一文总结多样化推荐研究趋势
© 作者|林子涵
机构|中国人民大学信息学院
研究方向|推荐系统
本文主要基于最近2年发表在顶级会议(KDD、SIGIR、WWW、CIKM、IJCAI等)的多样化推荐相关论文,介绍最新的研究工作,梳理其背后的技术脉络,同时在最后总结多样化推荐中潜在的研究方向。本文旨在帮助推荐系统相关研究人员快速熟悉和掌握多样化推荐的最新研究进展,如有遗漏或错误,欢迎大家指正。
1.什么是多样化推荐
推荐系统(Recommender System)旨在挖掘用户的兴趣并为每个用户推荐多个与其兴趣匹配的商品。通常来说,用户的兴趣是多样的,即用户对于不同种类或不同属性的商品都会表现出或多或少的兴趣,其中用户可能更加偏好某一类商品。在这种情况下,一个多样化的推荐结果应当包含尽可能不同的商品来满足用户的多种兴趣,而不是只推荐用户最感兴趣的单一类别商品。然而,增加推荐结果的多样性往往会带来准确性的损失,如何平衡推荐的准确性和多样性就成为了一个关键挑战。

2.经典的多样化推荐方法
由于多样化推荐系统最后的推荐结果中商品之间的差异性尽可能的大,所以经典的方法都是基于后处理的方法,即首先使用推荐算法获取到用户对于商品的偏好打分,再计算出商品之间的相似度,最后根据这两项分数贪心的选择一个推荐的商品集合,在满足商品分数高的前提下,使得集合内商品的相似度尽量低。两个经典的后处理方法分别是最大化边缘相关性(Maximal Marginal Relevance,MMR)和行列式点过程(Determinantal Point Process,DDP)。
MMR算法最早在SIGIR1998上面被用户搜索领域,其从所有候选文档中逐个选择文档放入结果列表中,选择文档是同时考虑了文档与搜索内容的匹配程度和此文档与结果列表中其他文档之间的最大相似度。具体来说,其将文档与搜索的相关性与文档之间的相似性以一定的权重相减作为目标函数,每次贪心的选择目标函数值最大的文档加入结果中,以实现在搜索结果中增加多样性的目的。
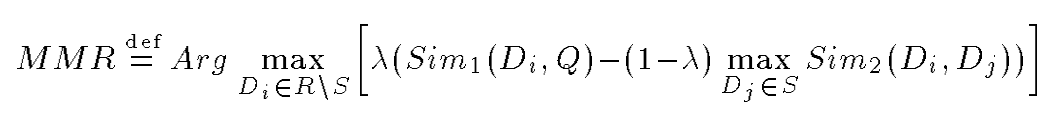
MMR算法中的目标函数只考虑了商品间的二元相似性,这与推荐商品集合的整体相似性还存在一定的偏差。为了解决这个问题,DDP算法在2018年的NIPS上被应用到多样化推荐领域。其在推荐商品集合上定义了一个核矩阵,核矩阵的行列式便同时考虑了所有商品的相关得分和整体的相似度,并且构建这个核矩阵也可以通过贪心法逐个选择目标函数值最大的商品,同时通过最大化后验推断的方法,这个构建过程可以极大的加速。并且此方法可以天然的使用商品嵌入向量计算商品间的相似的,所以在多样化推荐的研究中有大量基于DDP的变种方法,后续的介绍中我们也可以看到其最新的应用。
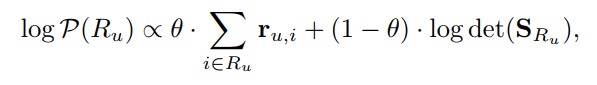
3.前沿多样化推荐研究
多样化推荐作为推荐系统研究的一个较冷门方向,近几年发表在顶会的工作虽不多,但也不乏一些高质量工作,下面我将从数据增广、训练策略、模型结构以及特殊场景下的多样化推荐四个方面对最新的研究工作简单介绍。
3.1利用数据增广提高推荐多样性
建模用户兴趣的根本是学习用户交互行为的模式,高质量的交互数据成为了捕捉多样兴趣的关键,利用一系列技术为用户构建潜在的多样交互数据成为了这类模型的核心思想。
[KDD2020] A Framework for Recommending Accurate and Diverse Items Using Bayesian Graph Convolutional Neural Networks
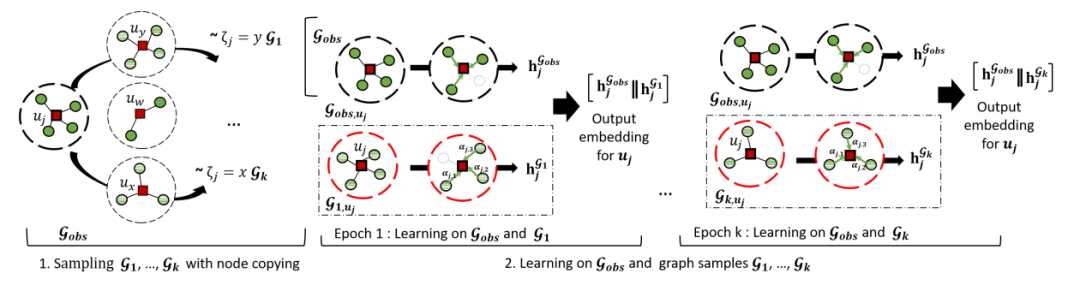
这篇文章来自华为诺亚方舟实验室,其提出了一种使用节点复制的贝叶斯图神经网络(BGCN)。在这个模型中初始的U-I交互二部图上的节点根据其邻居集合的重叠度进行了重新的映射,得到了一个新的采样图,最终使用采样图与原图上分别使用GAT模型进行消息传播,得到的输出合并用于推荐。这种方法本质上可以看作一种图数据增广的策略,即对图的邻接矩阵进行一定程度的扰动,其定义的数据增广方式为每个用户节点的邻居可能被替换为与其行为相似的其他用户节点的邻居,通过增加数据层面的不确定性来提高模型的承载力,防止对用户兴趣建模的极端化。
[WWW2021] Future-Aware Diverse Trends Framework for Recommendation
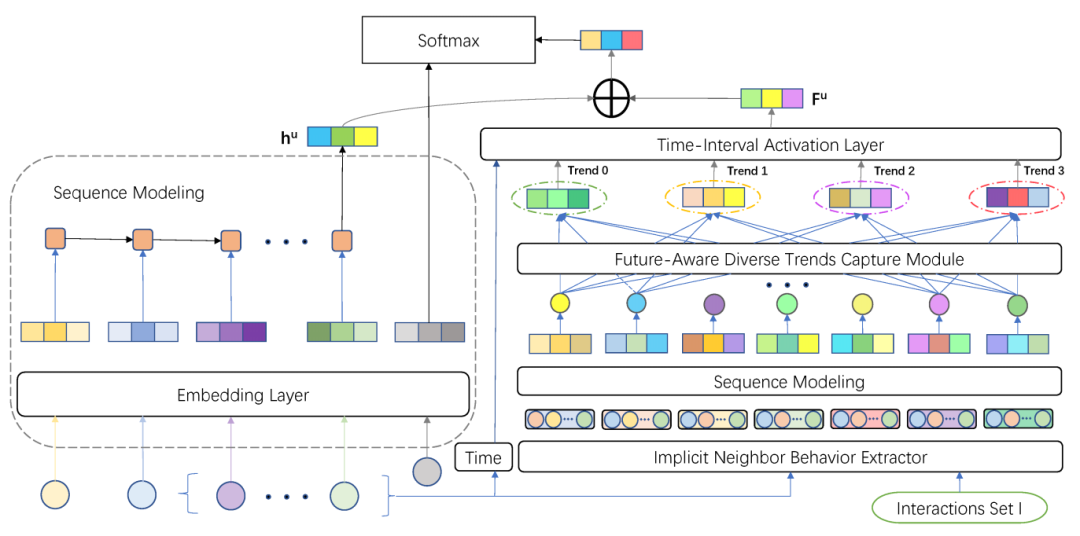
本文来自于腾讯核浙江大学,提出了一种用于增强序列化推荐模型多样性的框架(FAT)。对于一个用户的行为序列,首先使用序列模型(LSTM)获取到当前用户的兴趣,再将当前用户的打分向量与其他所有用户打分向量计算皮尔森系数作为用户之间的相似度信息,再根据此相似度选择一些邻居用户,从邻居用户的交互中选择时间大于当前时间的未来交互序列并同样使用序列模型得到特征,再通过一个考虑时间信息的注意力层得到未来的趋势信息,与当前用户的序列特征一同用于推荐。
