WSDM 2022 | C2-CRS:用于对话推荐系统的由粗粒度到细粒度的对比学习预训练
© 作者|周远航
机构|中国人民大学
研究方向|自然语言处理
本文为对话推荐系统设计了一种新的基于对比学习的粗粒度到细粒度的预训练方法。通过利用由粗到细的预训练策略,可以有效地融合多类型数据表示,从而进一步增强对话上下文的表示,最终提高CRS的性能。文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
论文题目:C^2-CRS: Coarse-to-Fine Contrastive Learning for Conversational Recommender System
论文下载地址:https://arxiv.org/abs/2201.02732
论文开源代码:https://github.com/RUCAIBox/WSDM2022-C2CRS

一. 引言
对话推荐系统(CRS)旨在通过自然语言对话向用户推荐合适的商品。CRS的一个主要目标是在尽可能少的对话轮次内准确捕获用户偏好、完成推荐任务。但这些对话轮次仅包含非常有限的上下文信息来理解用户需求。为了解决这个问题,现有研究已经利用外部数据(如知识图谱、物品评论)丰富上下文信息,并且针对特定类型的外部数据设计了合适的融合模型。
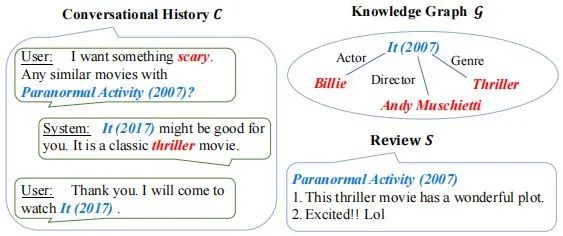
但是对话数据和外部数据通常对应非常不同的信息形式(例如对话话语 v.s. 知识图谱)或语义内容(例如对话话语 v.s. 在线评论),这些数据之间有天然的语义鸿沟,很难将外部数据直接用于改进CRS。当多种类型的外部数据可供使用时,情况变得更加困难。因此,必须开发一种通用方法来弥合不同数据信号之间的语义差距。
要融合多类型上下文数据,一个主要挑战是它们通常对应于不同的语义空间,并且直接对齐它们的语义空间,可能会损害原始表示性能。为了解决这个问题,我们受到了一个重要的启发,即外部数据和对话数据都是一种多粒度的形式,例如知识图谱中的实体和实体子图, 对话中的单词和句子。实际上,用户偏好也体现在多粒度的方式上:细粒度的语义单元反映了一些特定的用户偏好(例如特定的演员实体),而粗粒度的语义单元反映了一些更泛化的偏好(例如一组对喜剧片的评论)。给定对话场景,可以根据用户偏好关联来自不同数据信号的语义单元,一个多粒度的语义对齐来融合不同的语义空间并更好地表征用户偏好是重要的。
