论文浅尝 | 基于RNN与相似矩阵CNN的知识库问答

链接:https://arxiv.org/pdf/1804.03317.pdf
概述
当前大部分的 kbqa 方法为将 kb facts 与 question 映射到同一个向量空间上,然后计算相似性. 但是这样的做法会忽视掉两者间原本存在的单词级别的联系与交互. 所以本文提出一种网络结构 ARSMCNN,既利用到语义的信息, 又利用到单词级别的交互.
模型
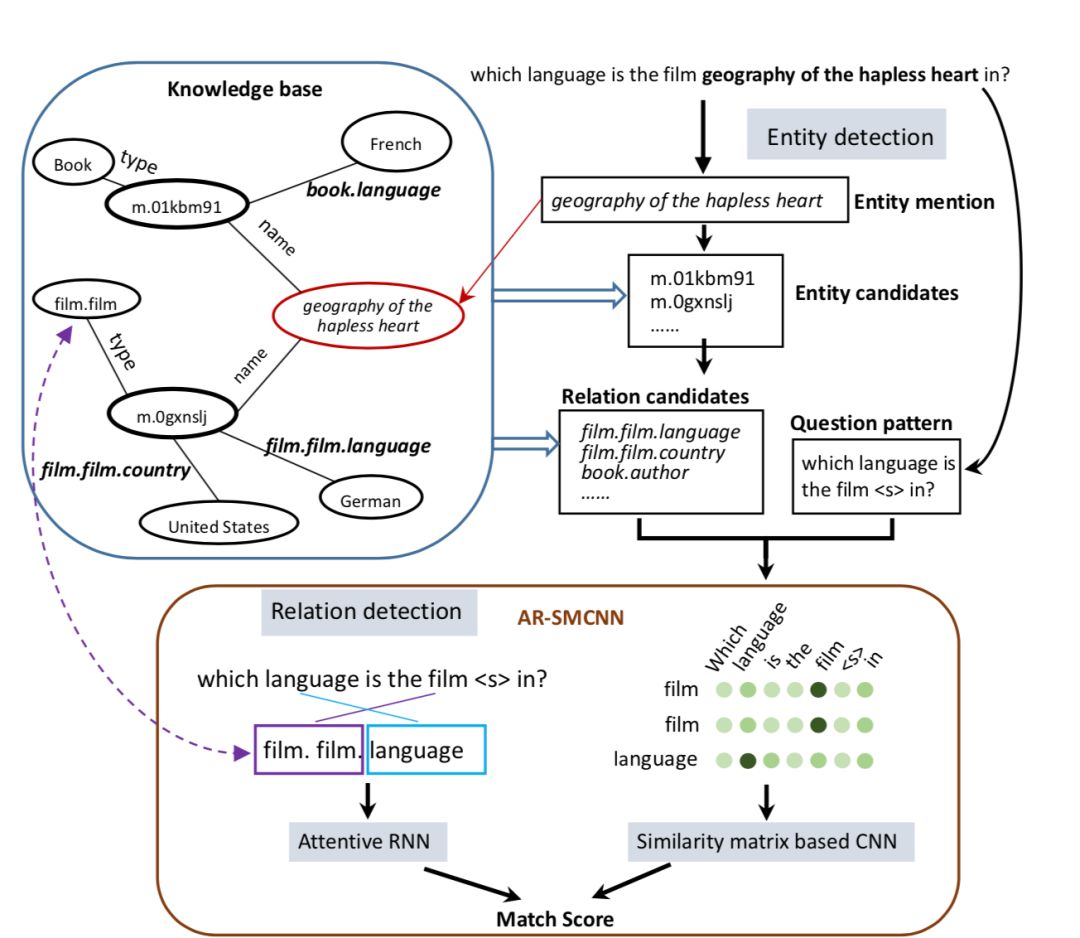
作者提出一种称为 attentive recurrent neural network with similarity matrix based convolutional neural network 网络结构,同时运用 attentive rnn 以及 cnn 来得到 question 与 kb facts 之间的相似度从而给出匹配得分. 上图为完整的流程示意图.