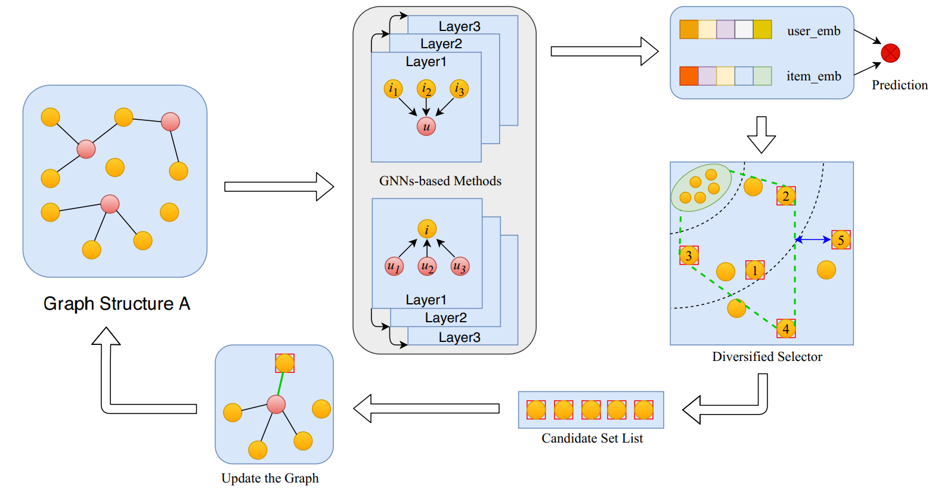
[RecSys2021] Dynamic Graph Construction for Improving Diversity of Recommendation
本文来自于美团,提出了一种动态图构建的方法用于提高推荐多样性。现有的基于GNN的推荐模型大都采样一阶邻居聚合的方法进行端到端的训练,但是这种GNN结构会使得占据主导地位的节点特征淹没长尾节点的特征。为了解决这个问题,其将端到端的训练过程进行多轮迭代,每一次都为图结构增加一些新的边,以此希望能够缓解邻居聚合时的特征分布偏差。在添加新边时,为每一个用户节点贪心的选择新的邻居商品集合,在选择时同时考虑了商品与用户的匹配程度和商品与已有邻居之间的距离,力求新加入的商品尽量多样。其本质上还是通过发掘潜在的多样交互以丰富用户数据。
3.2定制训练策略提高推荐多样性
[WWW2021] DGCN: Diversified Recommendation with Graph Convolutional Networks
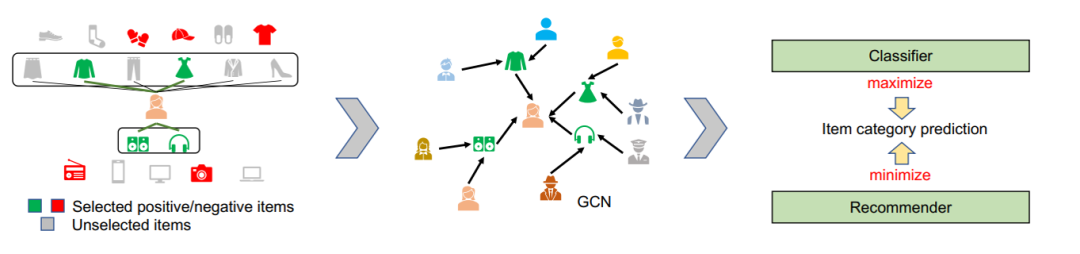
本文来自清华大学,提出了一个图卷积网络用于多样化推荐。其首先分析在图模型中如果使用所有的用户交互聚合得到用户特征,则用户特征会带有明显的类别属性,导致推荐偏向其交互更多的类别,为了消除这种类别带来的偏差,其提出了三个训练策略:1.使用一个训练任务进行对抗训练,最小化商品特征向量与其对应的类别标签之间的联系。2.图卷积时对邻居进行采样,采样的权重由所有的邻居商品的类别分布决定,以平衡不同类别下的邻居数量。3.根据类别进行负采样,按照一定比例选择随机采样或采样同一类别采样可以平衡准确性和多样性。本文是在GNN的框架下提出了一种较为通用的采样策略以提高类别多样性。
[SIGIR2020 short] Enhancing Recommendation Diversity using Determinantal Point Processes on Knowledge Graphs
