
作者 | 财神Childe
转载自CSDN博客
文章目录
NLP
Word Embedding
RNN/LSTM/GRU
seq2seq
Contextual Word Embedding
transformer:
bert
NLP
NLP:自然语言处理(NLP)是信息时代最重要的技术之一。理解复杂的语言也是人工智能的重要组成部分。而自google在2018年10月底公布BERT在11项nlp任务中的卓越表后,BERT(Bidirectional Encoder Representation from Transformers)就成为NLP一枝独秀,本文将为大家层层剖析bert。
NLP常见的任务主要有: 中文自动分词、句法分析、自动摘要、问答系统、文本分类、指代消解、情感分析等。
我们会从one-hot、word embedding、rnn、seq2seq、transformer一步步逼近bert,这些是我们理解bert的基础。
Word Embedding
首先我们需要对文本进行编码,使之成为计算机可以读懂的语言,在编码时,我们期望句子之间保持词语间的相似行,词的向量表示是进行机器学习和深度学习的基础。
word embedding的一个基本思路就是,我们把一个词映射到语义空间的一个点,把一个词映射到低维的稠密空间,这样的映射使得语义上比较相似的词,他在语义空间的距离也比较近,如果两个词的关系不是很接近,那么在语义空间中向量也会比较远。
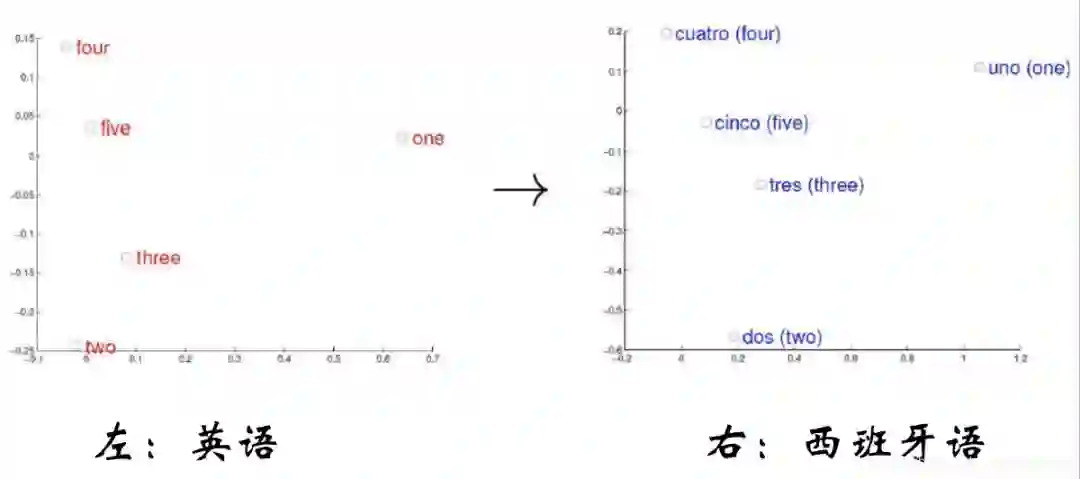
如上图英语和西班牙语映射到语义空间,语义相同的数字他们在语义空间分布的位置是相同的
在句子的空间结构上我们期望获取更底层的之间的关系比如:
VKing - VQueen = VMan-VWomen
VParis - VFrance = VBerlin -VGerman
king和queen之间的关系相比与man与woman的关系大体应该相同的,那么他们通过矩阵运算,维持住这种关系;
Paris 和France之间的关系相比与Berlin与German的关系大体应该相同的,那么他们通过矩阵运算,维持住这种关系。
简单回顾一下word embedding,对于nlp来说,我们输入的是一个个离散的符号,对于神经网络来说,它处理的都是向量或者矩阵。所以第一步,我们需要把一个词编码成向量。最简单的就是one-hot的表示方法。如下图所示:
one-hot encoding编码

通常我们有很多的词,那只在出现的位置显示会,那么势必会存在一些问题
高维的表示
稀疏性
正交性(任意两个词的距离都是1,除了自己和自己,这样就带来一个问题,猫和狗距离是1,猫和石头距离也是1,但我们理解上猫和狗距离应该更近一些)
两个词语义上无法正确表示,我们更希望低维的相似的比较接近,语义相近的词距离比较近,语义不想近的词,距离也比较远。
解决的办法就是word enbedding,是一种维位稠密的表示。
