对话推荐系统的逻辑与演化总结
© 作者|尚琛展
机构|中国人民大学硕士一年级
导师|张静、赵鑫
研究方向 | 推荐系统与自然语言处理
本文将围绕近四年来发表在顶级会议(NeurIPS、SIGIR、KDD、EMNLP、WSDM、COLING)上的 9 篇代表性工作介绍对话推荐系统领域的问题定义、处理方案和结构演化。另外笔者整理了近年来该领域 68 篇研究工作及其代码和数据集附在文末,分享给读者学习参考。
开始之前先介绍一下!RUC AI Box 开发和维护了一个用于构建对话推荐系统的开源工具 CRSLab(发表在 ACL Demo 2021),欢迎点赞收藏~
https://github.com/RUCAIBox/CRSLab
本文目录如下:
-
引言 -
对话推荐概述 -
整体架构 -
发展现状 -
基于属性的对话推荐 -
问题定义 -
单轮场景 - CRM -
多轮场景 - EAR -
搜索剪枝 - CPR -
统一架构 - UNICORN -
生成式对话推荐 -
问题定义 -
降噪协同 - ReDial -
知识增强 - KBRD -
语义融合 - KGSF -
话题引导 - TGReDial -
可控生成 - NTRD -
总结 -
未来展望 -
论文总结
1.1 对话推荐概述
近年来,推荐系统在工业界获得了巨大的成功,成为互联网当之无愧的增长引擎。与此同时,研究者们也在进一步探索新形态的推荐系统,对话推荐系统(Conversational Recommender System,简称 CRS)就是其中一个有趣的探索方向。对话推荐系统旨在通过基于自然语言的多轮对话,逐步挖掘用户的兴趣偏好,从而向用户推荐其可能感兴趣的物品。
传统推荐系统通常使用用户的“隐式反馈”(implicit feedback)来习得其兴趣偏好,比如用户的点击记录、查询记录等,而对话推荐系统则“激进”地直接与用户进行对话,通过询问各式各样的问题来认识和了解用户。因此在对话推荐场景下,算法系统有可能成为主动的一方,与用户进行动态交流来获得其“显式反馈”。
新形态意味着新挑战。如何对对话推荐任务进行形式化的设定,如何解决该设定下引入的具体问题,如何让解决方案更符合实际需求,这都是摆在研究者面前的实际挑战。幸运的是,在深度学习技术应用于推荐系统和自然语言处理领域的大背景下,研究者们也关注到了对话推荐问题,并从不同角度给出了各自的解答,而这些工作也已初步构成了解决该问题的基本脉络。
在本文中,笔者将围绕深度学习视角下对话推荐系统领域的发展,介绍 9 篇来自领域顶级会议的代表性工作,梳理这些工作背后的基本逻辑及其演化,并试图总结未来可能的发展方向。
1.2 整体架构
我们也许可以先抛开已有工作给我们的既定印象,试图从任务本身开始构想如何搭建一个对话推荐系统。对话推荐系统,顾名思义我们既需要解决对话问题,又需要解决推荐问题,所以我们可以认为对话推荐系统的整体架构包含“推荐模块”和“对话模块”。但如果真这么讲,就跟介绍如何把大象装进冰箱一样过于简洁了。
不妨从日常生活的情节进行考虑。当我们想找朋友一起看电影,可能先会询问对方心情如何或者有没有看电影的意愿;在获得了肯定的答复后,我们可能会试探性地提供一个正在热映的电影;如果对方恰好不喜欢这类影片,我们可能会根据标签排除这类候选项;接着继续进行询问和推荐,直到我们达成共识。
在这个简单的生活推荐场景中,我们能够窥探到现代对话推荐系统的一些实现细节。比如我们推荐的结果往往无法一步到位,所以会多次推荐直到成功,形式化地来说这是一种“多轮”(multi-round)推荐场景;又比如我们需要根据对方的反馈来决定下一步的行动,这种决策过程需要由一个策略(policy)管理器来进行调控;再比如,如果时间紧张,我们会纠结是继续问下去,还是使劲问对方喜不喜欢,学术上有经典的多臂老虎机模型(multi-armed bandit)来刻画这种探索与利用权衡的问题(exploration and exploitation trade-offs)。
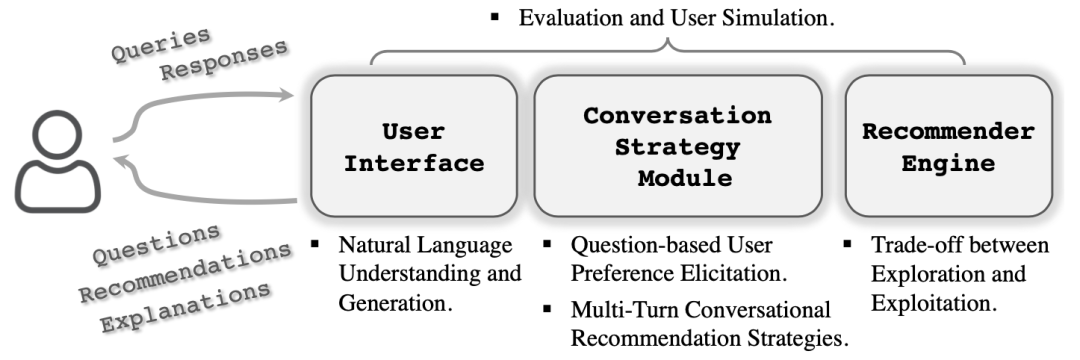
总之继续沿着这个思路探索下去,我们大致能够得到与上图相符合的问题解决框架 [1]。这个框架从功能出发对问题场景进行建模,得到三个主要的功能模块,分别是:
-
User Interface:用户交互模块,它需要理解用户给予的自然语言反馈,也需要在最后给出系统的文本答复。 -
Conversation Strategy Module:对话策略管理模块,它需要根据当前状态做出如何回复的决定,比如是继续询问还是进行推荐。 -
Recommender Engine:推荐引擎,负责根据用户的偏好给出相应的推荐列表或者单个推荐结果。
为叙述方便,我们不失原义地将上述三个模块的名称替换为“对话模块”(Conversation Module)、“策略模块”(Policy Module)和“推荐模块”(Recommender Module)。同时我们将在下文中看到,现有的对话推荐系统工作基本上都符合该总体框架,只是在具体方面会有所侧重。
1.3 发展现状
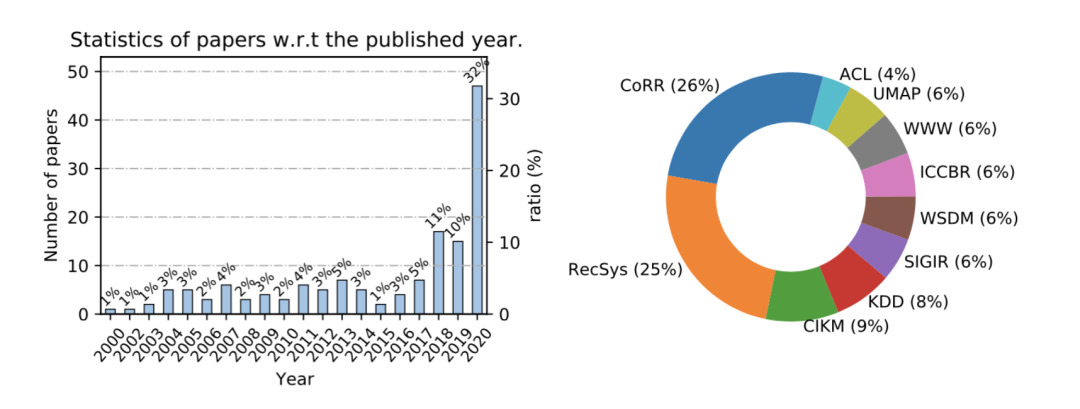
综述文章 [1] 以Conversation* Recommend*为关键词在 DBLP 上搜索了相关工作并作统计,得到了相关论文按年份和按会议的分布数据。从图中可以发现在 2018 年来该领域出现了更多的相关工作,而正是在 2018 年发表的两篇代表性工作,成为对话推荐系统两个类别最常见的基准模型(baseline)。