本文来自里昂大学研究团队,提出了一种结合知识图谱嵌入(KGE)和行列式点过程(DPP)的多样化推荐方法。直觉上讲,知识图谱能够为商品提供丰富的属性信息,应当能够帮助商品特征建模,所以本文中将交互关系与知识图谱中的各种关系统一使用TransE、TransH等知识图谱嵌入的方法进行建模,得到用户的商品的嵌入向量后,将用户与商品向量之间的距离作为核矩阵的对角线,商品向量之间的点积作为其余部分,得到的核矩阵便可以使用上面介绍的DPP方法进行贪心求解,也实现了对推荐结果的重排序。
3.3设计模型结构提高推荐多样性
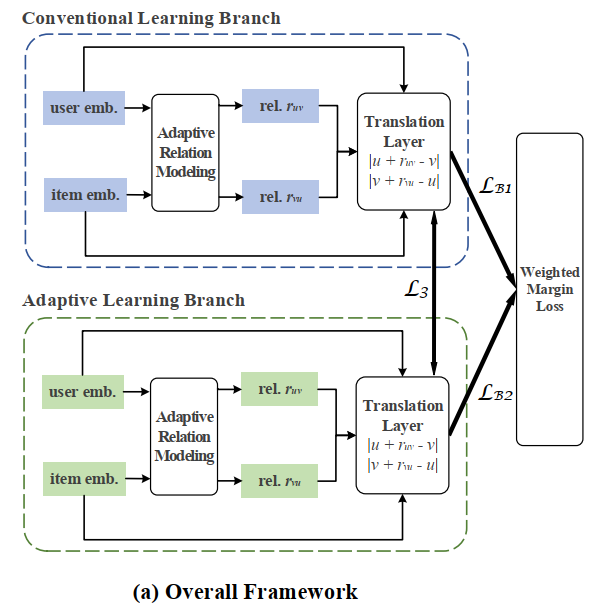
[WWW2021] Enhancing Domain-Level and User-Level Adaptivity in Diversified Recommendation
本文来自武汉大学和香港理工大学,提出了一个考虑了领域级多样性的双分支网络用于产生多样化推荐。其考虑了在不同领域数据集上用户对于多样化内容的需求程度不同,首先统计数据集整体的偏好分布,整体偏好分布的集中度用于决定两个模型分支各自所占的比例。两个分支都采用距离模型来建模交互数据,不同在于采样时类别的权重互为倒数,同时用户的历史交互在类别上的分布也被编码为向量加入到关系中。其在模型上将准确性目标和多样性目标放在两个分支中,通过平衡权重来达到多样性的推荐。
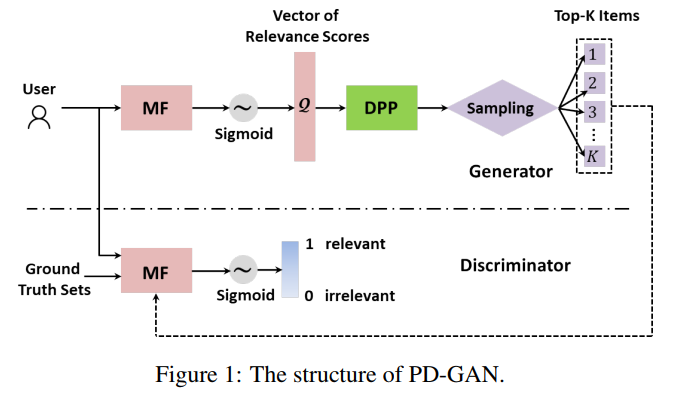
[IJCAI2019] PD-GAN: Adversarial Learning for Personalized Diversity-Promoting Recommendation
本文来自于阿里-南洋理工大学团队,提出了一种基于DPP的生成对抗网路模型用于多样化推荐。其在模型层面将负责准确性和多样性的模型分开,分别作为生成器和判别器,在生成器中首先使用矩阵分解模型(MF)来建模用户的偏好和商品之间的相似度,再将得到的向量构建为核矩阵输入到DPP模型中,使得DPP模型的输出尽量满足多样性,再将推荐结果列表交给判别器。判别器同样使用一个MF模型训练,其对得到的推荐列表进行打分,让结果的准确性尽量高,通过平衡两个目标实现多样化的推荐。其将双目标平衡与生成对抗模型相结合的思路十分巧妙。
[AAAI2021] A Hybrid Bandit Framework for Diversified Recommendation