Neural Network Language Model(神经网络语言模型)
我们都知道word2vec,glove。其实更早之前的神经网络语言模型里出现。已经有比较早的一个词向量了。语言模型是nlp的一个基本任务,是给定一个句子w,包括k个词,我们需要计算这个句子的概率。使用分解成条件概率乘积的形式。变成条件概率的计算。
传统的方法,统计的n-gram的,词频统计的形式,出现的多,概率就高,出现少概率就低,。
不能常时依赖上下文,如:他出生在法国,他可以讲一口流利的(__),我们希望法语的概率比英语、汉语的概率要高。n-gram记住只能前面有限几个词,若参数比较多,它根本学不到这复杂关系,这是传统语言模型比较大的一个问题。这个可以通过后面的rnn、lstm解决,我们这里先不讨论。
第二个问题就是泛化能力的问题,泛化能力,或者说不能共享上下文的信息,我要去(__)玩, 北京、上海应该是一样的,因为都是中国的一个城市,概率应该相等或相近的,但是因为预料中北京很多,所以出现上海的概率很低。那神经网络语言模型就可以解决这样的问题。
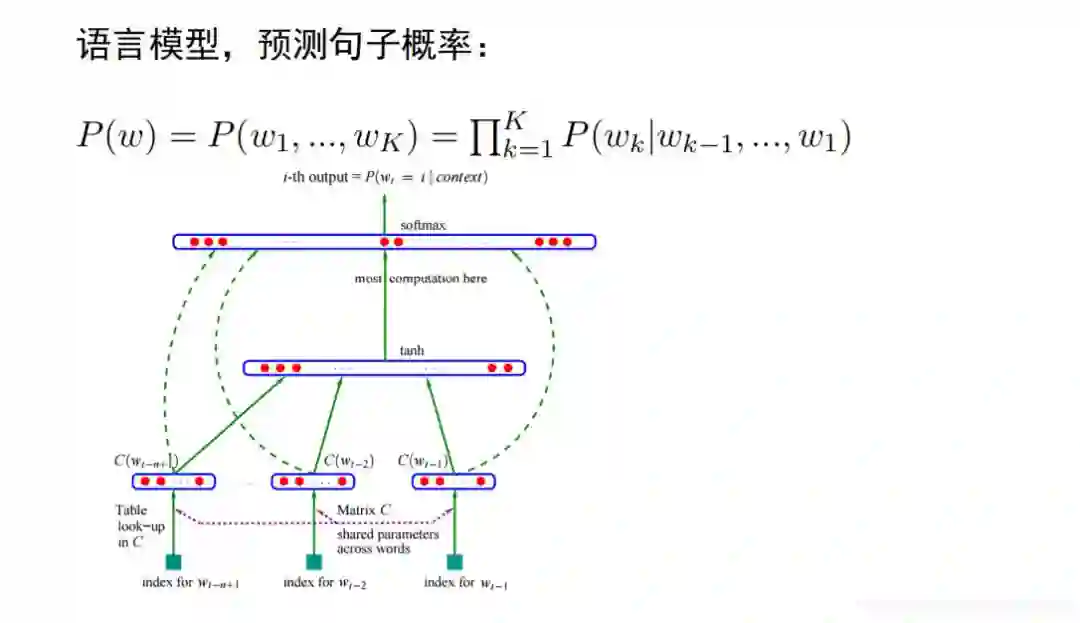
神经网络语言模型架构如上图:
将每个词向量拼接成句子矩阵。每一列都是一个词, 如北京、上海、 天津比较近,大致相同一块区域,所以当预测时,可以给出大概相同的概率,不仅仅与预料中统计结果有关系。矩阵相乘就可以提取出这个词,但是为了提取一个词,我们要进行一次矩阵运算,这个比较低效,所以比较成熟的框架都提供了查表的方法,他的效率更高。
因为上下文环境很相似,会共享类似的context,在问我要去 (__)概率会比较大。这也是神经网络语言模型的一个好处。我们通过神经网络语言模型得到一个词向量。当然我们也可以用其他的任务来做,一样得到词向量,比如句法分析,但是那些任务大部分是有监督的学习,需要大量的标注信息。
语言模型是非监督的,资料获取不需要很大的成本。
word2vec和神经网络语言模型不同,直接来学习这个词向量,使用的基本假设是分布式假设,如果两个词的上下文时相似的,那么他们语义也是相似的。
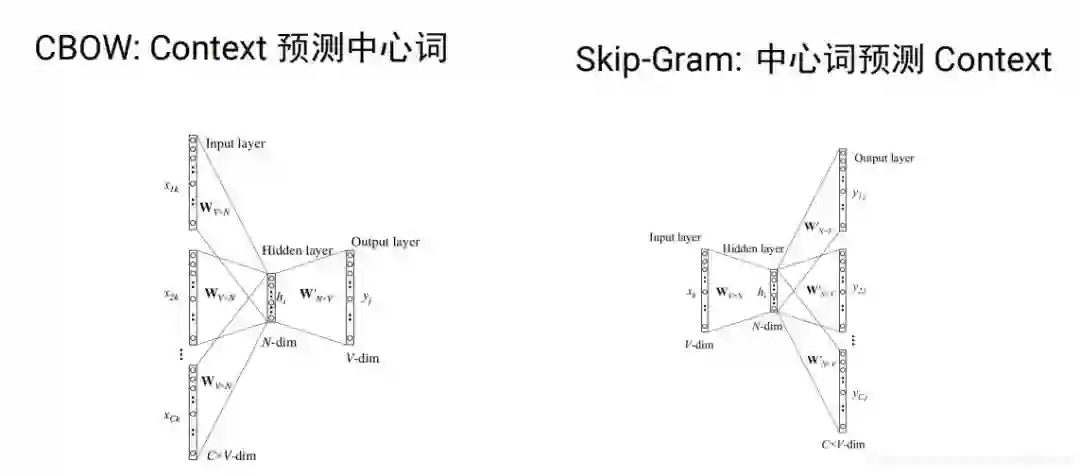
word2vec分为cbow(根据context预测中心词)和skip-gram(根据中心词预测context)两种。
我们可以通过word2vec或者 glove这种模型在大量的未标注的语料上学习,我们可以学习到比较好的向量表示,可以学习到词语之间的一些关系。比如男性和女性的关系距离,时态的关系,学到这种关系之后我们就可以把它作为特征用于后续的任务,从而提高模型的泛化能力。
但是同时存在一些问题比如:
He deposited his money in this bank .
His soldiers were arrayed along the river bank .