目前的工作主要集中地从两个不同的角度来看待对话推荐问题,第一种称为“基于属性的对话推荐”(attribute-based CRS),第二种模型的话,有的文献称之为 chit-chat-based CRS,也有的称之为 open-ended CRS,笔者更习惯称之为“生成式对话推荐”。
从上文中所提及三个模块的角度来看两类模型的区别,可以概括如下:
-
基于属性的对话推荐系统更多地针对 策略模块进行构建,希望能在最短的交谈次数内实现尽可能精确的推荐。这类模型通常采用强化学习(reinforcement learning)方法来训练对话管理器,以期在更长的时间跨度内获得更高期望的回报。相应地,它们通常有一个简化的对话模块,比如使用带槽(slot)的固定模板来填充推荐结果,形成系统的回复文本。 -
生成式对话推荐系统更注重向用户提供 流畅的对话体验,同时灵活地将推荐物品相关的信息融入到回复文本中,以提升推荐结果的可解释性。这类模型通常采用序列到序列(sequence-to-sequence)模型来构建对话模块,而策略模块则可能隐式地包含在拷贝机制(CopyNet)或者其他结构中。同时,近年来兴起的大规模预训练语言模型也进一步增强了生成式对话推荐系统的对话能力。
笔者将在下文中分别叙述这两类模型的问题定义和解决方案(逻辑)、结构演化,希望通过下面的阅读,读者能够对对话推荐系统当前的发展有大致的了解。
下面第 2 节将介绍基于属性的对话推荐,先说明问题定义,从最早的单轮推荐场景 CRM(SIGIR 2018)出发,介绍引入多轮推荐场景的模型 EAR(WSDM 2020),再到将对话推荐概括为图上推理问题的模型 CPR(KDD 2020),其实际上也是对搜索问题的剪枝操作,最后是希望学习统一策略的模型 UNICORN(SIGIR 2021)。
接着第 3 节将介绍生成式对话推荐,先说明问题定义,从提出了应用最广泛的数据集的工作 ReDial(NeurIPS 2018)开始,介绍知识增强的模型 KBRD(EMNLP 2019)、语义融合的模型 KGSF(KDD 2020)和话题引导的模型 TGReDial(COLING 2020),最后介绍希望实现更可控推荐对话文本生成的模型 NTRD(EMNLP 2021)。
值得一提的是,这九篇工作都有开源的、基于 PyTorch 实现的官方源码,读者可以通过文末提供的论文列表找到它们以及更多相关工作的源码主页链接。
RUC AI Box 组织开发的用于构建生成式对话推荐系统的开源工具包 CRSLab [11],便于研究者更快捷地复现已有的生成式对话推荐模型,并在此基础上实现自己的模型。该工作已经被 ACL Demo 2021 接收。工具主页链接如下,欢迎 Star~
https://github.com/RUCAIBox/CRSLab
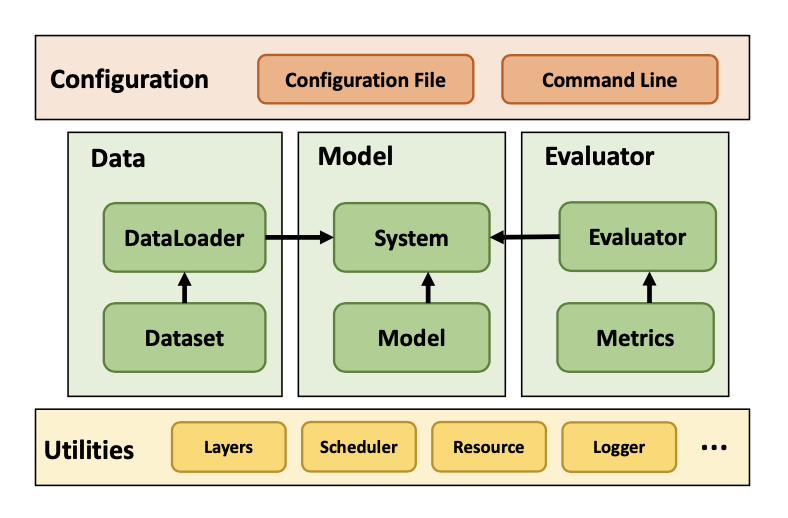
CRSLab 整体架构如上图所示,其采用数据与模型相分离的模式,使得预处理好的 6 个数据集和 5 个模型能够自由搭配,除了部分数据与模型不完全兼容的情况。CRSLab 还实现了常用的基准模型(Baseline)和便捷的自动化评测模块,使开发者能将更多的精力集中在模型的主要逻辑中。
2 基于属性的对话推荐
2.1 问题定义
如果在对话的过程中系统能够进行多次推荐,直到用户采纳推荐结果或者离开,我们称这种场景为多轮的(multi-round)。相对地,如果系统仅进行一次推荐,而不关注用户是否接受该结果,则称为单轮的(single-round)。
下面介绍问题的形式化定义。令 表示用户集合 中的一位用户 , 表示物品集合 中的一件物品 , 表示属性集合 中的一个属性 。每个物品 有对应的属性集合 。属性是描述物品的标签,比如电影《星际穿越》的标签可以是“科幻电影”。
对话会从用户端开始,用户先指定一个自己喜欢的标签 ,系统会从物品候选集合中根据该标签进行筛选。接着系统在每一步 采取一个动作,要么是推荐物品(动作记为 ),要么是询问属性(动作记为 )。用户也会对系统的动作做出相应的反馈,对系统的推荐结果可以接受(accept)或者拒绝(reject),对询问的属性标签也可以是接受(表示喜欢)或者拒绝(表示不喜欢)。
整个系统的目标就是在最短的对话次数内完成尽可能精确的推荐。通常人们采用如下两个评测指标来评估基于属性的对话推荐系统的性能:
-
Success Rate @ t(SR@t):对话进行 t 轮时的平均成功率。 -
Average Turn:完成推荐的平均次数。
值得一提的是,因为难以让足够多真实的用户来训练系统,这类工作通常还会设计一个用户模拟器(user simulator)来与算法系统完成强化学习的训练过程。一个典型用户模拟器的实现是,寻找一个物品 来锚定(anchor)用户,这个物品就是该用户的 ground-truth item,同时满足如下假设:
-
对于系统给出的推荐物品列表,只有当 出现在这个列表中,用户才会接受推荐结果。 -
对于系统询问的属性 ,只有该属性与 相联系,用户才会认为自己喜欢该属性标签。
本节介绍的四个模型都采用推荐领域常见的数据集 Yelp 来构建对话推荐任务所用的数据,其中 CRM 通过 Amazon Mechanical Turks 平台基于 Yelp 构建了简单的对话文本,其他三个模型还采用 LastFM 作为训练与测试数据集。
2.2 单轮场景 - CRM
本节介绍 SIGIR 2018 工作:Conversational Recommender System [2]。
这篇文章使用强化学习技术来构建单轮场景下的对话推荐系统,提出的模型简称 CRM。作者认为在搭建 CRS 时需要考虑三个重要问题:
-
如何准确地理解用户的意图? -
如何实施序列化的决策并在每一步才去合适的行动? -
如何做个性化的推荐以最大化地提升用户的满意程度?