首先假设⼀个三元组(subject, relation, object)为⼀个 fact, 并且当 subject 与 relation 确定后,答案也会被确定下来.从而可以将问答任务分为两个阶段: entity detection 与 relation detection.
1) Entity Detection
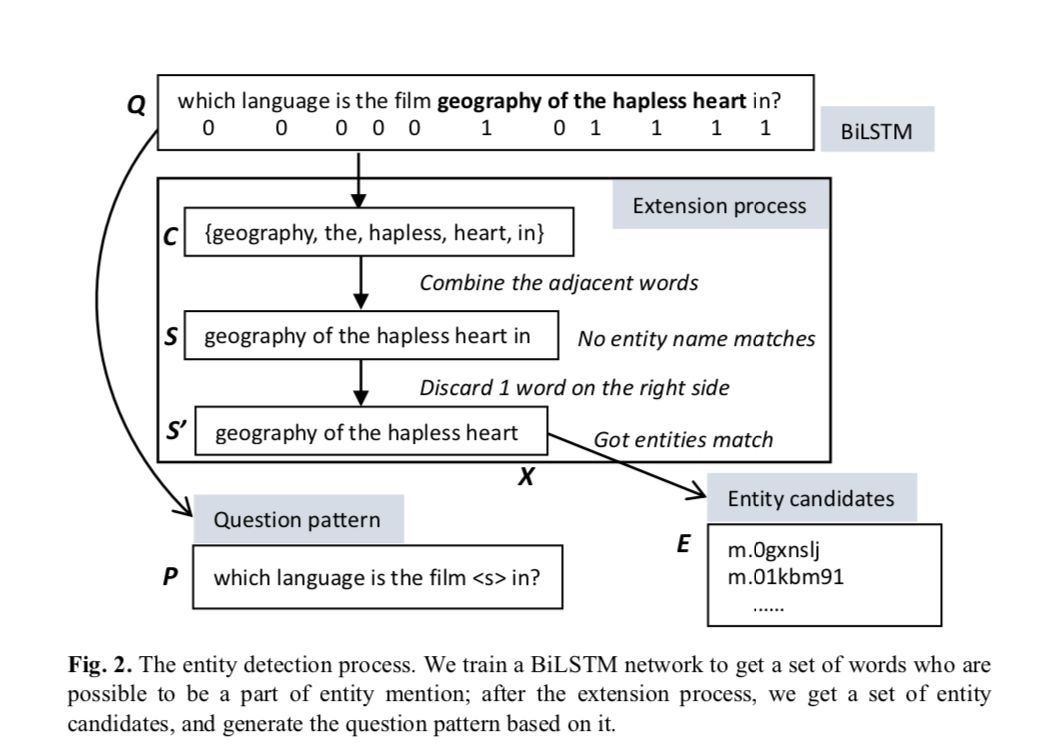
⾸先利用 bilstm 训练模型,输入一个问句,如果是关键词则标记为 1,否则标记为 0. 然后将标记为1的词拿出来进行 entity dectction. 