最新!五大顶会2019必读的深度推荐系统与CTR预估相关的论文
导读:本文是“深度推荐系统”专栏的第四篇文章,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文主要总结一下深度推荐系统相关的几大顶会(包含ICML2019/ KDD2019/ IJCAI2019/ WWW2019)必读的几篇论文,各位老铁学不动也得学请收好。欢迎转载,转载请注明出处以及链接,更多关于深度推荐系统优质内容请关注如下频道。
知乎专栏:深度推荐系统
微博:深度传送门
公众号:深度传送门
强化学习
1. Generative Adversarial User Model for Reinforcement Learning Based Recommendation System, ICML 2019
作者:Xinshi Chen、Shuang Li、Hui Li、Shaohua Jiang、Yuan Qi、Le Song
论文:arxiv.org/pdf/1812.1061;解读:zhuanlan.zhihu.com/p/68
在蚂蚁金服被 ICML 2019 接收的这篇论文中,作者们提出用生成对抗用户模型作为强化学习的模拟环境,先在此模拟环境中进行线下训练,再根据线上用户反馈进行即时策略更新,以此大大减少线上训练样本需求。此外,作者提出以集合(set)为单位而非单个物品(item)为单位进行推荐,并利用 Cascading-DQN 的神经网络结构解决组合推荐策略搜索空间过大的问题[1]。
深度CTR预估
说到深度CTR预估的模型,就得祭出网上广为流传的这张图。今年到现在为止,这张深度CTR预估的图谱又下图左边DIN家族系列进行了进一步的丰富。学不动也得学,老铁。
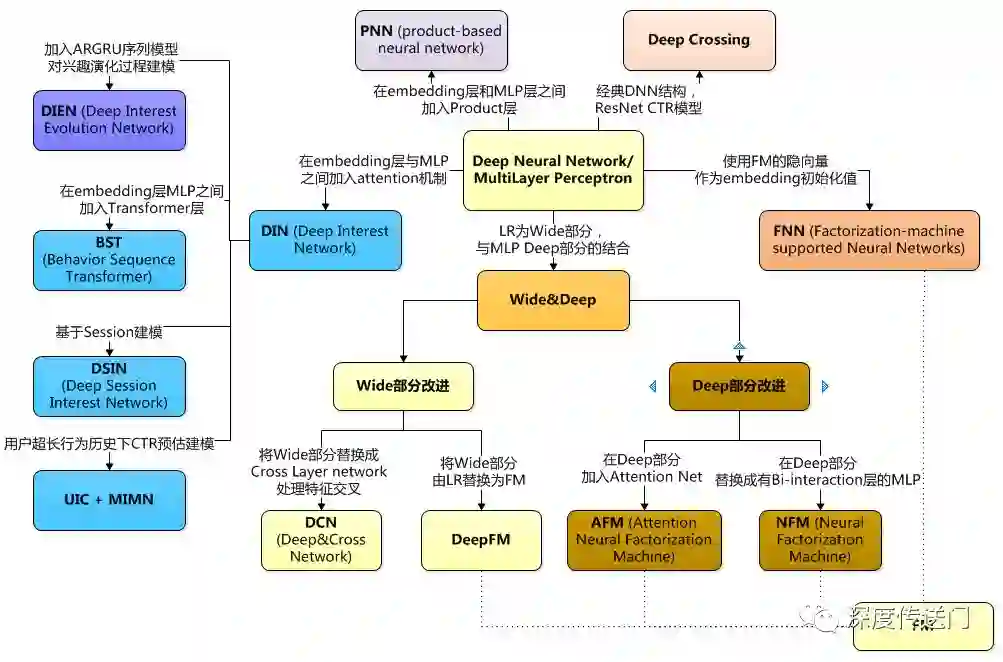
2. Deep Session Interest Network for Click-Through Rate Prediction, IJCAI 2019
作者:Yufei Feng, Fuyu Lv, Weichen Shen, Menghan Wang, Fei Sun, Yu Zhu, Keping Yang
论文:arxiv.org/abs/1905.0648;代码:github.com/shenweichen/
阿里 at IJCAI 2019,考虑到不同用户行为序列的session内行为同构与session之间行为异构的特性提出了基于sesssion的CTR预估模型DSIN。使用self-attention机制抽取session内用户兴趣,使用Bi-LSTM针对用户跨session兴趣进行建模。
3. Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction, KDD 2019
作者:Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, Kun Gai
论文:t.cn/AiN4s4oe
阿里 at KDD2019,通过引入UIC存储单元与MIMN模型联合设计,解决用户超长行为历史下CTR预估建模与在线预测性能瓶颈,效果好于GRU4Rec和DIEN。
4. Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
作者:Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, Wenwu Ou
论文:t.cn/Ai9JgWoJ;解读:t.cn/AiKBda4q
阿里巴巴搜索推荐事业部的新研究,首次使用强大的 Transformer 模型捕获用户行为序列的序列信号,供电子商务场景的推荐系统使用。原有DIN 提出使用注意力机制来捕获候选项与用户先前点击商品之间的相似性,但未考虑用户行为序列背后的序列性质。离线实验和在线 A/B 测试表明,BST 与现有方法相比有明显优势。目前 BST 已经部署在淘宝推荐的 rank 阶段,每天为数亿消费者提供推荐服务[2]。
5. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
作者:Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, Peng Jiang