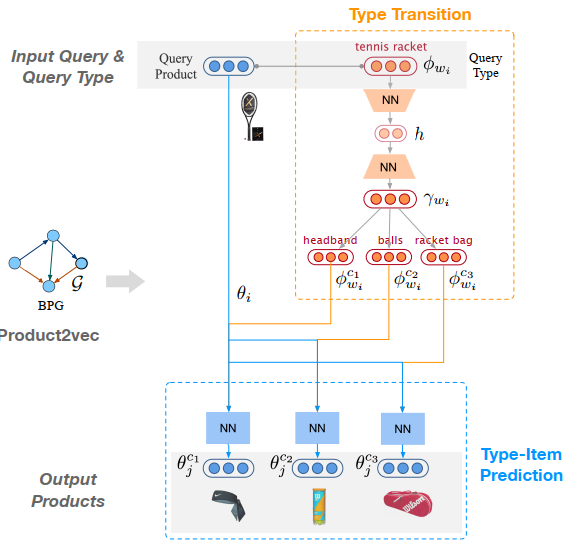
本文同样来自阿里-南阳理工大学团队,其针对交互推荐的场景提出了一种集合模函数和分布函数的多臂老虎机框架。其分别定义了评价一个推荐结果相关性的模长函数和评价结果多样新的分布函数,并推导出二者在单词决策下的反馈变化,将推荐集合的生成建模为一个多步骤的决策过程,以使用强化学习的策略最大化累计奖励,最终实现推荐的商品集合在贪心情况下满足相关性和多样性的最大化。同时其理论证明了其优化策略可以在有限轮的学习下达到最优的累计奖励。
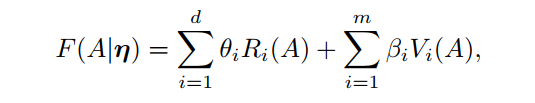
3.4特殊场景下的多样化推荐
[CIKM2021] P-Companion_ A Principled Framework for Diversified Complementary Product Recommendation
本文来自UCLA和亚马逊,针对的推荐场景为互补产品推荐问题。在互补产品推荐中,需要针对用户的兴趣和当前已经购买的商品,为其推荐与当前商品配套的其他商品。面对这个场景,本文提出了一种层次化的推荐模型,其首先将商品间的共同购买关系建模为一个图,通过图嵌入算法得到商品的隐层表示,当一个商品和其所属的类别作为查询输入时,首先使用一个编码器模块针对输入类别预测其输出类别,再将输出类别和商品一起输入到预测模块中,在每一个目标类别下预测要推荐的商品。其通过对推荐过程进行分层处理,保证了在类别上的严格多样性。
[KDD2021] Sliding Spectrum Decomposition for Diversified Recommendation
本文来自小红书团队,针对小红书APP中独特的滑动浏览特性,设计了一种滑动频谱分解的方法来实现长商品序列上的多样性。用户的整个浏览序列可以根据固定的时间窗口进行切分,得到一个列数固定的矩阵,其中每一行便是用户在一个窗口内的浏览序列,则每一行对应的二维嵌入矩阵的行列式边可以衡量其多样性,考虑到行列式与矩阵的奇异值的关系,这样的过程可以拓展到三维矩阵上,对三维矩阵进行奇异值分解后,奇异值的乘积便可以近似作为多样性的体现。由此总体目标中的相关性和多样性便能够一起优化
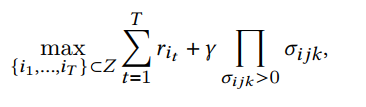
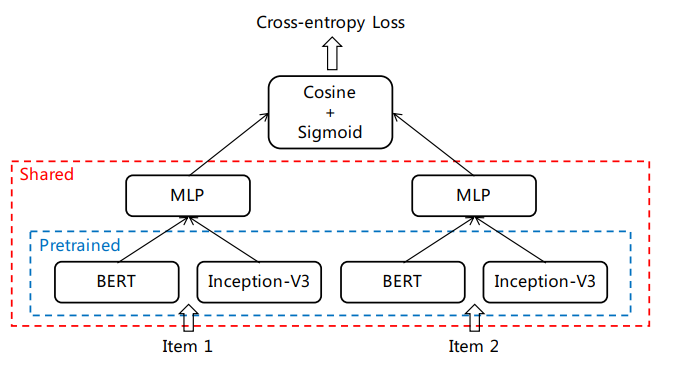