作者提出了一种选取 entity candidates 的方法, 大致分为四个步骤:
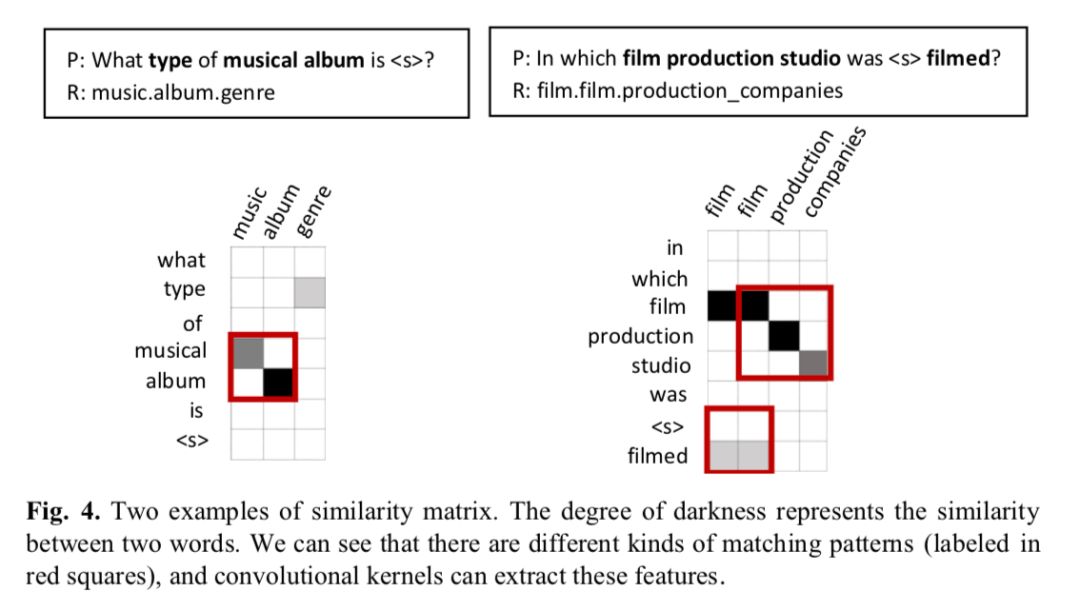
a) 将标记为 1 且距离小于等于 1 的单词拼接成一个句子 s,如果有多个,则取长度最长的那一个.
b) 在知识库中寻找能够完美匹配的实体, 如果找到,则返回实体集合,如果没有则进行下一步.
c) 基于在 s 中最有可能存在 entity mention 的假设, 可以通过 s 生成知识库中的对应实体 x. 所以, 以 s 为中心通过expand或者 narrow 最多两个单词来构成s’,然后利用s’取寻找 entity. 