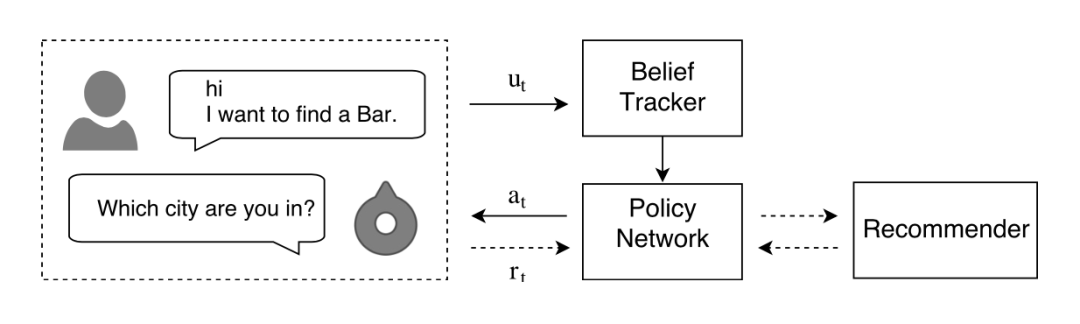
本文提出了三个模块分别来应对这三个问题,如上图所示。首先是 Belief Tracker 模块来跟踪用户意图,它能够将用户的表达(utterance)转化为向量表示或者说 belief;其次,该 belief 会被送入 Policy Network 作为依据来决定这一步的动作;此外,belief 还会被送入 Recommender 来完成个性化推荐任务。
下面详细叙述这三个模块的基本思路。首先用户发起对话,比如“I’m looking for Mexican food in Glendale”,CRM 的 Belief Tracker 模块会利用 n-gram 词表将其转化为向量表示 ,下标 表示当前对话轮次。接着,会有一个 LSTM 网络将对话上文的向量编码成一个隐含表示:
对话进行到不同阶段 的不同隐含表示,各自经过 再连接之后就能够得到截止目前为止的用户 belief 。
接着是推荐模块,CRM 采用了经典的二路因子分解机(2-way FM),其输入为标识用户的 one-hot 向量 、标识物品的 one-hot 向量 、用户置信 连接而成的向量 ;输出就是用户 m 对于物品 n 的预测评分。
最后是策略模块,CRM 以用户置信 作为输入,经过简单的两层前馈神经网络直接得到了用户的动作预测。三个模块构成的对话推荐系统架构如下图所示。
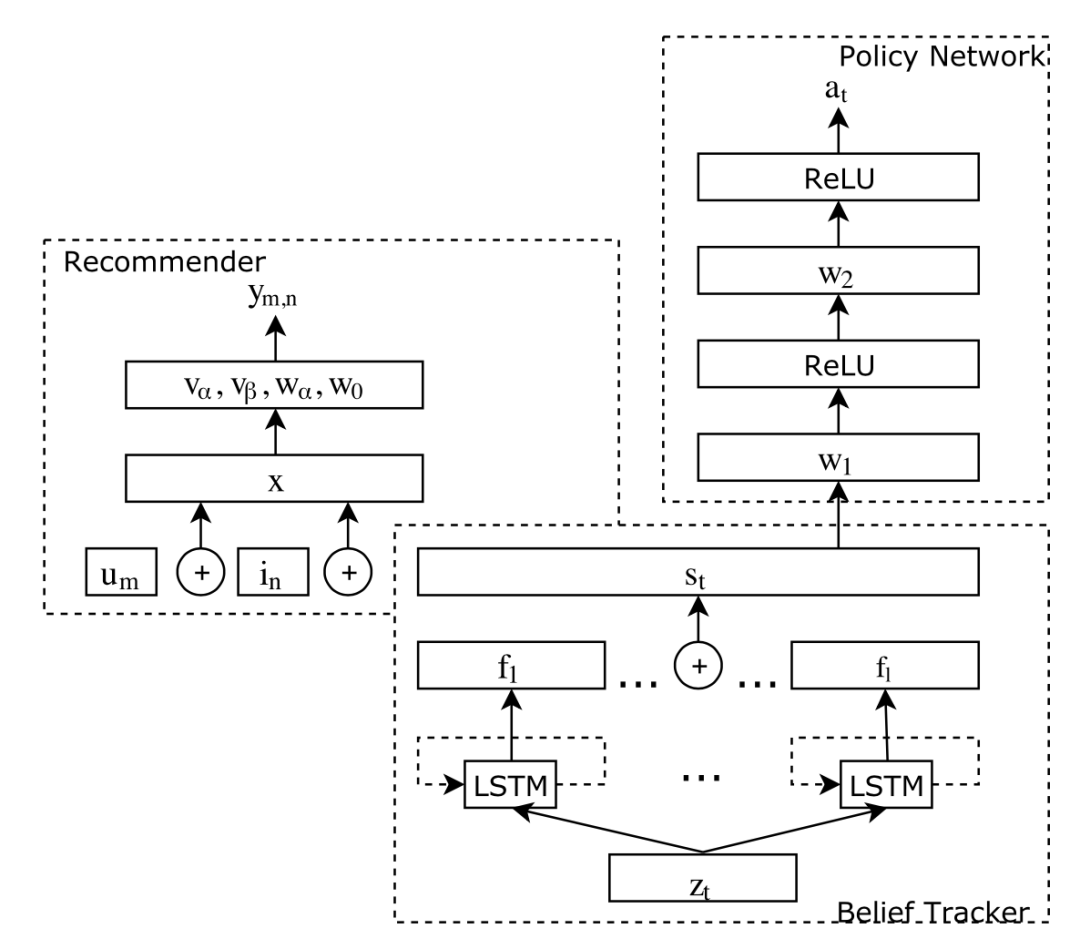
策略模块利用强化学习中的 Policy Gradient 方法进行训练,其动作空间由两部分构成,一个是推荐动作 ,一类是询问动作,包括不同类型属性的询问。设属性的种类有 种,那么动作空间的大小就是 。另外,CRM 设计了一套复杂的奖励(Award)机制,根据推荐结果的质量来返回奖励分数,这里不再详述。
2.3 多轮场景 - EAR
本节介绍 WSDM 2020 工作:Estimation–Action–Reflection: Towards Deep Interaction Between Conversational and Recommender Systems [3]。
上一小节介绍的 CRM 是对构建对话推荐系统的早期尝试,仍有许多问题待以解决。本文认为现实中的对话推荐更应该采用多轮场景,也就是系统能对一个用户进行多次推荐,并根据之前推荐的反馈改善后面的推荐,从而达成在最短对话次数内完成更精确推荐的目标。
本文认为多轮推荐场景的实施,需要对话推荐系统的两大模块(对话模块 Conversational Component,CC;推荐模块 Recommender Component)的深入交互,而这种交互主要有下面三个基本问题:
-
What attributes to ask:向用户询问关于哪个属性标签的问题。
比如系统向用户询问其是否喜欢古典音乐,考虑用户的二元回答(是或否)。如果用户回答“是”,那之后就可以更加关注古典音乐类别的物品;如果用户回答“否”,相当于浪费了这次询问的机会。为了能够在最短对话次数内完成推荐,系统需要好好考虑询问哪方面属性的问题。
-
When to recommend items:何时向用户提供推荐结果的问题。
可能有若干种情况适合进行推荐:候选物品空间比较小;继续询问没有太多意义;系统对推荐结果很有把握。
-
How to adapt to users’ online feedback:如何应对用户的反馈。
对询问属性的正面反馈,可以利用该属性来过滤候选物品集合;对于询问属性的负面反馈,系统需要调整自己的策略;对于推荐结果的负面反馈,系统需要标注这些物品是不合适的。
针对这三个问题,本文提出了框架 Estimation–Action–Reflection 来解决,模型简称为 EAR。
Estimation 模块完成推荐任务,构建了以 FM 和 BPR 为核心组建的推荐系统。系统在与用户对话的过程中会逐步构建其喜欢的属性集合 ,就是用户予以肯定回复的那些被询问的属性构成的集合。对于用户 和物品 有 embedding 表示 和 ,因子分解机进行如下预测:
用户的正例为该对话的 ground-truth item,同时采样负例 ,构建训练样本集合 。FM 训练的目标函数就是如下 Bayesian Personalized Ranking(BPR)损失函数:
本文还提出上面进行负采样并未考虑到系统正在维护的用户属性集合 ,根据该属性集合能够得到一个过滤后的候选物品集合,如果在该集合中进行负采样就能得到感知属性的 BPR 损失函数。