word embeding 有个问题就是我们的词通常有很多语义的,比如bank是银行还是河岸,具体的意思要取决与上下文,如果我们强行用一个向量来表示语义的话,只能把这两种语义都编码在这个向量里,但实际一个句子中,一个词只有一个语义,那么这种编码是有问题的。
RNN/LSTM/GRU
那么这种上下文的语义可以通过RNN/LSTM/GRU来解决,RNN与普通深度学习不同的是,RNN是一种序列的模型,会有一定的记忆单元,能够记住之前的历史信息,从而可以建模这种上下文相关的一些语义。RNN中的记忆单元可以记住当前词之前的信息。
RR可以解决,理论上我们希望学到很长的关系,但是由于梯度消失的问题,所以长时依赖不能很好的训练。
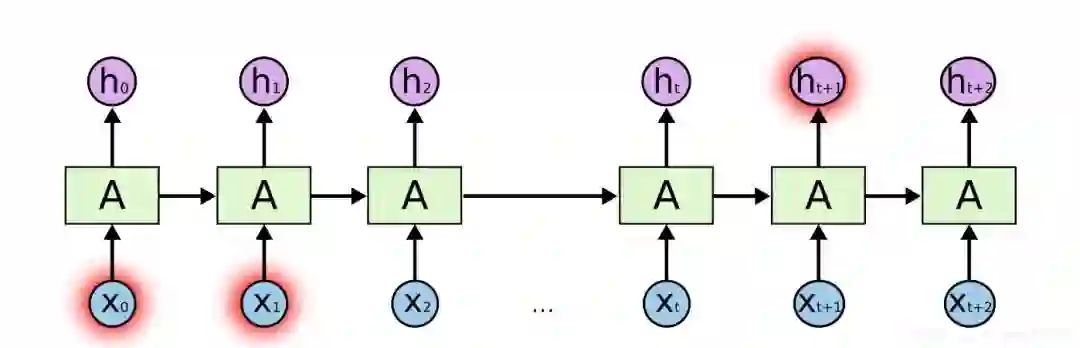
其实lstm可以解决RNN长时依赖梯度消失的问题。
seq2seq
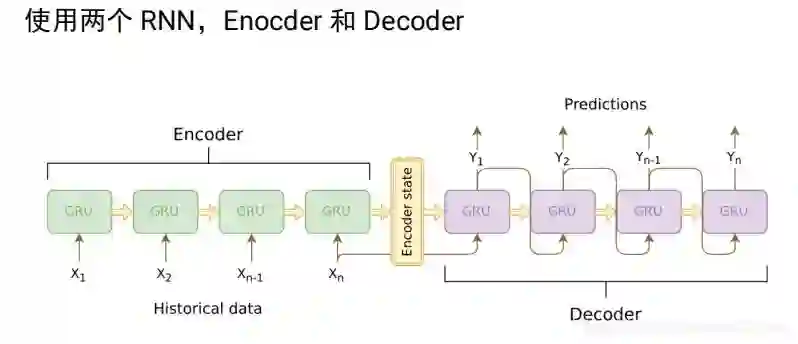
对于翻译,我们不可能要求英语第一个词一定对应法语的第一个词,不能要求长度一样,对于这样一个rnn不能解决这一问题。我们使用两个rnn拼接成seq2seq来解决。
我们可以用两段RNN组成seq2seq模型
从而可以来做翻译,摘要、问答和对话系统。
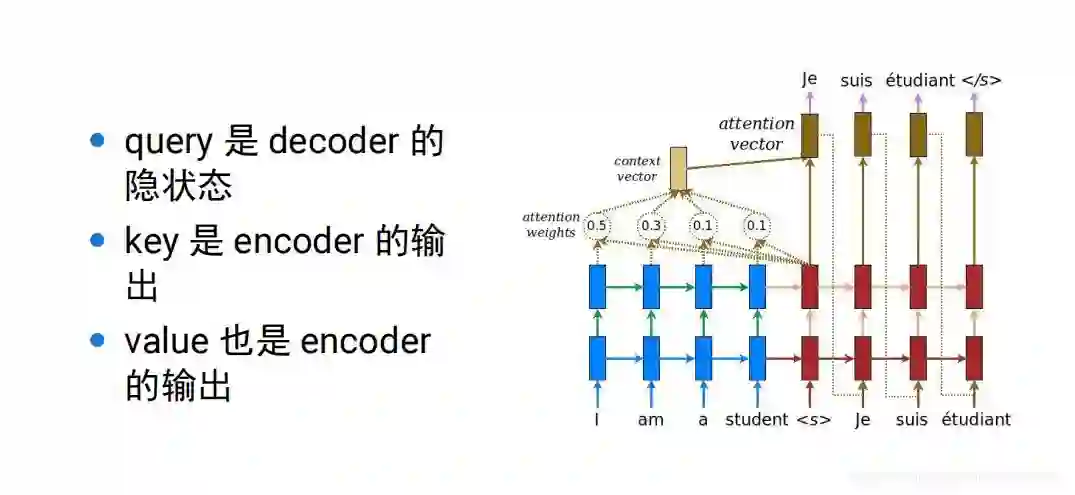
比如经典的翻译例子法语到英语的翻译,由encoder编码到语义空间和decoder根据语义空间解码翻译成一个个的英语句子。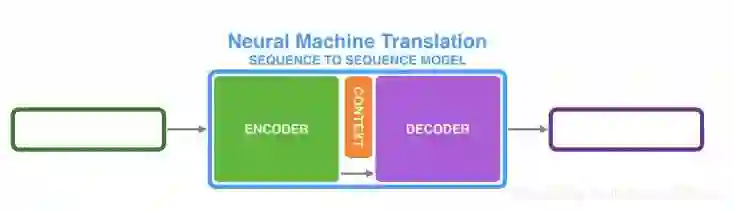
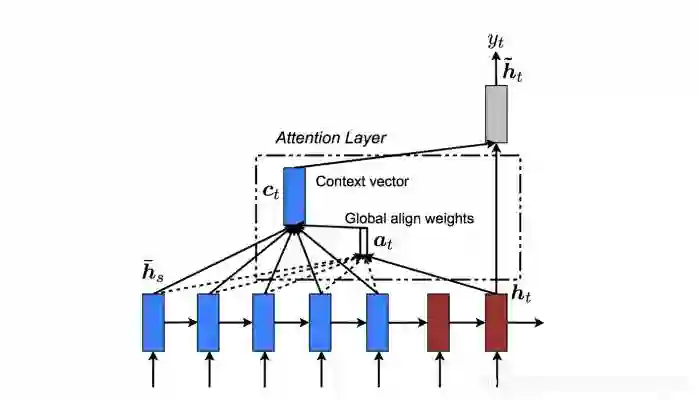
pay attention 做内积。越大越相近 约重要,后续的attention、transformer都是对seq2seq的一个改进,通过这种可以解决word embbeing没有上下文的一个问题。
