ACL 2018 | 最佳短论文SQuAD 2.0:斯坦福大学发布的机器阅读理解问答数据集
选自arXiv
机器之心编译
参与:路、王淑婷
近日,ACL 2018 公布最佳论文名单,《Know What You Don't Know: Unanswerable Questions for SQuAD》荣获这次大会的最佳短论文,Percy Liang等研究者介绍了机器阅读理解问答数据集 SQuAD 的新版本 SQuAD 2.0,其引入了与 SQuAD 1.1 中可回答问题类似的不可回答问题,难度高于 SQuAD 1.1。
代码、数据、实验地址:https://worksheets.codalab.org/worksheets/0x9a15a170809f4e2cb7940e1f256dee55/
机器阅读理解已成为自然语言理解的中心任务,这得益于大量大规模数据集的创建(Hermann 等,2015;Hewlett 等,2016;Rajpurkar 等,2016;Nguyen 等,2016;trischler 等,2017;Joshi 等,2017)。反过来,这些数据集又促进各种模型架构的改进(Seo 等,2016;Hu 等,2017;Wang 等,2017;Clark 和 Gardner,2017;Huang 等,2018)。近期研究甚至在斯坦福问答数据集(SQuAD)上产生了超越人类水平精确匹配准确率的系统,SQuAD 是应用最广泛的阅读理解基准数据集之一(Rajpurkar 等,2016)。
尽管如此,这些系统还远没有真正地理解语言。最近的分析显示,通过学习语境和类型匹配启发式方法,模型可以在 SQuAD 数据集上实现良好的性能,而在 SQuAD 上的成功并不能保证模型在分散句子(distracting sentence)上的稳健性(Jia 和 Liang,2017)。造成这些问题的一个根本原因是 SQuAD 的重点是确保在语境文档中有正确答案的问题。因此,模型只需要选择与问题最相关的文本范围,而不需要检查答案是否实际蕴涵在文本中。
在本论文研究中,研究者构建了一个新的数据集 SQuAD 2.0,它将以前版本的 SQuAD(SQuAD 1.1)上可回答的问题与 53775 个关于相同段落的、无法回答的新问题相结合。众包工作人员精心设计这些问题,以便它们与段落相关,并且段落包含一个貌似合理的答案——与问题所要求的类型相同。图 1 展示了两个这样的例子。