如果找到了则返回实体集合,否则进行下一步
d) 如果仍然没有找到 match, 则利用 S 中的每个单词来寻找包含该单词的实体. 保证两者有最大公共子串.
经过实验作者发现进入到第四步的概率仅为 0.2%
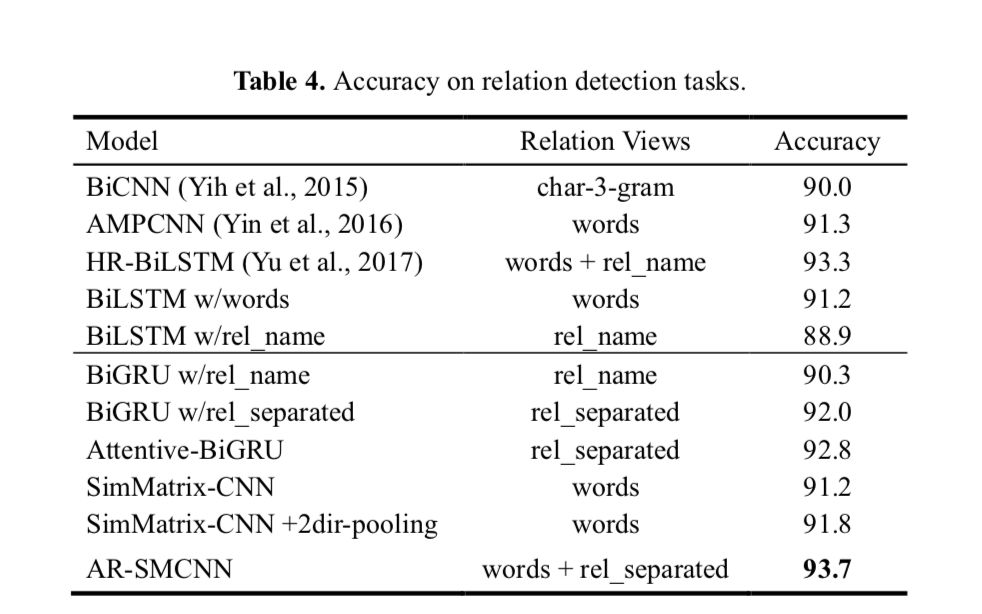
2) Relation Detection
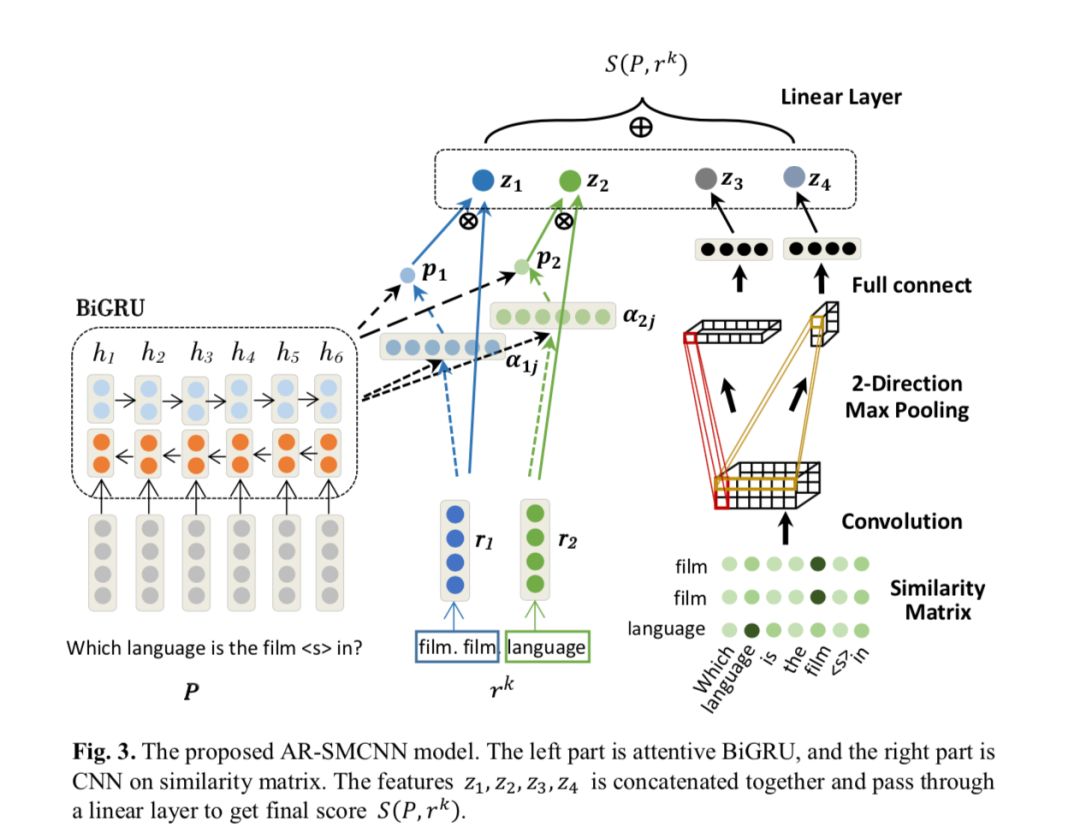
首先将问句中的实体用<s>替换, 然后进过两个部分进行match score的计算.