Action 模块是基于强化学习训练的决策模块,网络结构和 CRM 相同,都是两层前馈神经网络,动作空间的设计也和 CRM 一致。但是 EAR 综合考量了候选物品集合的信息熵、用户对属性的偏好、历史对话状态、当前候选物品集合长度四个量,来构建 Policy Network 的输入向量;同时也设计了更简单的奖励机制:
-
:当推荐成功时给予的正得分 -
:当用户给询问的属性给予正面反馈时的正得分 -
:当用户退出系统时的负得分 -
:对话每增加一轮所给予的负得分,以避免对话过长
Reflection 模块主要用于对用户给予负反馈的物品进行强化的训练,本文的实现方法是以这些负反馈物品为负例构建新的损失函数项进一步训练。
2.4 搜索剪枝 - CPR
本节介绍 KDD 2020 的工作:Interactive Path Reasoning on Graph for Conversational Recommendation [4]。
本文提出了一种框架 Conversational Path Reasoning(CPR),将对话推荐场景建模为图上的交互式路径推理问题。作者认为,之前的工作都是用隐式的方法来利用用户在属性方面的反馈信息,比如用来更新用户向量表示。本文基于图机构,通过显式方法来利用用户喜欢的属性,删去了大量无关的候选物品,提升了推荐结果的命中率。这里的“图”指的是由用户、物品、属性三类节点构成的图结构,如下图右侧所示。
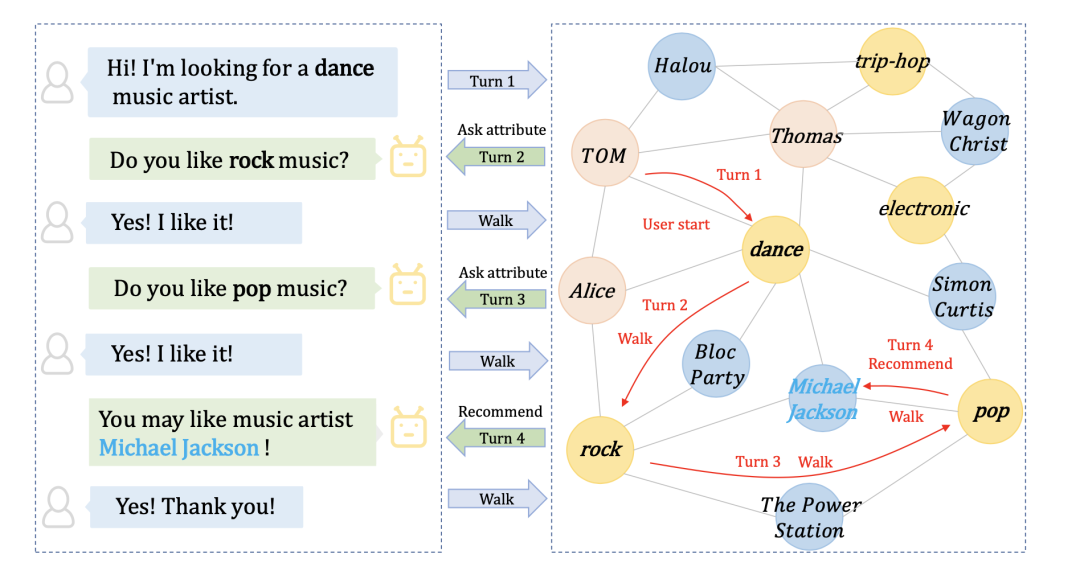
相对于以往的工作 CRM 和 EAR,CPR 的第一个大变动就是将决策的动作空间缩小为两个,也就是选择询问( )或者推荐( ),减小了强化学习训练的难度。不过这样一来,我们还需要额外确定具体询问什么属性。那么接下来,我们只需要知道系统在什么样的物品候选范围( )内依据什么规则来选择推荐的结果,以及在什么样的属性候选范围( )内依据什么规则来选择当前需要询问什么属性,就能理解 CPR 做了什么事情。
首先是候选范围的问题,由图上的路径推理来解决。这里的“路径推理”,被作者定义为在图结构中属性(Attribute)类型节点上的游走,也就是每个时刻 会认为系统当前位于某一个属性节点上,下一步可能会移动到其相邻的属性节点上。值得注意的是,由于不会有两个属性节点直接连接,这里的“相邻”不是图意义上的直接相邻,而是跨越其他节点的间接相邻。该时刻的这些相邻属性(Adjacent Attributes)构成集合 。
在推理的过程中,系统会持久化地维护下面三个集合( 是每次重新计算的):
-
:之前访问过的属性节点集合。 -
:询问用户时被予以否定的属性集合。 -
:候选物品集合。
系统初始化时前两个集合为空,最后一个集合是所有物品。对话开始时用户提供一个初始化属性 ,该属性会被加入 中。接着就会进行决策,有两种情况:
-
询问属性( ): -
用户给予肯定回复:该属性被加入到 中,系统在图上的状态更新为在这个新的属性节点上,并将候选属性集合更新为 ,也就是当前这个属性节点的邻居属性节点中,没被访问过且没被拒绝过的那些节点的集合,同时候选物品集合也更新为 ,也就是说现有的候选物品要符合 中的所有属性。 -
用户给予否定回复:该属性被加入到 ,不更新图上状态。 -
推荐 top- 物品( ): -
用户给予肯定回复:推荐成功,结束对话。 -
用户给予否定回复:从候选物品集中删去这些物品 。
通过图上的路径推理,显式地利用用户的反馈信息确定了物品和属性的候选范围,这种剪枝操作很大程度上缩减了搜索空间,从而提升了推荐性能。
接着是在候选集合中进一步排序的规则。论文给出的 CPR 框架的一个实例化模型 SCPR 中,对物品排序规则采用与 EAR 相同的因子分解机加 BPR 目标函数,对属性排序规则采用了最大熵算法。此外,决策模块的强化学习奖励机制设计也与 EAR 相似,不过训练时采用了 Q-Learning 算法,这里不再详述。
2.5 统一架构 - UNICORN
本节介绍 SIGIR 2021 工作:Unified Conversational Recommendation Policy Learning via Graph-based Reinforcement Learning [5]。
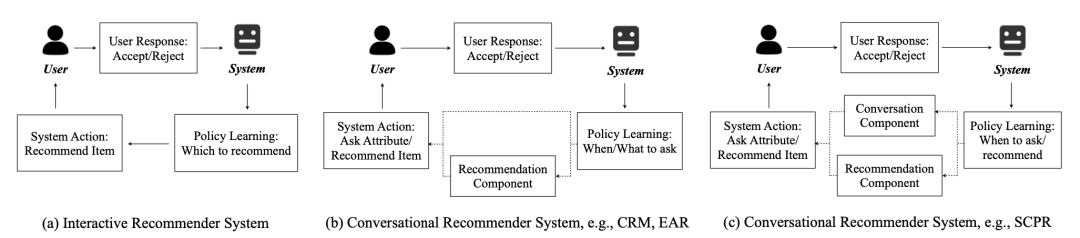
本文指出,过去基于属性的对话推荐系统工作总是将决策过程分到多个模块去完成,这对模型的可扩展性造成了影响。比如 CRM 和 EAR 的策略模块决定当前是询问还是推荐,以及询问什么问题,其具体推荐项目是什么交由推荐模块来解决;CPR 则缩减了策略模块的动作空间,它只能决定当前是进行询问还是推荐,而具体的询问问题、具体的推荐项目则分别由两个独立的模块来选择。如下图所示。