论文:t.cn/AiNqPitA
Transformer引入推荐系统工业界,应用于利用用户历史点击序列预测下一个点击item,效果超过GRU4Rec。
6. Joint Optimization of Tree-based Index and Deep Model for Recommender Systems
作者:Han Zhu, Daqing Chang, Ziru Xu, Pengye Zhang, Xiang Li, Jie He, Han Li, Jian Xu, Kun Gai。
论文:t.cn/AiN5T8Ks;TDM论文:t.cn/RQ5MrSg
还记得阿里 at KDD 2018的深度树匹配召回模型TDM吗?升级版JTM提出索引与模型同时优化的方案,大幅提升召回效果。
Graph Embedding
7. NetSMF: Large-Scale Network Embedding as Sparse Matrix Factorization, WWW 2019
作者:Jiezhong Qiu, Yuxiao Dong, Hao Ma, Jian Li, Chi Wang, Kuansan Wang, Jie Tang
论文:microsoft.com/en-us/res;代码:github.com/xptree/NetSM
提出适用于大规模网络表示学习方法NetSMF,利用稀疏矩阵分解来学习大规模网络embedding,相对于现有方法DeepWalk/ LINE/ Node2Vec等极大地提高了学习效率,并开源了代码。
8. Representation Learning for Attributed Multiplex Heterogeneous Network, KDD 2019
作者:
论文:arxiv.org/pdf/1905.0166;代码:github.com/THUDM/GATNE;解读:t.cn/Ai9CfBvw
传统的网络(图)表示学习方法一般只针对同构的图,但是实际的图往往都是异构的。只包含异构节点的图的表示学习已经被广泛研究,例如metapath2vec提出了异构的random walk和skip gram。而包含异构边的图的表示学习近来开始被大家所关注,比如MNE给每个点学习多种表示来处理异构边的情形。
这个算法目前在阿里电商场景下得到应用,阿里的数据由用户和商品构成的图就是异构的,不仅包含异构的节点(用户和商品),而且包含异构的边(用户和商品的多种交互行为,比如点击、购买等)。不仅如此,图中的节点还包含着丰富的属性。本文处理的就是这种包含异构节点和异构边的图的表示学习[3]。
9. ProNE: Fast and Scalable Network Representation Learning, IJCAI 2019
作者:Jie Zhang, Yuxiao Dong, Yan Wang, Jie Tang, Ming Ding
论文:t.cn/AiC5cuXF;代码:THUDM/ProNE
ProNE利用矩阵的稀疏性,本质上是用一个低通滤波对原矩阵进行滤波,大大提高了速度,可以得到10-400倍的加速比。
10. Large Scale Evolving Graphs with Burst Detection, IJCAI 2019
作者:Yifeng Zhao, Xiangwei Wang, Hongxia Yang, Le Song and Jie Tang
论文:t.cn/AiC54K0M
动态网络的表示学习最近引起广泛关注,清华今年和阿里巴巴在IJCAI上提出一个叫做BurstGraph的模型,有意思的是主要通过burst的detection来你和动态网络,这和传统大家都希望拟合一个平滑的动态模型不同。
参考文献
[1] 强化学习用于推荐系统,蚂蚁金服提出生成对抗用户模型:zhuanlan.zhihu.com/p/68
[2] 谷歌、阿里等10大深度学习CTR模型最全演化图谱
[3] 阿里将 Transformer 用于淘宝电商推荐:t.cn/AiKBda4q
[4] 阿里电商场景下的大规模异构网络表示学习:t.cn/Ai9CfBvw
[5] 唐杰THU老师的微博:https://weibo.com/jietangthu
相关文章:



