Word Embedding 词嵌入最新综述论文(附全文下载)
【导读】这是一份关于词嵌入表示的近期动态介绍。该方法旨在将词汇列表转变成一组固定长度的分布式表示,这种方法通常被称作word embedding,它可以很好的对语义信息进行编码,并为很多下游任务提供了非常有用的应用基础。
介绍:
对词汇以及文章进行表示,是自然语言处理任务中的大部分工作。通常需要针对一组目标词找到一组对应向量来表示其中蕴含的信息,这是一个非常有实用价值的工作(例如,addition,subtraction,距离度量等)并且使得非结构化的文本可以被用于很多机器学习的算法中。
这一领域的发展得益于大量研究人员的辛勤工作。一方面,1975年Salton提出了向量空间模型(Vector Space Model,VSM),并在当时的信息检索领域的到了成功应用;另一方面,语言模型的研究得到了质的突破,这一模型主要关注于给定一些词汇序列,预测下一个词汇的任务,这种简单的想法在很多任务中为证明十分有效(如语音识别等)。
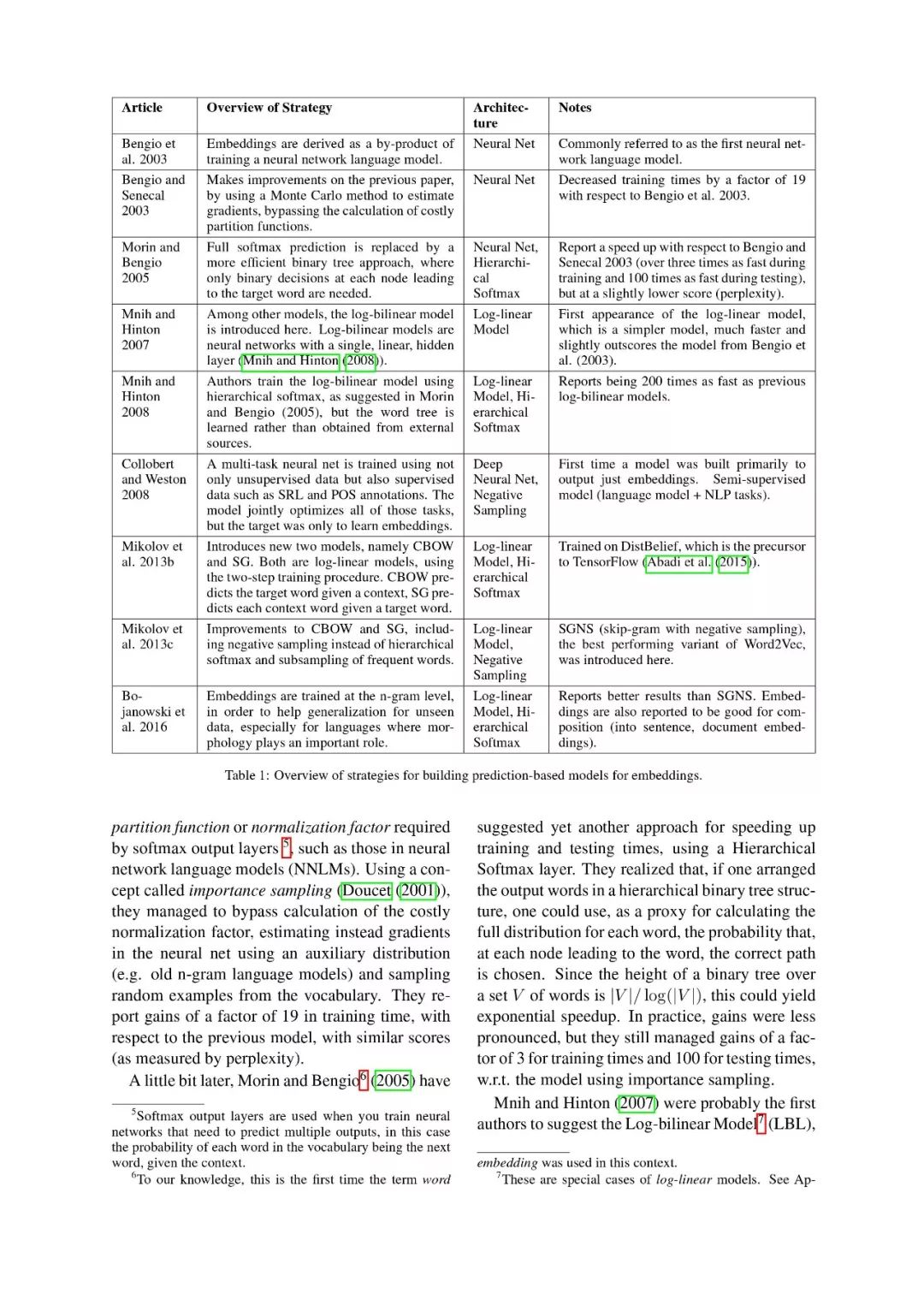
在上述两个独立领域的研究基础上,在2003年,由Bengio开发出了第一个基于神经网络的大规模语言模型。其主要思想是将这一问题调整为无监督学习问题,关键点是将非结构化的文本映射到特征空间中,来实现语言信息的低维表示。
目前,很多词嵌入表示模型已经不仅限于神经网络方法以及特征层信息,而是采用word-context matrices来得到向量表示,例如2014年提出的GloVe模型等。
词嵌入模型起源于神经网络语言模型,也被成为基于预测的模型;其他的那些基于矩阵的模型目前被称为基于频率的模型,这是因为在这类方法中,需要考虑全局的word-context共现次数,来生成embedding表示。
原文链接:
https://arxiv.org/pdf/1901.09069.pdf
【论文完整版下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“WEAS”就可以获取《词嵌入表示最新综述》论文完整版的下载链接~
专知2019年《深度学习:算法到实战》精品课程,欢迎扫码报名学习!

附PDF全文:









-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!460+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!
请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程