加上attention机制,我们就取得了很大的成绩,但是仍然存在一个问题,
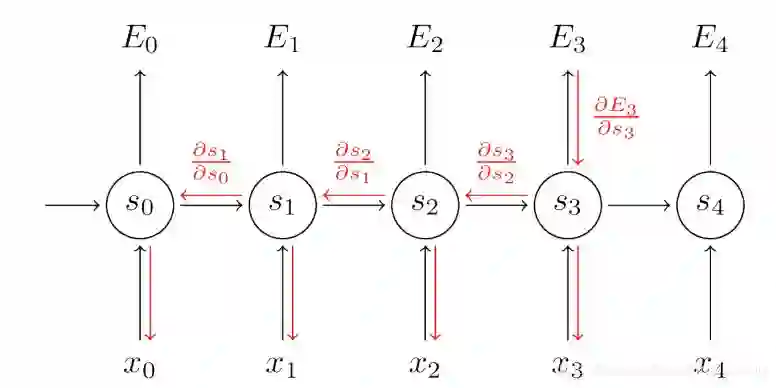
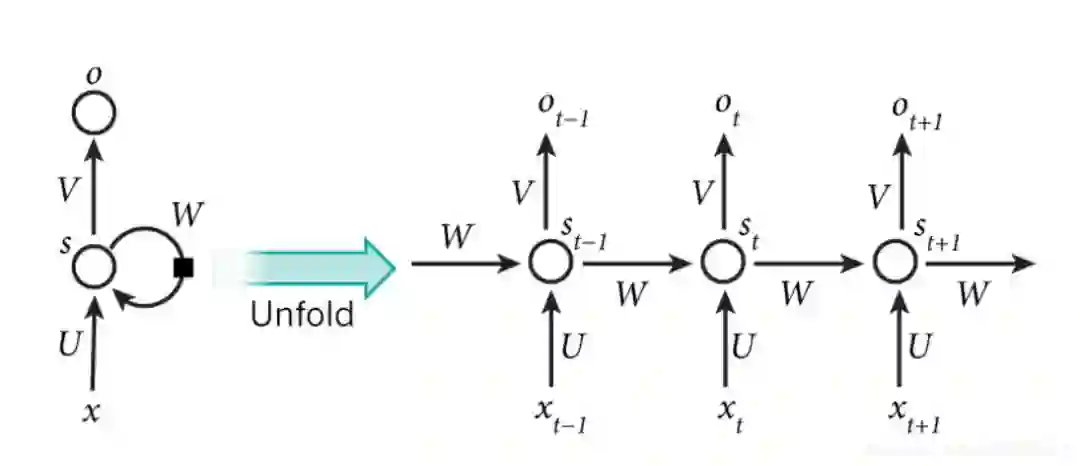
顺序依赖,如下图:t依赖t-1,t-1依赖t-2,串行的,很难并行的计算,持续的依赖的关系,通常很慢,无法并行:
The animal didn’t cross the street because it was too tired.
The animal didn’t cross the street because it was too narrow.
存在单向信息流的问题,只看前文,我们很难猜测it指代的具体内容,编码的时候我们要看整个句子的上下文,只看前面或者只看后面是不行的。
RNN的两个问题:1、顺序依赖,t依赖t-1时刻。
2、单向信息流(如例子中指代信息,不能确定)
3、需要一些比较多的监督数据,对于数据获取成本很高的任务,就比较困难,在实际中很难学到复杂的上下文关系
Contextual Word Embedding
要解决RNN的问题,就引入了contextual word embedding。
contextual word embedding:无监督的上下文的表示,这种无监督的学习是考虑上下文的,比如ELMo、OpenAI GPT、BERT都是上下文相关的词的表示方法。
attention是需要两个句子的,我们很多时候只有一个句子,这就需要self-attention。提取信息的时候、编码时self-atenntion是自驱动的,self-attention关注的词的前后整个上下文。

transformer:
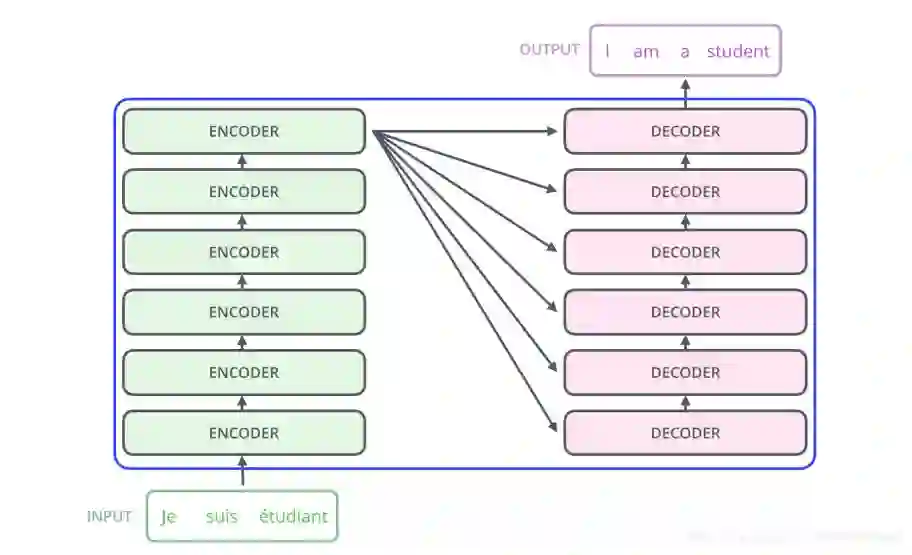
本质也是一个encoder与decoder的过程,最起初时6个encoder与6个decoder堆叠起来,如果是LSTM的话,通常很难训练的很深,不能很好的并行