这其中比较关键的一步便是得到商品的嵌入向量,这里其综合了基于内容和基于协同的模型,提出了一种融合的CB2CF模型,将文本、图片和商品间的共现关系一并编码到向量中。
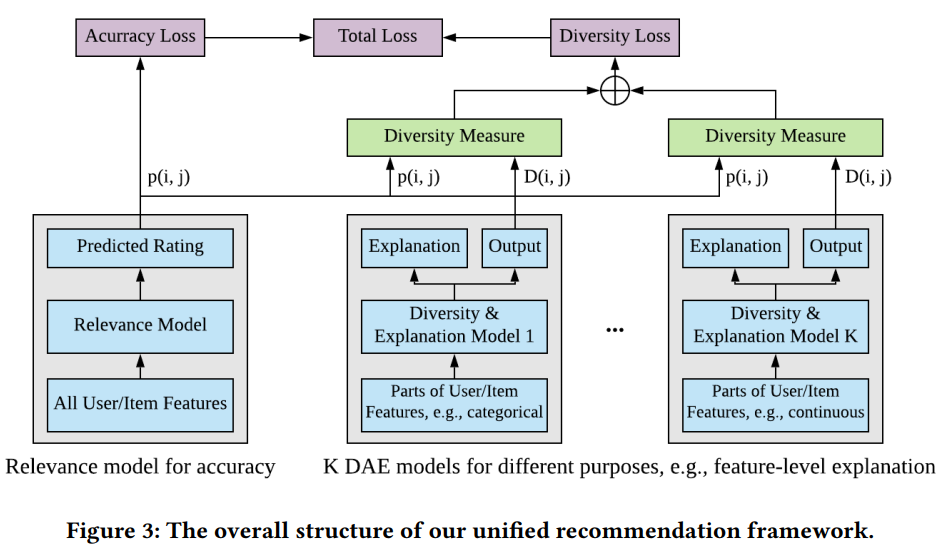
[CIKM2021] On the Diversity and Explainability of Recommender Systems_A Practical Framework for Enterprise App Recommendation
本文来自Salesforce团队,针对企业场景下的APP推荐问题,提出了一个保证结果的多样性和可解释性的框架。其使将用户在所有商品上的分布简化为一个高斯分布,通过KL散度限制每个用户对应高斯分布与标准高斯分布之间的距离,同时使用多个平行的模块处理不同的特征组合,将输出作为推荐结果在特征层面的解释,最后通过在最终loss中平衡准确度目标和分布距离目标来实现对多样性的保证。
4.总结与未来方向
随着现在各类应用对于推荐系统的依赖,针对多样化推荐的需求也日益明显,最近相关会议和期刊上相关的模型也层出不穷,但总体上针对多样性的研究依旧无法避免设计方法以平衡准确性和多样性,具体体现在数据、策略、模型等不同层面。最后,总结一些目前尚未被很好考虑的多样化推荐方向,希望各位相关研究人员能够继续突破,产出高质量工作。
考虑个性化的多样性:不同用户对于多样性的喜好不同,在用户层面平衡准确性和多样性能带来细粒度的多样性
考虑时许的多样性:现有方法往往关注在一次推荐中保证多样性,但是多次推荐结果之间的多样性没有考虑
可解释的多样性:为多样化的推荐结果生成解释能够帮助推荐系统理解推荐行为
考虑视觉的多样性:推荐的商品往往以图片形式展示,将视觉上的多样性考虑在推荐中同样能提升用户体验
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于微信公众号试行乱序推送,您可能不再能准时收到机器学习与推荐算法的推送。为了第一时间收到机器学习与推荐算法的干货, 请将“机器学习与推荐算法”设为星标账号,以及常点文末右下角的“在看”。
由于微信公众号试行乱序推送,您可能不再能准时收到机器学习与推荐算法的推送。为了第一时间收到机器学习与推荐算法的干货, 请将“机器学习与推荐算法”设为星标账号,以及常点文末右下角的“在看”。