二. 方法简介
我们首先对不同类型的上下文数据进行编码。然后为了有效地利用多类型的数据,我们提出了一种由粗粒度到细粒度的对比学习框架,以改进 CRS 的数据语义融合。我们首先从不同的数据信号中提取和表示多粒度语义单元,然后以由粗粒度到细粒度的方式对齐关联的多类型语义单元。为了实现这个框架,我们设计了粗粒度和细粒度的预训练,前者侧重于更一般的、粗粒度的语义融合,后者侧重于更具体的、细粒度的语义融合。这种方法可以扩展到合并更多种类的外部数据。基于学习到的表示,我们构建了推荐模块和对话模块以完成各自任务。我们的模型图如下所示。
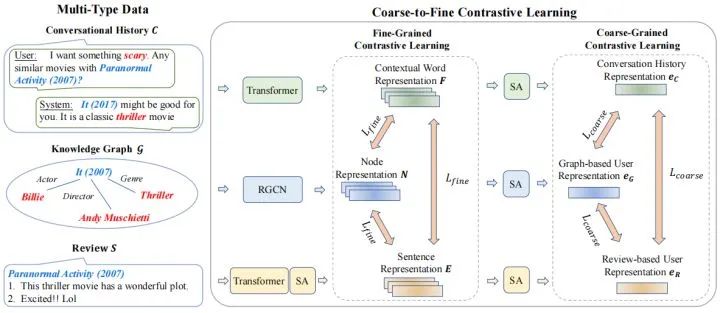
三. 模型简介
3.1. 特征编码
编码对话历史
对话历史
其中用户的细粒度特征编码在单词的上下文词表示
编码知识图谱
知识图谱
我们因此可以获得节点表示矩阵
编码评论
物品的评论文本
3.2. 由粗粒度到细粒度的对比学习
经过上述编码,我们可以获得对话历史、知识图谱和评论文本的相应粗粒度表示、细粒度。这三种上下文数据对应不同的语义空间。接下来,基于多类型上下文数据之间的多粒度相关性,我们提出了一种由粗粒度到细粒度的对比学习方法来融合多类型信息以增强数据表示。
粗粒度对比学习
根据上文,我们获得了对话历史表示
对比学习是一种广泛采用的预训练技术,它通过将语义上接近的表示拉在一起,并将不相关的表示分开来学习表示。来自同一个用户的三个表示
由于相同用户在不同视图下的表示被拉到一起,这个目标对齐了三种类型的上下文数据的语义空间,并且这三种类型的表示相互补充,相互改进。
细粒度对比学习
粗粒度对比学习在整体层面融合了语义空间。然而,细粒度语义单元(例如单词和实体)之间的相应语义关联被忽略了。细粒度上下文数据捕获细粒度的、具体的用户偏好。因此,我们进一步进行细粒度对比学习以更好地融合表示空间。
对于这三种类型的上下文数据,细粒度的偏好被编码在对话历史中一个词的上下文词表示
这样,我们就可以构造语义一致的表示三元组
3.3. Fine-tuning