a) semantic level:
利用 attentive rnn 作为 encoder compare 的框架, 将 question 作为输入到 bigru中,并于 relation 做一个 attention:
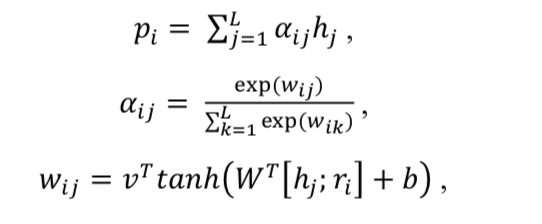
然后利用 p 和 r 计算 match score:
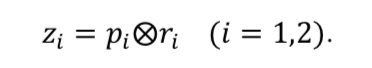
b) literal level:
将单词映射到 embedding 空间后,先计算相似矩阵:
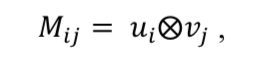
随后对这个相似矩阵进行卷积运算:
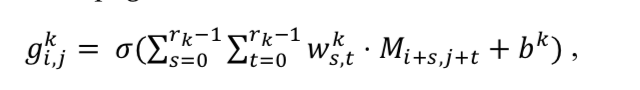
然后在两个方向上做最大池化
(其中的d1,d2分别为问句和 relation 的长度)
最后再经过一个全联接层得到literal层面上的 match socre:
c) 将两个层面的得分综合起来作为最后的match socre:
训练过程中使用 margin ranking loss, 保证正确的relation与问句的匹配得分比负例要高:
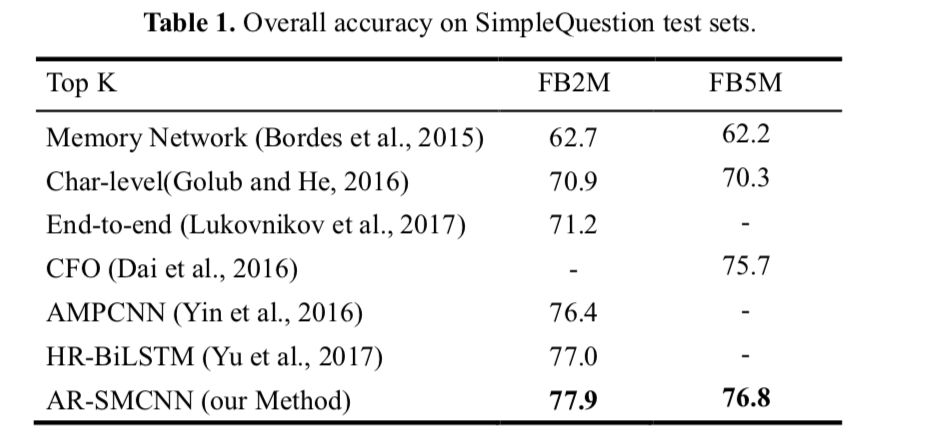
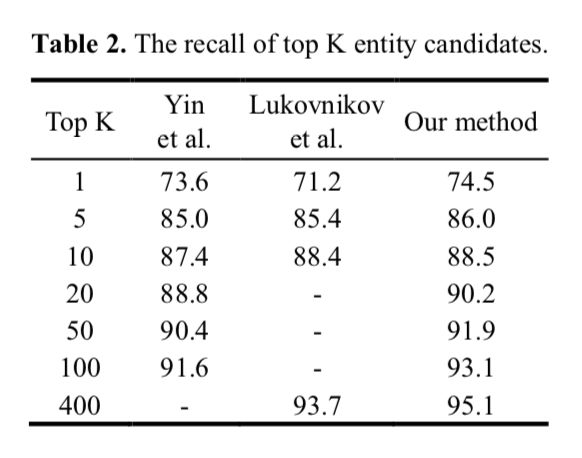
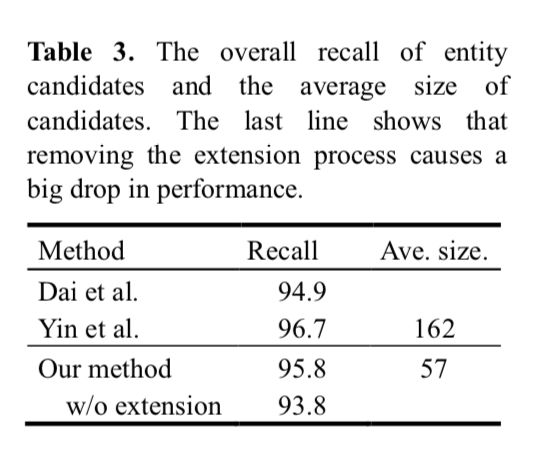
实验结果:
在simple question上做实验:
笔记整理: 陈佳奥,浙江大学本科生, 研究方向为 KB-QA, NLP。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。