本文提出的 UNICORN 模型则反其道而行之,作者希望将这三个决策问题(询问还是推荐、询问什么、推荐什么)统一起来。统一的过程意味着强化学习动作空间的变大,必然面临着训练过程中采样效率的问题。UNICORN 采用了四个模块来完成这一策略学习的统一过程,如下图所示。
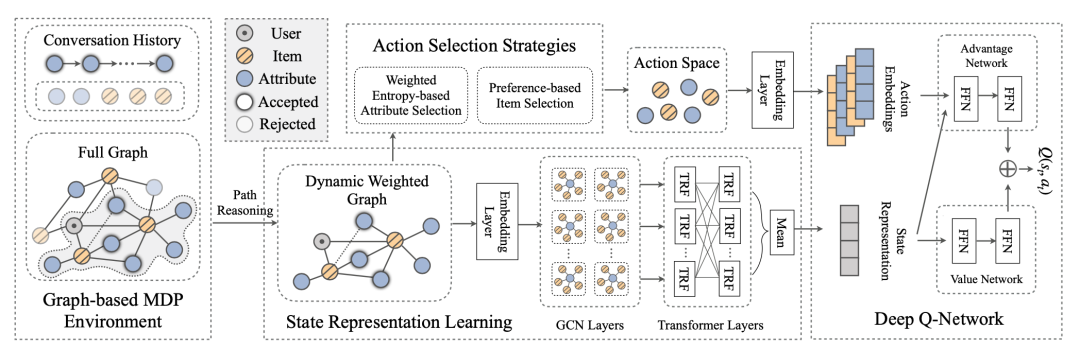
首先是最左边的 Graph-based MDP Environment,表示 UNICORN 基本上沿用了 CPR 构建的图上路径推理机制,也就是状态转移、各个集合的更新和维护的规则。
其次是状态表示学习模块 Graph-enhanced State Representation Learning,这一块的任务就是将当前对话状态表示成一个向量。这里维护一个随着状态改变的动态权重图,这个图的节点集合由下面规则构成:
该动态子图先经过 GCN 得到各个节点的 embedding,从中选出 中那些节点对应的 embedding 构成输入矩阵 ,输入到序列化建模的 Transformer 层中,得到同样大小的输出矩阵经平均池化操作后得到状态表示 。
第三块是动作选择模块 Action Selection Strategy,这一块的模板是所见强化学习的动作空间。直接将所有动作统一起来的话,动作空间过于庞大,那么可以两类动作(询问、推荐)各选 和 个,从而将动作空间大小控制在 ,有效缓解训练时采样效率不够的问题。UNICORN 选择 top- 个推荐物品的策略是利用表示学习过程中得到的节点 embedding 进行预测,而选择 top- 个询问属性则沿用 SCPR 所采用的最大熵规则。
最后是强化学习决策网络模块 Deep Q-Learning Network。模块的输入是状态表示 以及上一层得到的 个节点对应的 embedding,采用 DQN 算法进行学习训练,细节不再详述。
3 生成式对话推荐
3.1 问题定义
直接介绍问题的形式化定义。令 表示用户集合 中的一位用户 , 表示物品集合 中的一件物品 , 表示词汇表 中的一个词汇 。一个对话 是一系列的语句(utterance)构成的有序列表 ,其中 是对话进行到第 轮时的句子。
在对话的第 轮,推荐模块会根据一定的策略从物品集合 中选择一个候选物品子集 ,对话模块则需要生成当前轮次的回复文本 。值得注意的是,候选物品子集 可能为空,此时对话模块生成的是询问相关的文本,或者仅仅是闲聊文本。
给定上文系统与用户交互的 条语句,生成式对话推荐系统的目标就是生成相应的回复,即推荐结果 和回复文本。
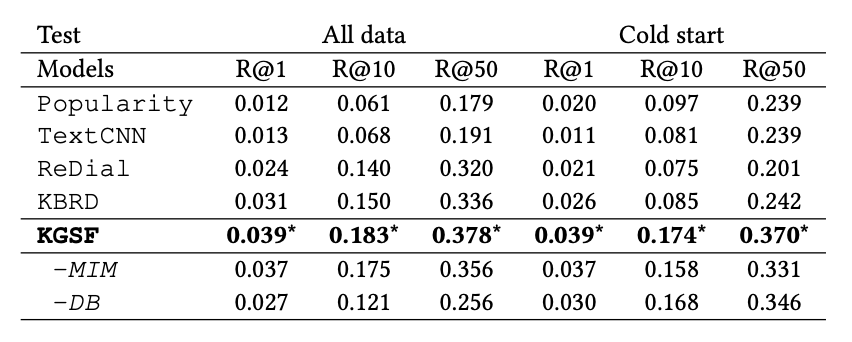
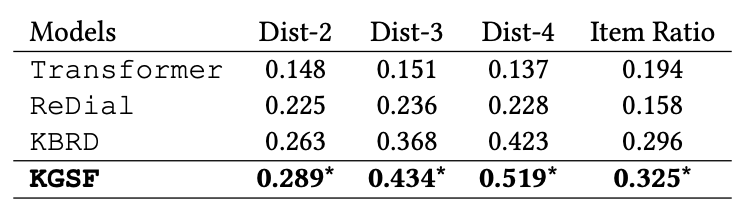
由于生成式对话推荐系统中,对话管理策略被隐式地包含在端到端模型内部,人们通常只分别评测推荐模块和对话模块。对于推荐模块,常沿用 Top- 推荐的评测指标召回率 Recall@K;而对于对话模块,常使用困惑度 PPL 或者多样性指标 Dist 来进行自动化评测,也有的工作对生成的文本进行人工评测,以评估文本的流利程度和信息含量。此外,模型 KGSF 和 NTRD 还采用了 Item Ratio 来评估对话中是否出现了足够多的推荐物品结果。
本节介绍的四个模型(除 TGReDial 外)都采用生成式对话推荐领域数据集 REDIAL 来进行训练和评测。这是由 Amazon Mechanical Turks 的工作人员在一定的指导下相互交谈得到的、电影场景下的对话推荐数据集。该数据集一个典型的对话例子如下图所示,HUMAN 是数据集中的电影推荐者,而 SEEKER 是数据集中的电影寻求者;HRED 和 OURS 是模型输出内容而非数据集原有数据。

3.2 降噪协同 - ReDial
本节介绍 NeurIPS 2018 的工作:Towards Deep Conversational Recommendations [6]。
这篇工作是最早对于生成式对话推荐的探索,它对于后续工作最大的影响是其构造的电影场景下的对话推荐数据集 REcommendations through DIALog(REDIAL)。该数据集共包含 6924 部电影、956 位用户、11348 个对话,平均每个对话由 18 个英文句子构成,并保证每个对话中至少提到 4 部电影。对话记录中除了文本和所提到的电影信息以外,还包含语句的情感判断标签。