图 1:两个无法回答问题的示例,与貌似合理(但并不正确)的答案。蓝色字是关联性关键词。
研究者证实 SQuAD 2.0 既有挑战性又有高质量。一个当前最优的模型在 SQuAD 2.0 上训练和测试时只获得 66.3% 的 F1 得分,而人的准确率是 89.5% F1,高出整整 23.2 个百分点。同样的模型在 SQuAD 1.1 上训练时得到 85.8% F1,仅比人类低 5.4 个百分点。研究者还证明,无法回答的问题比通过远程监督(Clark 和 Gardner,2017)或基于规则的方法(Jia 和 Liang,2017)自动生成的问题更具挑战性。研究者公开发布 SQuAD 数据集新版本 SQuAD 2.0,并使之成为 SQuAD 排行榜的主要基准。他们乐观地认为,这个新数据集将鼓励开发阅读理解系统,以了解其不知道的内容。
4 SQuAD 2.0
4.1 创建数据集
研究者在 Daemo 众包平台招募众包工作者来写无法回答的问题。每个任务包括 SQuAD 1.1 中的一整篇文章。对于文章中的每个段落,众包工作者需要提出五个仅仅基于该段落不可能回答的问题,同时这些问题要引用该段落中的实体,且确保有一个貌似合理的答案。研究者还展示了 SQuAD 1.1 中每个段落的问题,这进一步鼓励众包工作者写出与可回答问题看起来类似的不可回答问题。要求众包工作者在每个段落上费时 7 分钟,他们的时薪是 10.5 美元。
若工作者在一篇文章上只写出 25 个或者更少问题,研究者将删除这些问题,以去除不理解任务、并在完成整篇文章前就已经放弃的工作者所产生的噪声。研究者将这一过滤机制应用于新数据和 SQuAD 1.1 中的已有可回答问题。为了生成训练、开发和测试集,研究者使用和 SQuAD 1.1 相同的文章分割方法,并在每次分割时都结合已有数据和新数据。对于 SQuAD 2.0 开发集和测试集,研究者删除了没有收集到无法回答问题的文章。这导致在开发集和测试集分割中产生的可回答问题和不可回答问题的比例大致为 1:1,而训练数据中可回答问题与不可回答问题的比例大致为 2:1。SQuAD 2.0 数据统计结果见表 2:
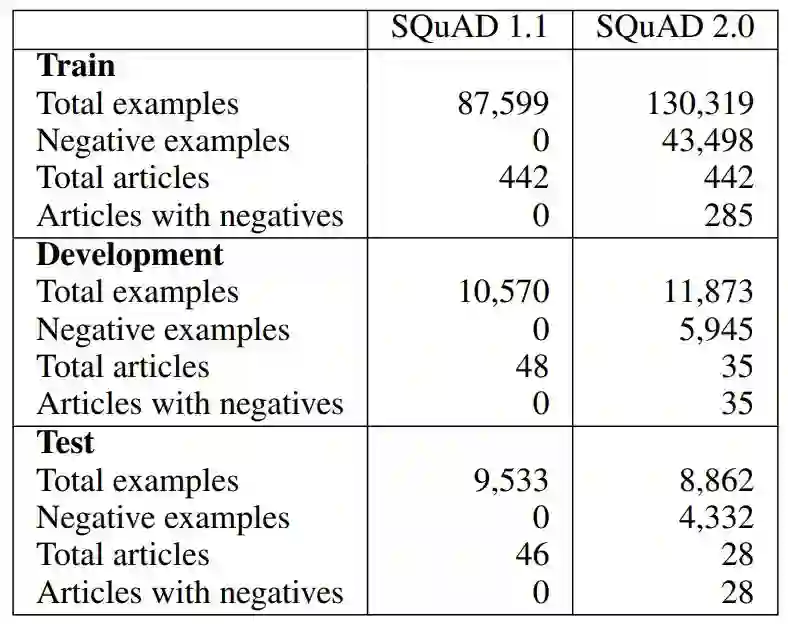
表 2:SQuAD 2.0 的数据集统计结果及其与 SQuAD 1.1 的对比。
5 实验
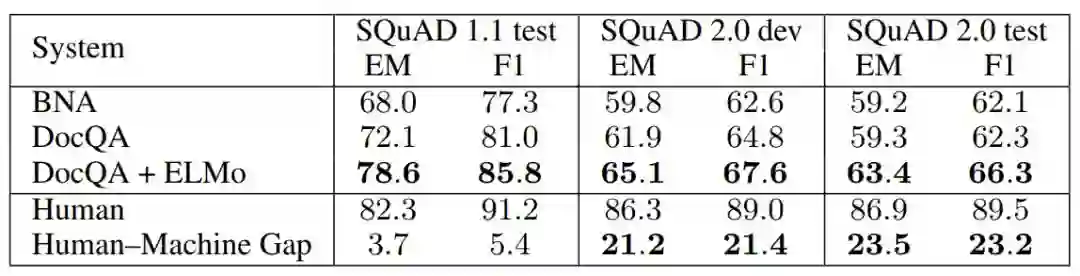
表 3:在 SQuAD 1.1 和 2.0 上的精确匹配(EM)和 F1 得分。人类与最优模型的表现在 SQuAD 2.0 上差距更大,这表明该模型有很大改进空间。

表 4:在 SQuAD 2.0 开发集上的精确匹配(EM)和 F1 得分,及其与在具备两种自动生成负样本的 SQuAD 1.1 上的 EM 和 F1 得分对比。对于当前模型来说,SQuAD 2.0 更具挑战性。
论文:Know What You Don't Know: Unanswerable Questions for SQuAD

论文链接:https://arxiv.org/pdf/1806.03822.pdf
摘要:提取式阅读理解系统(Extractive reading comprehension system)通常在语境文档中定位问题的正确答案,但是它们可能会对正确答案不在语境文档内的问题进行不可靠的猜测。现有数据集要么只关注可回答的问题,要么使用自动生成的无法回答的问题,这些问题很容易识别。为了解决这些问题,我们创建了 SQuAD 2.0——斯坦福问答数据集(SQuAD)的最新版本。SQuAD 2.0 将已有的 SQuAD 数据和超过 5 万个对抗性的无法回答的问题结合起来,后者是通过众包工作者根据与可回答问题类似的方式写成的。为了在 SQuAD 2.0 上实现良好的性能,系统不仅必须回答问题,还要确定何时语境段落中没有答案、可以放弃回答问题。SQuAD 2.0 对现有模型来说是一个很有难度的自然语言处理任务:一个在 SQuAD 1.1 上得到 86% 的 F1 得分的强大神经系统在 SQuAD 2.0 上仅得到 66% 的 F1 得分。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