每一层结构都是相同的,我们拿出一层进行解析,每一层有self-attention和feed-forward,decoder还有普通的attention输入来自encoder,和seq-2seq一样,我在翻译某一个词的时候会考虑到encoder的输出,来做一个普通的attention

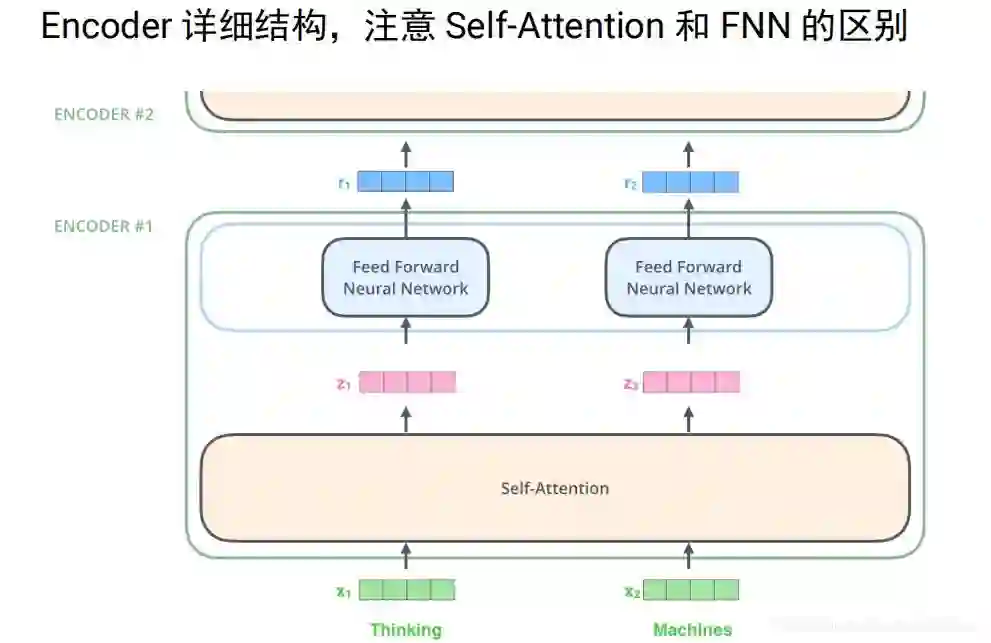
如下图例子给定两个词 thinking和machies,首先通过word embedding把它变成向量,通过self-attention,把它变成一个向量,这里的sefl-attention时考虑上下文的。然后再接全连接层,计算z1的时候我要依赖x1 、x2 、x3整个序列的,才能算z1,z2也一样,我算r1的时候时不需要z2的,只要有z1我就可以算r1.只要有z2就能算r2,这个是比较大的一个区别,这样就可以并行计算。
我们来看看self-attention具体是怎么计算的
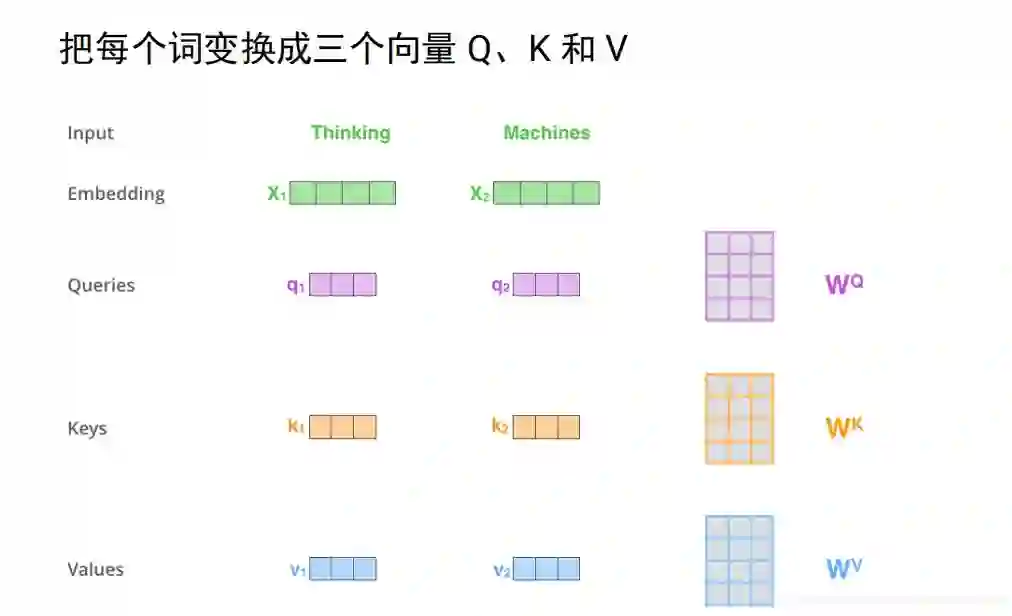
假设只有两个词,映射成长度只有四的向量,接下来使用三个变换矩阵wq wk wv,分别把每个向量变换成三个向量 q1 k1 v1 q2 k2 v2这里是与设映的向量相乘得到的
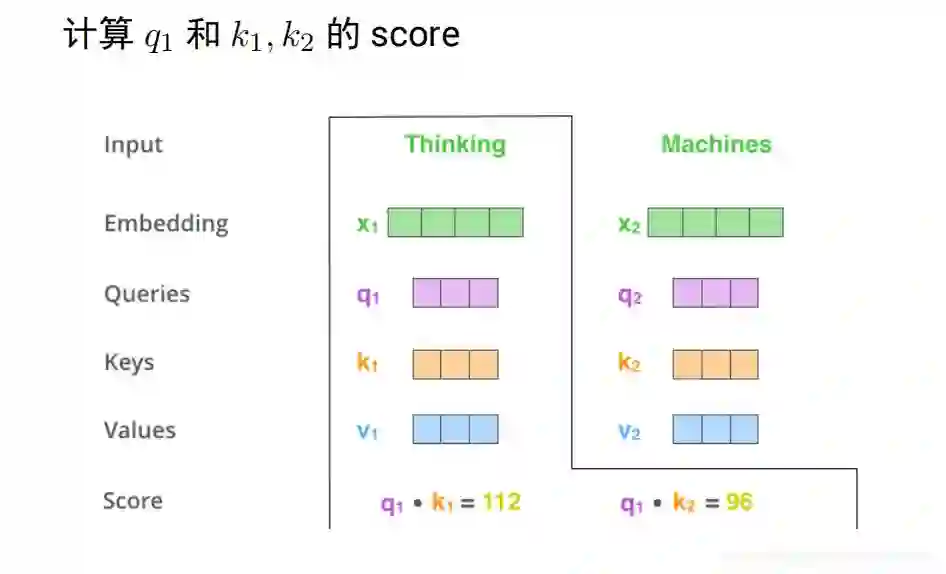
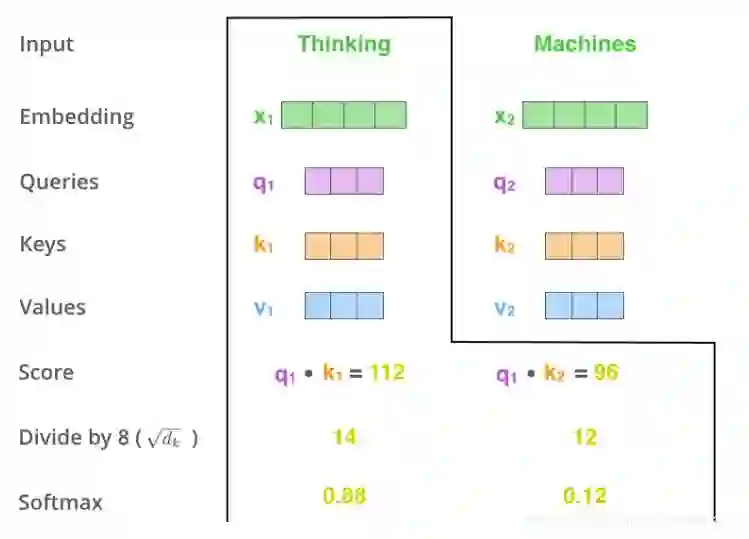
得到向量之后就可以进行编码了,考虑上下文,如上文提到的bank同时有多个语义,编码这个词的时候要考虑到其他的词,具体的计算是q1 k1做内积 q2 k2 做内积得到score,内积越大,表示约相似,softmax进行变成概率。花0.88的概率注意Thinking,0.12注意macheins这个词
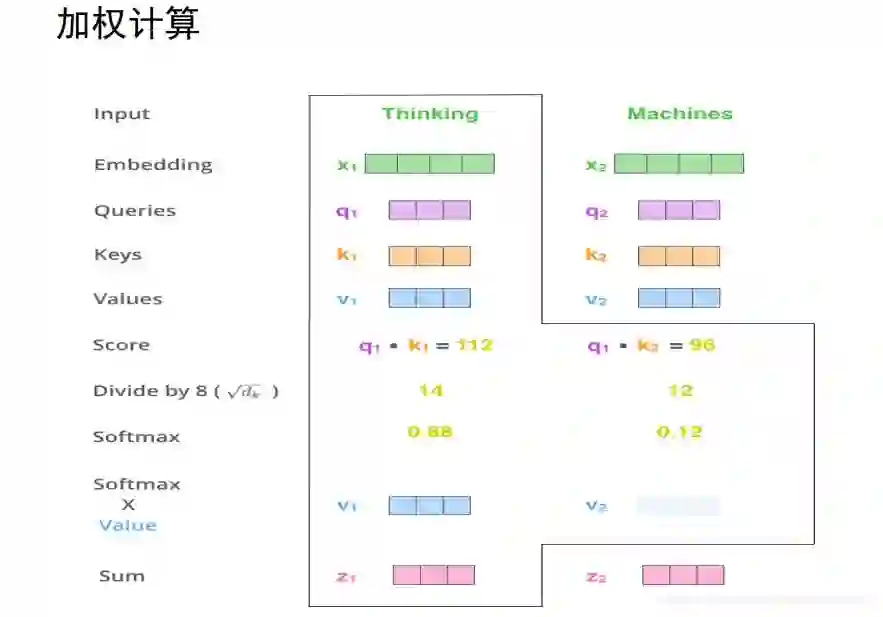
就可以计算z1了,z1=0.88v1+0.12z2