文中还提到,由于该数据集的规模对于神经网络的训练需求来说相对比较小,如果从头开始(from scratch)用 REDIAL 来训练模型容易导致过拟合。所以本文随后提出的模型架构能够先按模块分别用更大的数据集训练,然后再一起端到端地用 REDIAL 训练,而且后续的大部分工作也继续沿袭了这一观点,都不同程度地采用了预训练技术。
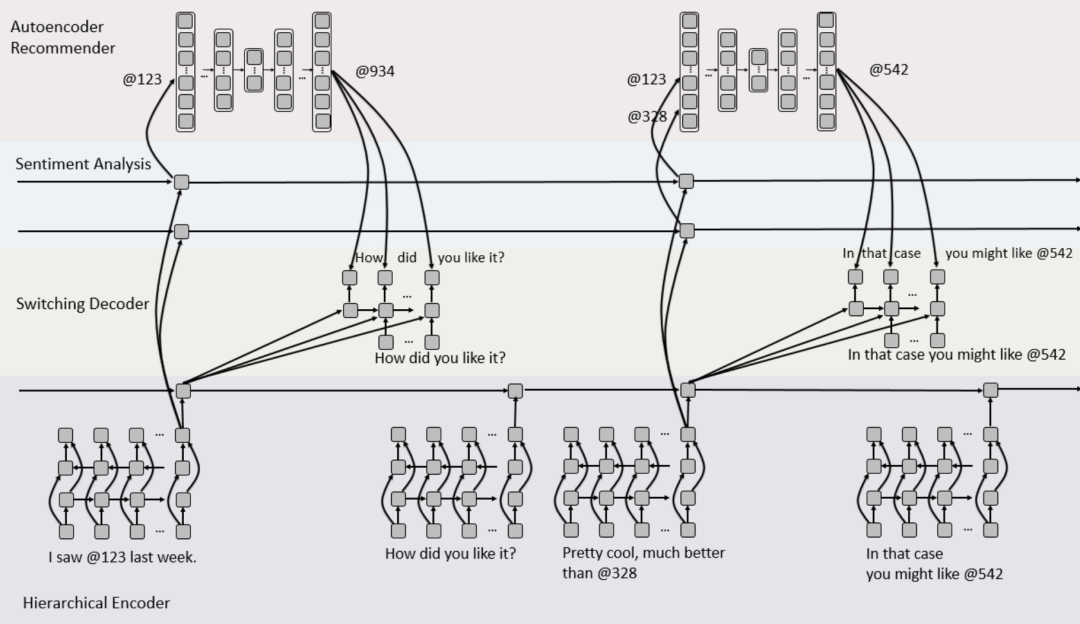
本文所提出模型的整体架构如上图所示。在对话模块一侧,使用了层次化的 RNN 架构 HRED 来编码对话,并采用了预训练的 Gensen 句子向量表示。HRED 得到对话的隐含向量表示之后,一方面会给情感分析 RNN 进行计算,一方面给 Switching Decoder 来将推荐结果融入到对话中,另外还能用于给 RNN 解码出回复语句。而在推荐模块一侧,模型采用了降噪自编码器,同时利用了情感分析模块的计算结果进一步修正推荐结果。训练时,推荐模块先在电影评分数据集 MovieLens 上进行预训练,而后才在 REDIAL 上进一步训练。
该模型基本上把 REDIAL 数据集的信息都利用上了,但接下来我们将看到,后续的工作基本都不再利用情感标签,而是直接假设对话中提到的电影即是用户所喜欢的电影。这种假设一方面在很大程度上简化了问题,另一方面也给推荐结果带来了一定的偏差。
3.3 知识增强 - KBRD
本节介绍 EMNLP 2019 的工作:Towards Knowledge-Based Recommender Dialog System [7]。
作者在文中指出,ReDial 采用的推荐模型(AutoRec)需要依据上文提到的物品进行推荐,当对话中没有提到物品时则无法向用户提供推荐结果。本文提出的基于知识的对话推荐系统 KBRD 则不会面临这个问题,因为 KBRD 引入了知识图谱,并将对话中出现的实体与图上节点对齐,使得系统有可能根据对话提到的实体进行推荐。同时文章指出,理想的对话推荐系统需要将对话模块与推荐模块高效地结合起来,使得两部分相互促进。
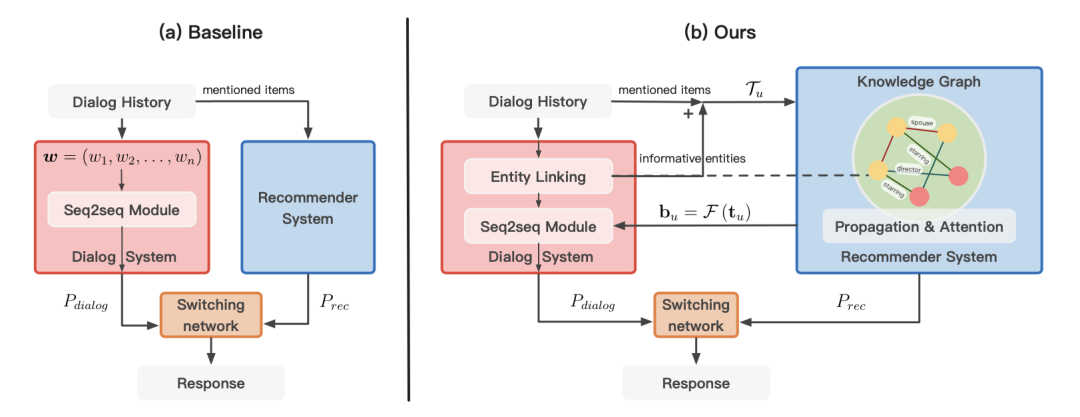
具体来说,KBRD 引入了开源的知识图谱 DBpedia,并从中抽取与 REDIAL 任务相关的子图,将上面的节点与 REDIAL 中的实体进行对齐。这里的“实体”不仅包括 REDIAL 数据集中的电影实体,还包括对话中可能出现的其他实体,比如导演、演员、影片类别等。于是,我们就能够用对话中出现的实体作为特征,来代表当前这个用户:
在构建好与任务相关的知识图谱之后,使用图神经网络模型 R-GCN 来学习图上实体的向量表示,经过若干层的传播和更新,可以得到实体的 Embedding 构成的矩阵 ,其中 表示实体的数量, 表示实体 embedding 的维度。根据上面提到的用户实体集合 从 中抽取相应的 embedding 就能够得到该用户的矩阵表示 。
我们希望能够将用户矩阵降维表示为用户 embedding,从而与电影实体 embedding 比对来完成推荐的排序。KBRD 采用自注意力机制来进行融合 中不同实体对应的 embedding,从而得到用户表示 :
最终通过向量内积来计算每个实体的得分,如下所示。其中 用于将非电影实体的值设置为负无穷,避免它们成为推荐对象。
KBRD 的对话模块采用了非常流行的 Transformer 架构,并在最终生成的词汇分布上加上 Vocabulary Bias:
回顾整个模型,对话模块获得的文本中的实体信息对推荐产生促进作用,而推荐模块产生的用户 embedding 最终转化为 Vocabulary Bias 来促进对话的生成,使得对话词汇与场景更为相关。这种对话与推荐相互促进的结构也获得了相当不错的结果。
3.4 语义融合 - KGSF
本节介绍 KDD 2020 的工作:Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion [8]。
本文的作者指出,过去的生成式对话推荐系统工作没能很好地处理文本信息,基于自然语言的表达与基于实体构建的用户偏好表示二者存在天然的语义差异。因此,本文提出了模型 KGSF,通过互信息最大化的多知识图谱语义融合技术,打通不同类型信息之间的语义差异,同时充分发挥了词汇级、实体级两个知识图谱的作用,提升了对话推荐性能。
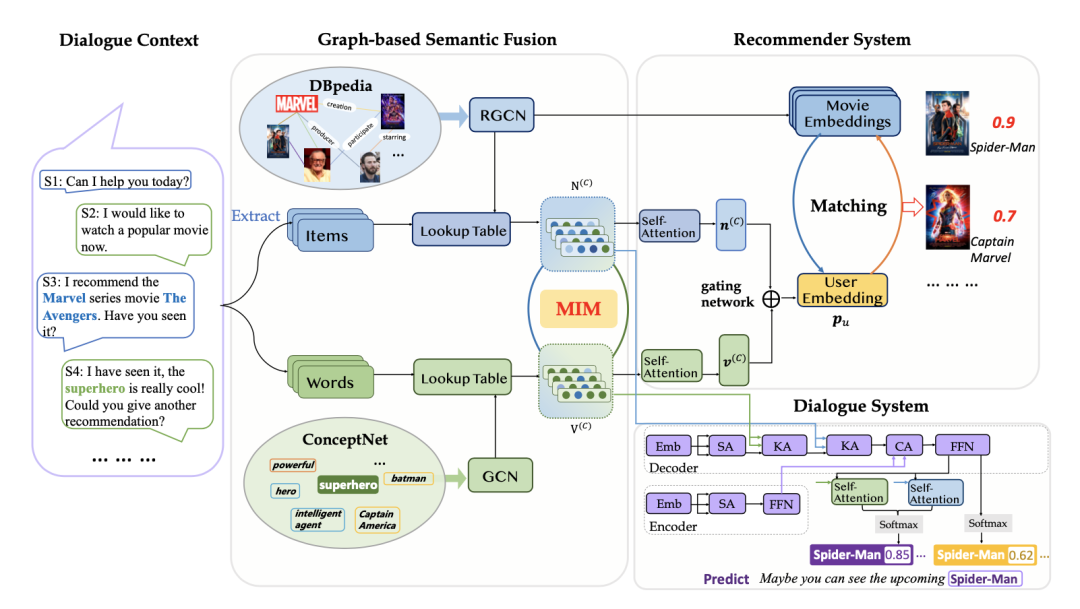
KGSF 的整体架构如上图所示。在实体信息方面,其沿用 KBRD 的方案,使用 R-GCN 对任务相关的 DBpedia 子图进行编码,得到一系列实体 embedding。在词汇信息方面,采用类似的方法将对话文本中的词汇与 ConceptNet 中的词汇对齐,使用图卷积神经网络 GCN 进行编码得到 word embedding。