推荐模块fine-tuning
我们首先生成用户表示。在语义融合之后,实体表示已经从其他类型的上下文数据中学到了有用的信息,我们将其作为物品表示
为了微调用户表示
对话模块和fine-tuning
我们的对话模块是Transformer Decoder架构的,并且构建了多个cross-attention层,以融合预训练的表示:
为了微调该模块以生成更多信息响应,我们设计了一个instance weighting增强的交叉熵损失:
四. 实验
4.1. 数据集
我们使用了ReDial和TGReDial两个数据集。
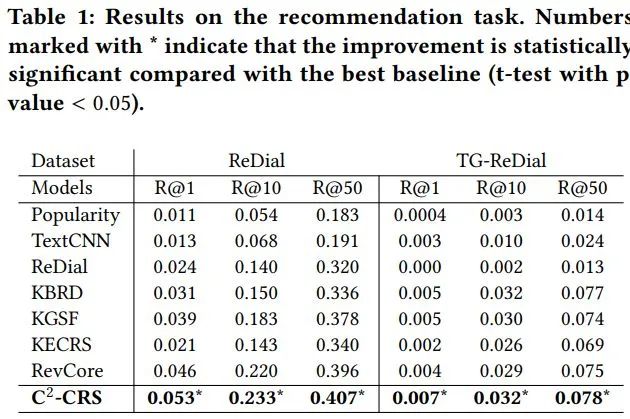
4.2. 推荐任务实验结果
对于推荐任务,我们采用 Recall@
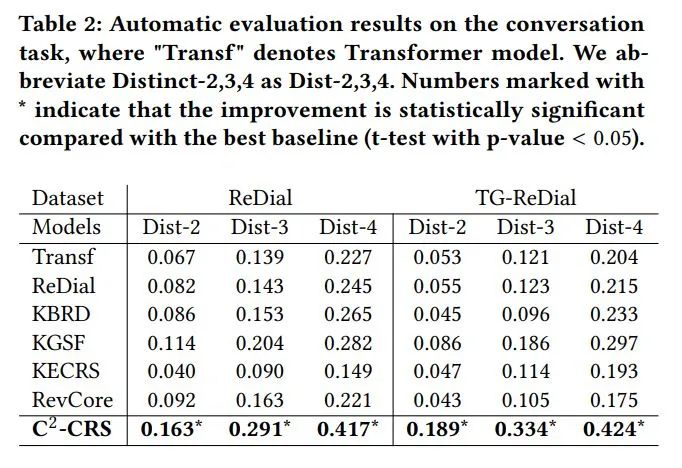
4.3. 对话任务实验结果
对于对话任务,评估包括自动评估和人工评估。自动评估方面,我们使用Distinct
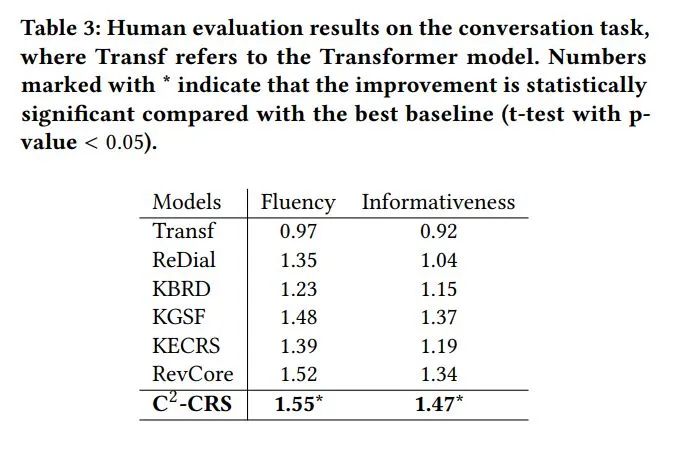
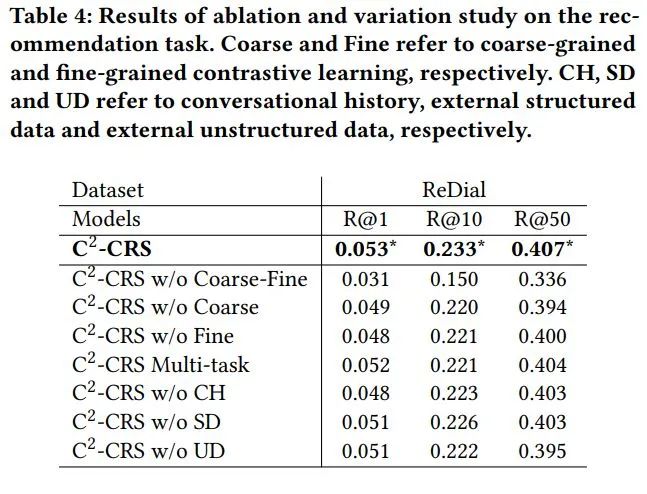
4.4. 消融实验
我们基于模型的不同变体进行了消融实验,以确定各个模块的有效性。首先,我们可以看到去除粗到细对比学习导致最大的性能下降。由于多类型数据存在天然的语义鸿沟,融合底层语义是有效利用信息的关键。其次,直接将所有预训练和微调任务进行多任务学习的性能会变差。主要原因是不同类型的数据很难融合,这就需要更好的语义融合方法。最后,删除任何类型的外部数据都会导致性能下降。它表明各种外部数据在我们增强数据表示的方法中都很有用。
五. 总结
我们为对话推荐系统设计了一种新的基于对比学习的粗粒度到细粒度的预训练方法。通过利用由粗到细的预训练策略,可以有效地融合多类型数据表示,从而进一步增强对话上下文的表示,最终提高CRS的性能。通过构建广泛的实验,我们的方法在推荐和对话任务中的有效性得到了证明。它表明我们的方法可以有效地弥合CRS不同外部数据信号之间的语义差距。
更多推荐

WWW 2022 弯道超车:基于纯MLP架构的序列推荐模型

百篇论文分类整理看数据增广最新研究进展
对比学习在NLP和多模态领域的应用