z2的计算也是类似的。
q表示为了编码自己去查询其他的词,k表示被查询,v表示这个词的真正语义,经过变换就变成真正的包含上下文的信息,普通attention可以理解为self-attention的一个特例。
普通attention的对比:
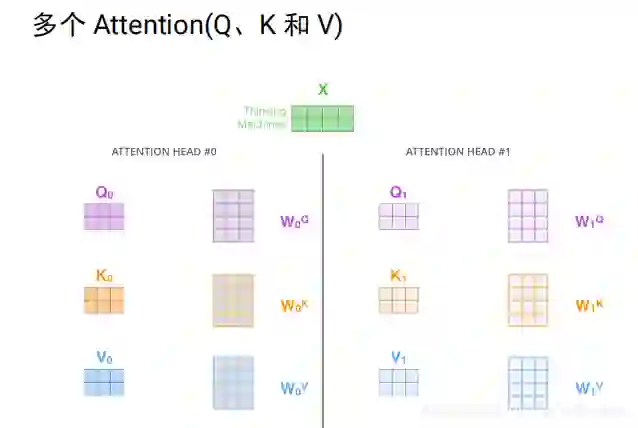
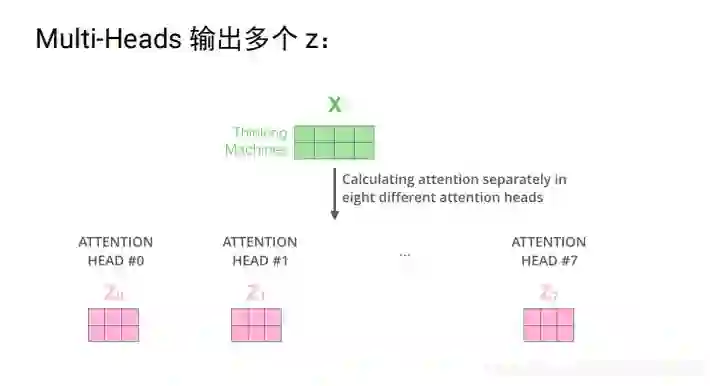
实际中是多个head, 即多个attention(多组qkv),通过训练学习出来的。不同attention关注不同的信息,指代消解 上下位关系,多个head,原始论文中有8个,每个attention得到一个三维的矩阵
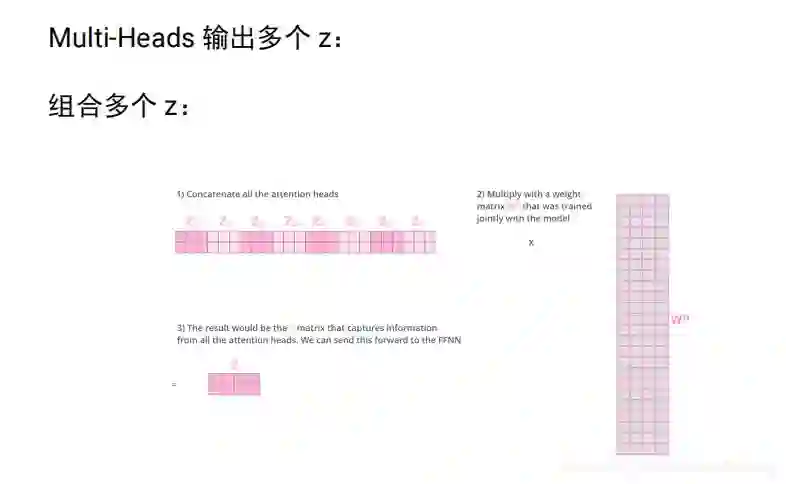
将8个3维的拼成24维,信息太多 经过24 *4进行压缩成4维。
位置编码:
北京 到 上海 的机票
上海 到 北京 的机票
self-attention是不考虑位置关系的,两个句子中北京,初始映射是一样的,由于上下文一样,qkv也是一样的,最终得到的向量也是一样的。这样一个句子中调换位置,其实attention的向量是一样的。实际是不一样的,一个是出发城市,一个是到达城市。
引入位置编码,绝对位置编码,每个位置一个 Embedding,每个位置一个embedding,同样句子,多了个词 就又不一样了,编码就又不一样了
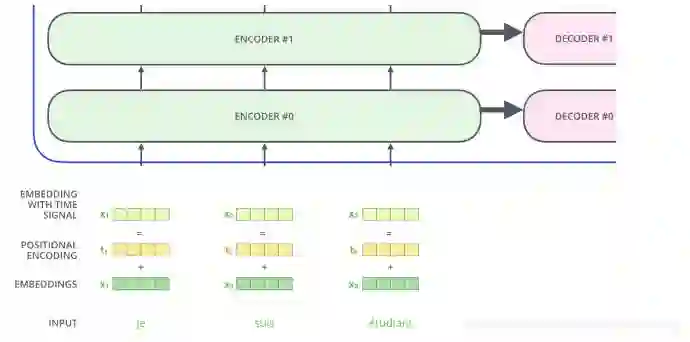
北京到上海的机票 vs 你好,我要北京到上海的机票
tranformer原始论文使用相对位置编码,后面的bert open gpt使用的是简单绝对位置编码: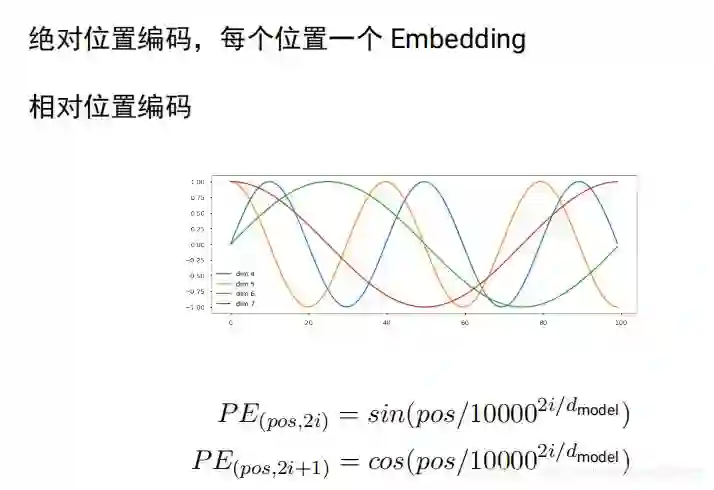
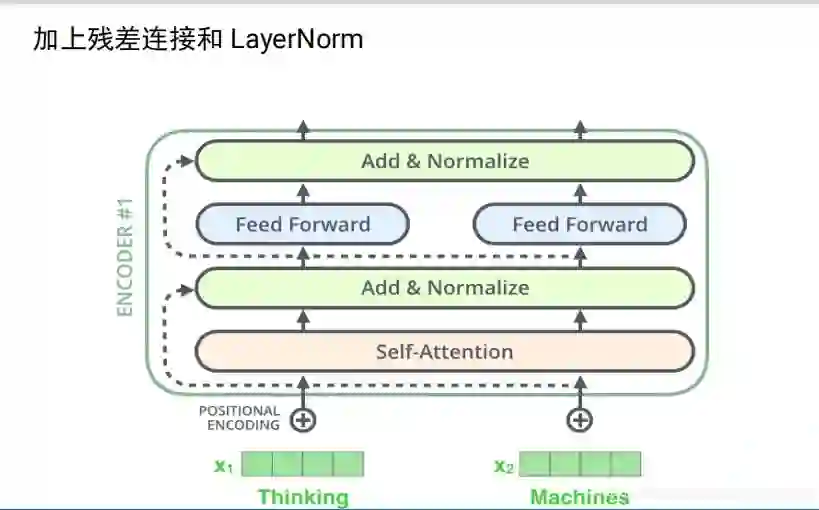
transformer中encoder的完整结构,加上了残差连接和layerNorm