模型的核心在于使用互信息最大化算法来对两类 embedding 进行预训练。两个随机变量 和 的互信息表示为 ,由于难以直接计算,所以本文采用如下的不等式来估计:
其中 和 分别表示正例对和负例对, 表示由神经网络预测的一个实数值。具体到问题来说,对于任意由实体和词汇组成的二元组 来说有:
其中 和 分别是实体 和词汇 经过图神经网络学到的 embedding, 是可训练的参数矩阵。训练时,以共同出现在同一对话中的实体、词汇二元组作为正例,以随机采样得到的实体、词汇二元组作为负例,最大化二者经过上述网络预测所得值的差,就完成了互信息最大化算法的实现。
最后,用户的实体矩阵表示、词汇矩阵表示经过与 KBRD 中介绍的一样的自注意力层,分别得到实体角度的用户 embedding 和词汇角度的用户 embedding,通过一个门控机制层(参数可调整的向量加权求和层)就得到最终的用户 embedding,从而完成推荐任务。
KGSF 的对话模块同样利用推荐模块的计算结果来促进对话文本的生成,不过与 KBRD 不同的是,KGSF 修改了 Transformer 的内部结构,将用户或者说对话构造的实体矩阵 、词汇矩阵 通过多头自注意力机制逐步融入解码过程中,使得生成的对话与用户偏好更具备关联性。
KGSF 与以往模型在推荐指标(召回率 Recall)和对话指标(多样性指标 Distinct 和 Item Ratio)上的比较如下面两张图所示。
3.5 话题引导 - TGReDial
本节介绍 COLING 2020 的工作:Towards Topic-Guided Conversational Recommender System [9]。
本文的作者指出,当前的对话推荐数据集仍有两个显著的问题:
-
这些数据集假设用户与系统进行交互时有明确的需求,因此缺乏主动的引导来将非推荐场景的对话转变为推荐场景的对话。 -
许多对话推荐数据集是由数据标注平台的工作人员对话来生成的,这种构建过程难以捕捉现实世界场景丰富且复杂的情况。
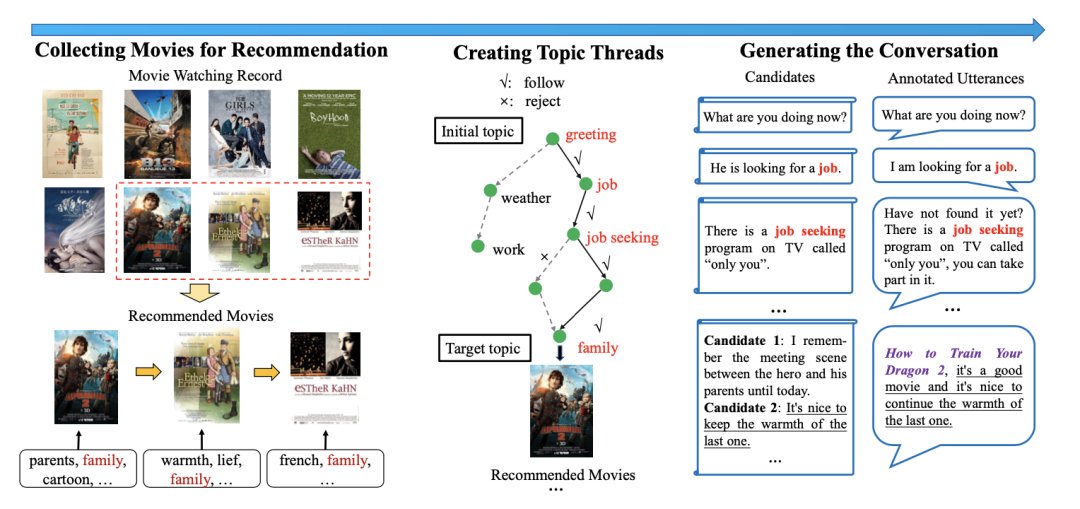
因此,本文构建了一个基于话题引导的对话推荐数据集。作者采用半自动化的方式来构建该数据集,先基于来自真实场景的数据集 Douban Movie 来生成候选语句,再人工标注得到对话,其流程如上图所示。
第一阶段是收集电影序列,对于某一用户可以从其观影记录中的电影构建若干子序列,其中每个序列的电影都有相同的话题标签;接着是构建话题转移的通道,作者借助深度优先搜索算法,在知识图谱 ConceptNet 上找到一条从最初话题(greeting)到目标电影话题的转移路径;最后是利用深度学习模型从话题生成对话文本,并进行人工修改和润色,以保证对话的流畅性。
基于该话题引导数据集 TGReDial,作者将生成式对话推荐问题稍加扩展,引入话题预测任务,并构建了一套模型来解决这一问题。在推荐模块中,本文针对数据集提供的用户历史交互记录,使用了序列化推荐模型 SASRec;在话题预测模块中,本文分别用不同的 BERT 编码器来计算历史对话、历史话题序列、用户介绍文本的隐含表示,并通过简单的前馈神经网络来预测下一个话题;在回复生成模块,本文使用 GPT-2 结合所预测的话题、推荐结果、历史对话序列来生成回复。
3.6 可控生成 - NTRD
本节介绍 EMNLP 2021 的工作:Learning Neural Templates for Recommender Dialogue System [10]。
上面介绍中都没有提到推荐模块给出的推荐结果是如何融入到生成的对话文本中,构成一个完整的推荐对话语句的。事实上,ReDial、KBRD、KGSF 三个模型都采用一种转换机制来判断生成对话文本的下一个符号(token)是普通的词汇,还是推荐的电影实体。形式化地来说,下一个 token 预测如下:
其中 是整个对话的隐含表示,它经过神经网络得到门控参数 来控制下一个生成的 token。
本文认为这种将实体融入对话的方法具有如下问题:
-
不能总是将推荐结果精确且恰当地融入到生成的回复中。 -
推荐结果总是在训练集中提到的物品,缺乏泛化性。
可以用一个更具体的例子来理解现有方案可能存在的问题。比如系统回复中出现的推荐结果可能与回复文本本身关系不大,因为对话和推荐两个模块缺乏相关的通信机制,来确保生成的物品 token 和上下文的文本词汇 token 具备较强的相关性。
