From Word Embeddings To Document Distances 阅读笔记
作者:张贵发
研究方向:自然语言处理

本文主要解决文本相似度问题,在word2vec, BOW的基础上提出了WMD模型(Word Mover’s Distance),主要思想是将A文档中的每个词,通过最小距离的转移到B文档中对应的词,最终将每个距离相加,作为衡量两个文档的距离。WMD是无超参数的,而且可解释性高。在一些nlp任务中取得了不错效果。
背景介绍:
解决这类问题的常见思路如下:
-
文档最常用的两种表示方式BOW和TF-IDF。但是,这些特性通常不适合文档距离,因为它们经常接近正交性,它们无法捕捉单词之间的距离。 -
特征分解 如LSI Latent Semantic Indexing通过特征值分解求解词袋矩阵得到语义特征空间 生成模型 -
如LDA,尽可能可能将相似词分组为主题,并将文档表示为这些主题的分布 其他,如mSDA,CCG等 Word2Vec Embedding
WMD是基于word2vec的欧式距离来计算文档的距离的。我们首先要知道什么是word2vec。
-
word2vec是一种词向量 -
Word的相似性来自与周围的word -
可以直接下载已经与训练好的word2vec词向量
一种训练方式是根据当前词,预测周围的词,数学上的表达即使得给定当前词时,周围词的概率最大,目标函数如下:
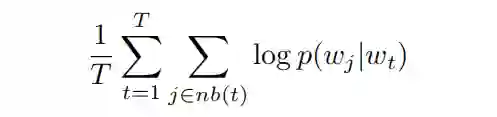
可以捕捉到word之间的距离信息,语义相同的word,映射到向量的空间,也是相近的。看一个简单的例子。1、”king brave man” 2、”queen beautiful woman” 窗口大小为1时,我们有这样的训练数据:
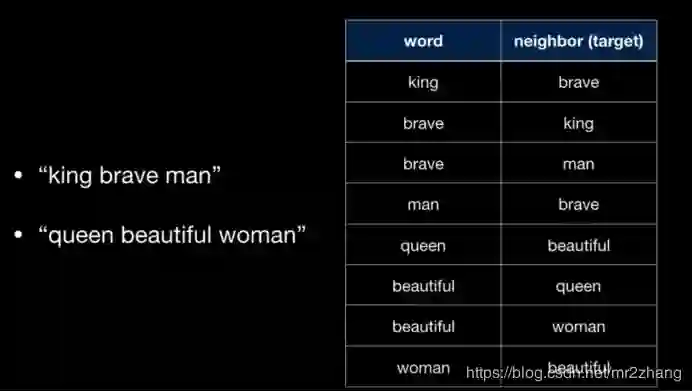
在输入中,周围的单词成为网络的目标,通过训练得到如下结果,语义相相近的词被映射到的区域也是相近的。而且还可以进行简单的语义计算。
WMD
WMD使用了归一化的BOW。给定例子如下:
-
D0: The President greets the press in Chicago -
D1: Obama speaks to the media in lllinois -
D2: The band gave a concert in Japan -
D3: Obama speaks in lllinois
首先需要进行的处理是去除停用词,然后进行bow的归一化如下:[President ,greets, press, Chicago, Obama, speaks media,lllinois, band ,gave, concert Japan]
-
D0: President greets press Chicago [0.25 ,0.25 ,0.25 ,0.25,0,0,...] -
D1: Obama speaks media lllinois [0,..., 0.25 ,0.25 ,0.25 ,0.25 ,0,0,...] -
D2:band gave concert Japan [0,..., 0.25 ,0.25 ,0.25 ,0.25] -
D3: Obama speaks lllinois [0,..., 0.33 ,0.33 ,0.33,0 ,0,...,0]
我们不需要零值,进行去除。
-
D0: President greets press Chicago [0.25 ,0.25 ,0.25 ,0.25] -
D1:Obama speaks media lllinois [0.25 ,0.25 ,0.25 ,0.25] -
D2:band gave concert Japan [ 0.25 ,0.25 ,0.25 ,0.25] -
D3: Obama speaks lllinois[0.33 ,0.33 ,0.33,0]
我们寻找每个词对应最相近的词作为该词的距离。如Obama最相近的是President,那么我们将计算他们之间的距离作为这对pair的距离。依次寻找到所有词对应的相近词距离,最终相加作为最终结果。
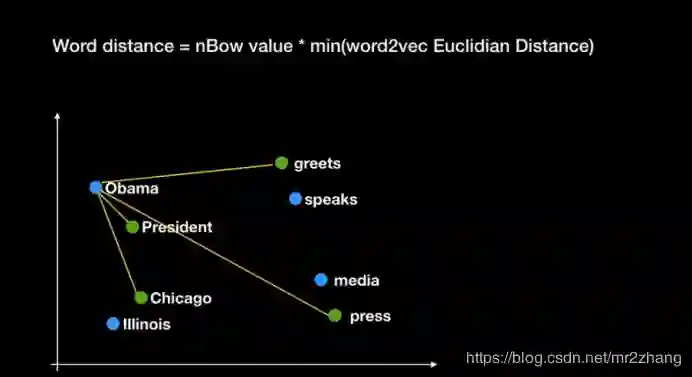
对于长度不同的例子时,会出现交叉项,如: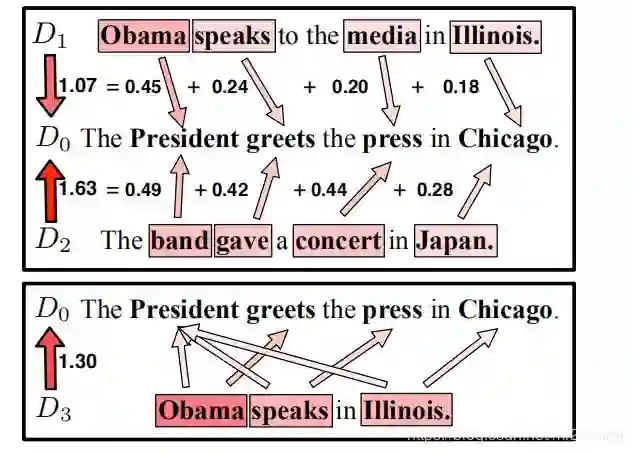

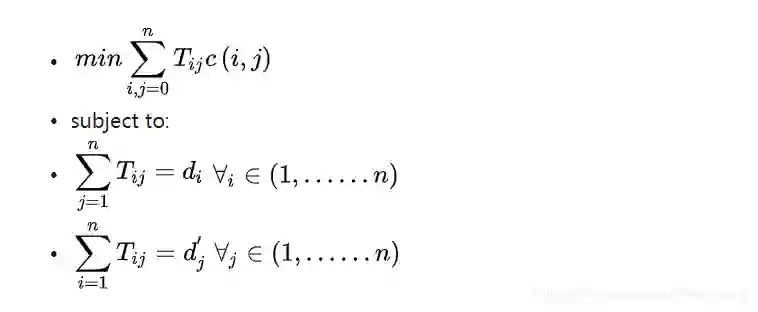
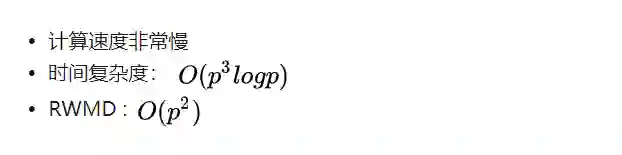
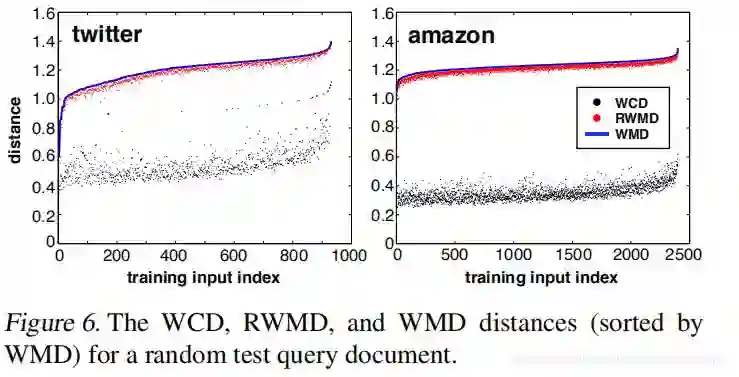
计算两个文档之间的 WMD 距离相当于求解一个大型的线性规划问题,要是用它来做 kNN 就比较耗时了。文章接下来便考虑了 WMD 两个计算比较方便的下界,方便在kNN 的时候做加速,如果当前待检查文档跟中心 query 文档的 WMD 下界已经大到可以确定它不在 ,query 文档的kNN 列表里,那就直接扔掉而不用再花时间求当前文档的 WMD 距离了。
Word Centroid Distance(WCD):
根据三角不等式,文档d和d′之间的质心距离
为其WMD距离的下界(lower bound),WCD算法的复杂度为
,WMD用WCD的计算来作为下界。
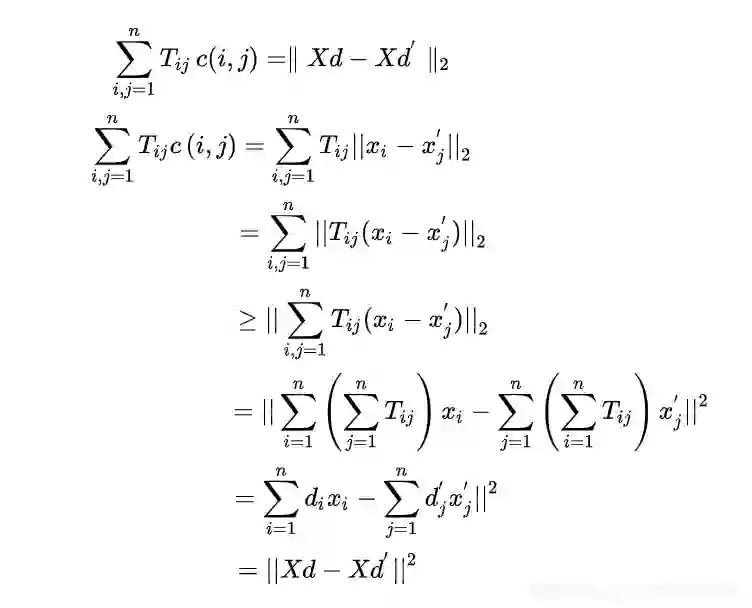
Relaxed word moving distance (RWMD)
RWMD即去掉了WMD中的一个约束条件,只留下一个约束条件。目标变成如下: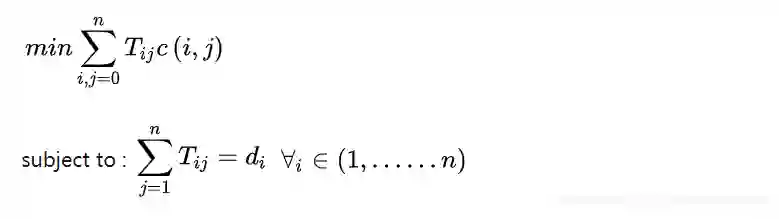
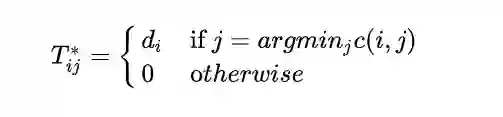
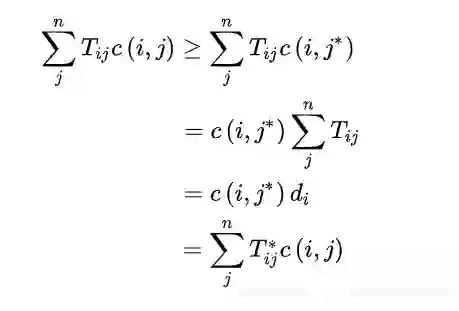
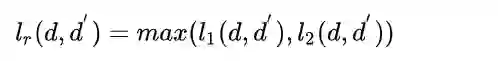
预取和裁剪
最后是如何利用这两个下界做所谓的 prefetch and prune 来为kNN 加速:给定 query 文档\mathbf{d}后,
-
用 WCD 取离它最近的m个文档; -
计算前k个文档的 WMD; -
计算剩下文档的 RWMD,如果某个文档的 RWMD 大于 k-NN 列表中第k个文档的 WMD 就扔掉,不然就计算它的 WMD。如果发现在 k-NN 列表中就更新 k-NN 列表,不然也扔掉。
实验:
实验主要比较7种文档表示baseline:,BOW、TFIDF、BM25 Okapi、LSI、LDA、mSDA、CCG 在不同数据上的错误率。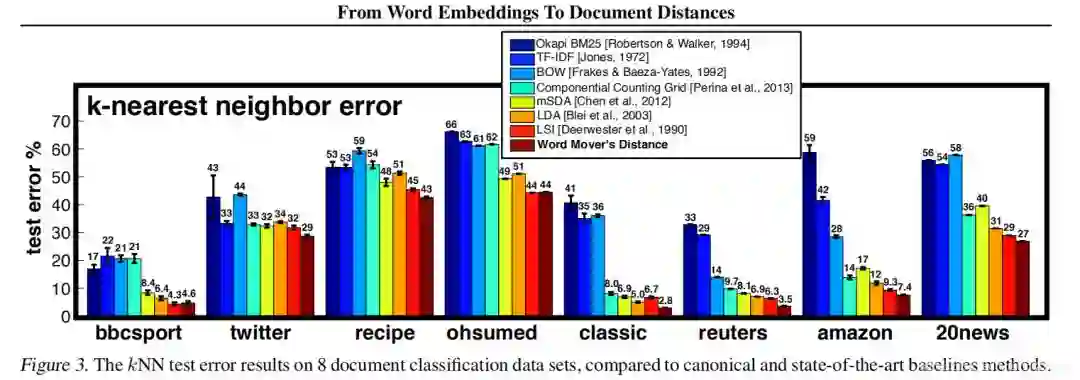
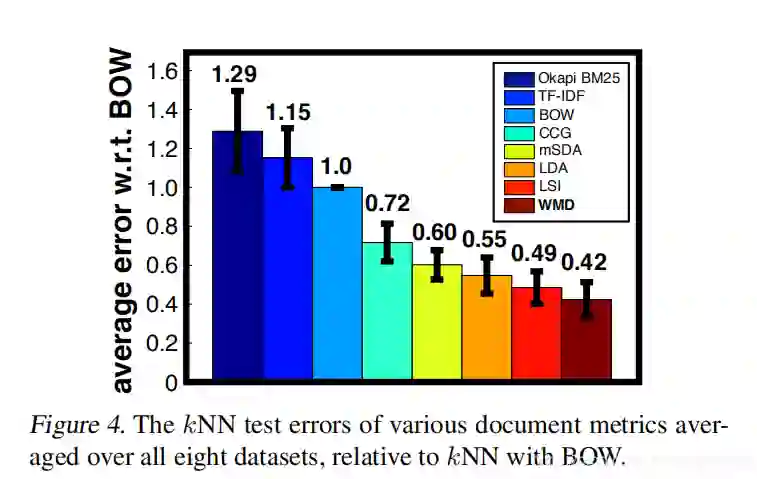
总结与展望:
WMD在文档的相似度计算中确实取得了一定进展,具有如下优点:
-
效果出色:充分利用了word2vec的领域迁移能力 -
无监督:不依赖标注数据,没有冷启动问题 -
模型简单:仅需要词向量的结果作为输入,没有任何超参数 -
可解释性:将问题转化成线性规划,有全局最优解 -
灵活性:可以人为干预词的重要性
缺点:
-
BOW,没有保留语序信息 -
不能很好的处理词向量的OOV(Out of vocabulary)问题 -
处理否定词能力偏差 -
处理领域同义词互斥词的能力偏差
在WMD中,向量d的每一位代表词在文本中的词频进行归一化,因此在排除出现次数的影响因素的情况下,不同词对于文本的贡献是一样的。但实际上在一条文本中,不同词的重要性是不一样的,因此我们可以尝试使用tf-idf与bm25进行进一步优化。
5. 参考文献
WMD: http://proceedings.mlr.press/v37/kusnerb15.pdf ↩ 理解WMD算法:https://supernan1994.github.io/nlp/wmd1.html 文本相似度度量:https://zhuanlan.zhihu.com/p/76958536 https://www.zhihu.com/question/33952003
本文由作者授权AINLP原创发布于公众号平台,欢迎投稿,AI、NLP均可。原文链接,点击"阅读原文"直达:
https://blog.csdn.net/mr2zhang/article/details/104874561
推荐阅读
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
抛开模型,探究文本自动摘要的本质——ACL2019 论文佳作研读系列
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