decoder加上了普通的attention,最后一刻的输出,会输入。
transformer的decoder不能利用未知的信息,即单向信息流问题。
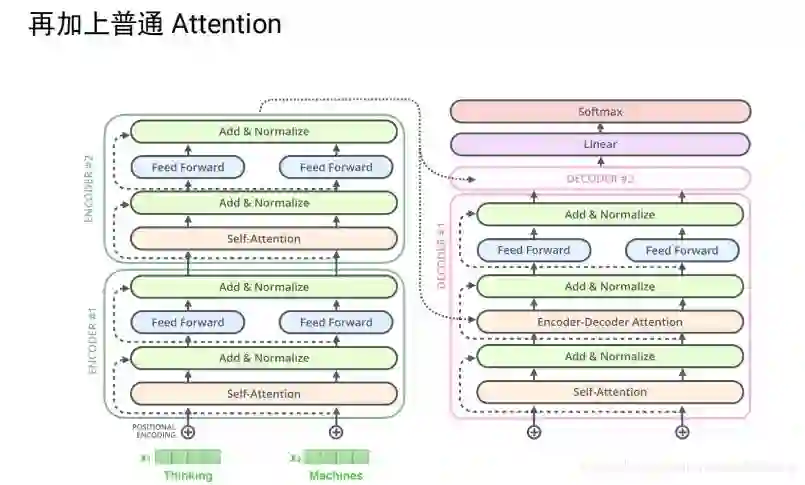
transformer 解决的问题:
可以并行计算,训练的很深,到后来的open gpt可以到12层 bert的16、24层;
单向信息流的问题:至少在encoder的时候考虑前面和后面的信息,所以可以取得很好的效果;
transformer解决了普通word embedding 没有上下文的问题,但是解决这个问题,需要大量的标注信息样本。
如何解决transformer的问题,就引入了elmo,elmo:无监督的考虑上下文的学习。
一个个的预测的语言模型:
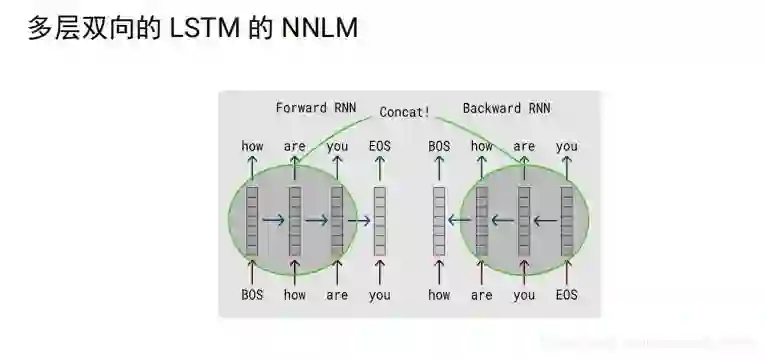
双向的lstm,每个向量2n,是一种特征提取的方法,考虑的上下文的,编码完,就定住了,
elmo:将上下文当作特征,但是无监督的语料和我们真实的语料还是有区别的,不一定的符合我们特定的任务,是一种双向的特征提取。
openai gpt就做了一个改进,也是通过transformer学习出来一个语言模型,不是固定的,通过任务 finetuning,用transfomer代替elmo的lstm。
openai gpt其实就是缺少了encoder的transformer。当然也没了encoder与decoder之间的attention。
openAI gpt虽然可以进行fine-tuning,但是有些特殊任务与pretraining输入有出入,单个句子与两个句子不一致的情况,很难解决,还有就是decoder只能看到前面的信息。
bert
bert从这几方面做了改进:
Masked LM
NSP Multi-task Learning
Encoder again
bert为什么更好呢?
