这是迄今为止最大的公开可用的多标签图像数据库。
利用大规模分布式深度学习框架,在Tencent ML-Images上有效地训练ResNet-101模型。此外,还设计了一种新的损失函数来缓解大规模多标签数据库中严重的类失衡问题。
我们通过迁移学习三种不同的视觉任务,证实了Tencent ML-Images和其预训练的检查点有着比较好的质量。
在GitHub(https://github.com/Tencent/tencent-ml-images)上发布了Tencent ML-Images数据库,包含训练的ResNet-101检查点,以及从数据预处理,预训练,微调到图像分类和特征提取的完整代码。预计这将推动研究领域和工业界的其他视觉任务的发展。
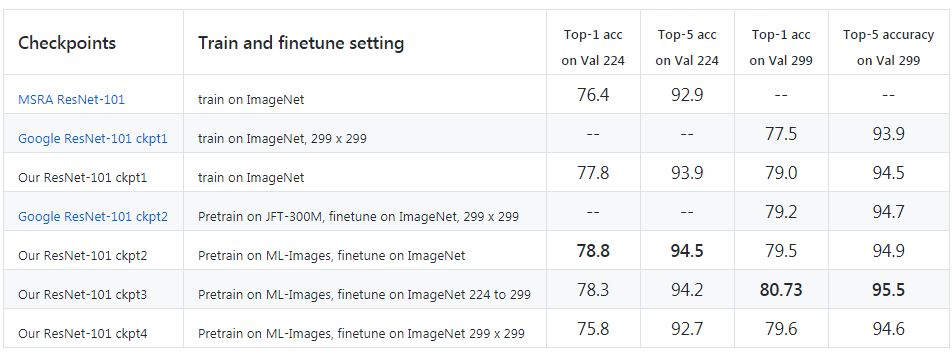
附文章中部分结果
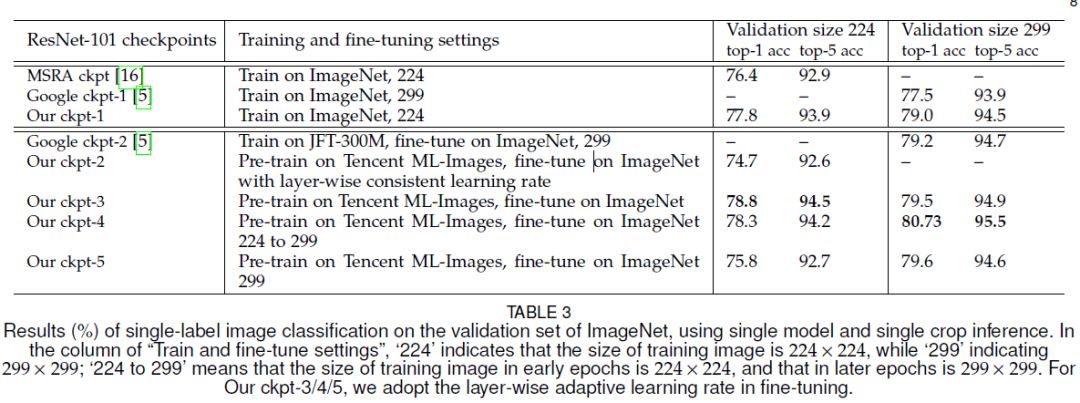
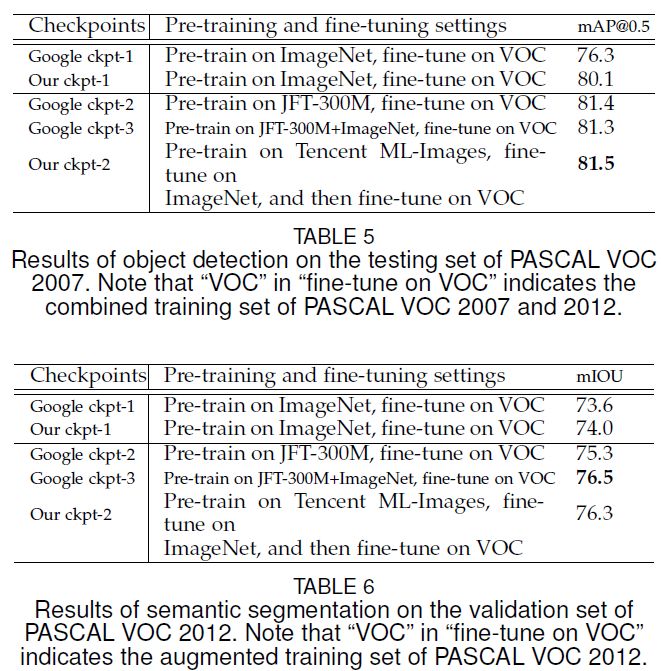
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“TML” 就可以获取最新论文下载链接~
专知《深度学习:算法到实战》今晚8点开讲,聚焦深度学习基础与前沿技术及实战,欢迎报名!
专知开课啦!《深度学习: 算法到实战》, 中科院博士为你讲授!
原文链接:
http://www.zhuanzhi.ai/paper/6739b07a77caf14d1cfec55db21272a3
https://arxiv.org/abs/1901.01703
https://github.com/Tencent/tencent-ml-images
-END-
专 · 知
专知开课啦!《深度学习: 算法到实战》, 中科院博士为你讲授!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程