因此,本文提出了 NTRD 模型,它借鉴传统的“填槽”(slot filling)机制和现代的自然语言生成技术,使得系统既能像前者一样可控地生成文本,又能像后者一样生成自然流利的语言。
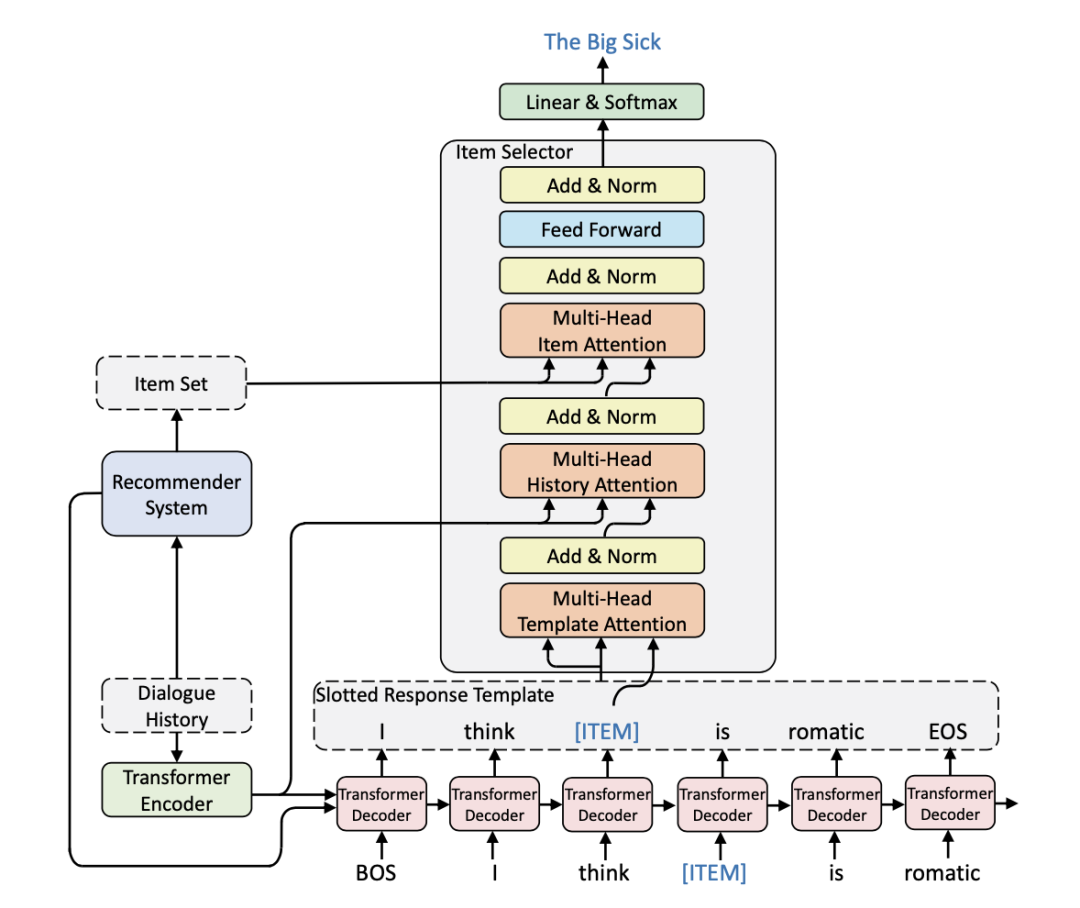
NTRD 整体上沿用了 KGSF 的架构,但是在两方面进行了改造,让系统具备更可控的文本生成能力。首先是将 KGSF 的对话模块改造为 Response Template Generator,具体做法是将数据集中的所有物品(电影)全部替换为特殊符号 ,使得生成的对话不带具体的电影信息,而是一个个句子模板(template)。
其次是构造一个物品选择器来填写模板中的 槽,NTRD 使用堆叠的多头注意力函数来构造选择器。在这个堆叠的结构中逐步融入了模板词汇相关信息、模板的槽相关信息、推荐模块得到的候选物品相关信息,从而完成在推荐模块所提供结果的基础上更加精确的推荐。这个堆叠式的选择器结构如下图所示:
由于对话推荐结果最终呈现在用户眼前的是单个语句中的单个物品推荐,而非传统的 top- 推荐,所以本文引入了回复中的召回率推荐指标(Recall in Response) ReR@K 来对生成的对话进行评测,其中当 是就是与实际应用场景最接近的评测结果。实验结果表明,在对话模块的性能上,NTRD 相对于以往的工作有显著的提升。
4 总结
4.1 未来展望
基于深度学习的对话推荐系统发展时间并不久,在本文所提到的两条探索路径上仍有许多问题等待解决。综述文章 [1] 从五个角度提出了值得进一步研究的方向:
-
三个子模块的共同优化 -
推荐系统的去偏 -
精心设计的多轮对话策略 -
引入更多的知识如多模态数据 -
更合理的评测机制和更好的用户模拟器
另外,正如上文所述,基于属性的对话推荐和生成式对话推荐二者,在对话推荐系统的三个模块上各有所侧重。未来是否能出现更加统一的,既能够显式操控对话策略,又能够灵活地生成流畅的自然语言文本的对话推荐系统?作为一个具有潜在商业价值的领域,它无疑值得更多的探索。
4.2 论文列表
笔者整理了 68 篇领域相关论文,并分类如下:
-
综述和教程(Survey and Tutorial) -
工具包和数据集(Toolkit and Dataset) -
基于属性的对话推荐系统 -
生成式对话推荐系统 -
其他工作以及学位论文
同时,笔者整理了 10 篇文献作为快速入门(Quick Start)的推荐读物,读者也可以在论文列表中快捷地找到论文主页、PDF、数据集、官方源码实现等链接。本仓库将继续关注对话推荐系统领域,并持续更新。
https://github.com/RUCAIBox/CRSPapers
参考文献
[1]. Advances and Challenges in Conversational Recommender Systems: A Survey.
[2]. Conversational Recommender System.
[3]. Estimation–Action–Reflection: Towards Deep Interaction Between Conversational and Recommender Systems.
[4]. Interactive Path Reasoning on Graph for Conversational Recommendation.
[5]. Unified Conversational Recommendation Policy Learning via Graph-based Reinforcement Learning.
[6]. Towards Deep Conversational Recommendations.
[7]. Towards Knowledge-Based Recommender Dialog System.
[8]. Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion.
[9]. Towards Topic-Guided Conversational Recommender System.
[10]. Learning Neural Templates for Recommender Dialogue System.
[11]. CRSLab: An Open-Source Toolkit for Building Conversational Recommender System.
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。