单向信息流的问题 ,只能看前面,不能看后面,其实预料里有后面的信息,只是训练语言模型任务特殊要求只能看后面的信息,这是最大的一个问题;
其次是pretrain 和finetuning 几个句子不匹配。
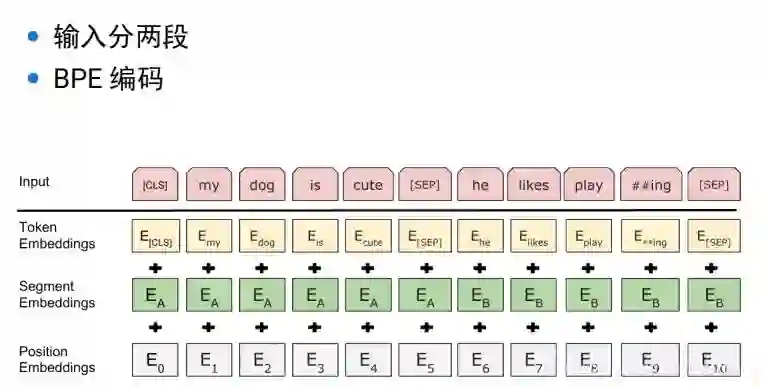
bert的输入是两个句子,分割符sep,cls表示开始,对输入的两个句子,使用位置编码, segment embeding 根据这个可以知道 该词属于哪个句子,学习会更加简单。可以很清楚知道第一句子需要编码什么信息,第二个句子可以编码什么信息。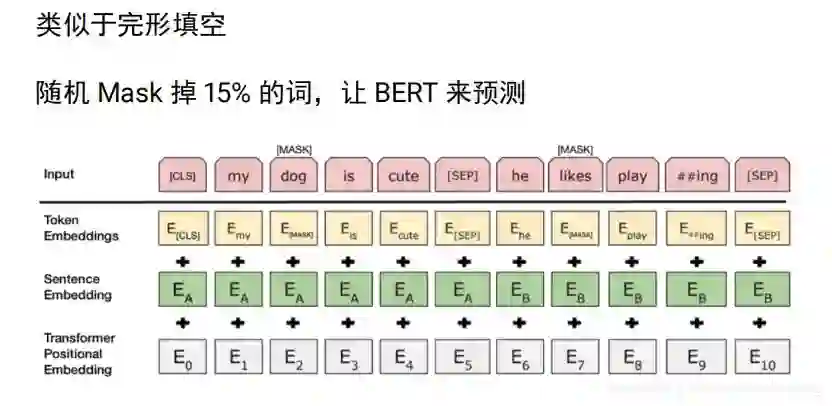
单向信息流问题:mask ml 有点类似与完形填空,根据上下文信息猜其中信息,计算出最大概率,随机丢掉15%的词来bert来进行预测,考虑前后双向的信息,怎么搞两个句子?
-50%概率抽连续句子 正样本1
50%概率抽随机句子 负样本 0
这样学习到两个句子的关系,可以预测句子关系,在一些问答场景下很重要。
finetuning
单个句子的任务,我们拿第一个cls向量,上面接一些全连接层,做一个分类,标注的数据 fine-tuningbert参数也包括全连接的一个参数,为什么选择第一个?
bert任务还是预测这个词,预测的时候会参考其他的词,如eat本身还是吃的语义,直接根据eat去分类,显然是不可以的,cls没有太多其他词的语义,所以它的语义完全来自其他的语义 来自整个句子,编码了整个句子的语义,用它做可以,当然也可以得出所有结果进行拼接后,再来进行预测。
注意:
使用中文模型,不要使用多语言模型
max_seq_length 可以小一点,提高效率
内存不够,需要调整 train_batch_size
有足够多的领域数据,可以尝试 Pretraining
bert的实际应用比较简单,不过多赘述内容,推荐简单的demo样例:
https://www.jianshu.com/p/3d0bb34c488a






