ICCV 2019 | 目标检测器也被攻击?百度开发对抗训练方法,模型鲁棒性飙升

作者 | BBuf
单位 | 北京鼎汉技术有限公司 算法工程师(CV)
编辑 | 唐里
下面要介绍的论文始发于 ICCV2019:
论文标题:Towards Adversarially Robust Object Detection
论文地址:https://arxiv.org/abs/1907.10310
目标检测是一项重要的视觉任务,已成为许多视觉系统中不可或缺的组成部分,其鲁棒性已成为实际应用中重要的性能指标。虽然最近的许多的研究表明,目标检测模型容易受到对抗攻击,但很少有人致力于提高其鲁棒性。
本文首先从模型鲁棒性的角度,回顾和系统地分析了目标检测器和近年来发展起来的各种攻击方法。然后,我们提出了目标检测的多任务学习观点,并确定了任务损失的不对称作用。我们进一步开发了一种对抗训练方法,可以利用多种攻击源来提高检测模型的鲁棒性。在PASCAL-VOC和MS-COCO上进行的大量实验证明了该方法的有效性。
研究背景

相关工作
再研究目标检测和攻击
3.1 目标检测作为多任务学习
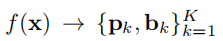 以
以
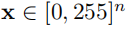 这张图像作为输入然后产生K个预测目标,每个目标都有一个类别
这张图像作为输入然后产生K个预测目标,每个目标都有一个类别
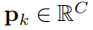 ,其中C代表所有类别(包括背景)以及一个边界框
,其中C代表所有类别(包括背景)以及一个边界框
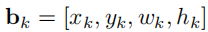 信息。
NMS作为后处理过程用于去除冗余的框,整个过程如Figure2所示。
信息。
NMS作为后处理过程用于去除冗余的框,整个过程如Figure2所示。

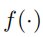 ,然后对检测器的训练可以表示为对θ的优化,公式如(1)所示。
,然后对检测器的训练可以表示为对θ的优化,公式如(1)所示。
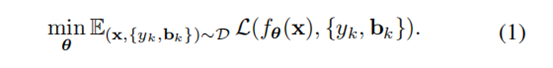
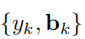 代表从数据集D中采样的图像以及边界框信息。
我们的目标是选出一个合适的θ来最小化检测器预测结果和数据集样本之间的损失,如等式(2)所示。
代表从数据集D中采样的图像以及边界框信息。
我们的目标是选出一个合适的θ来最小化检测器预测结果和数据集样本之间的损失,如等式(2)所示。
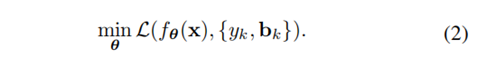
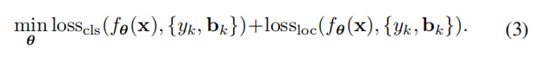
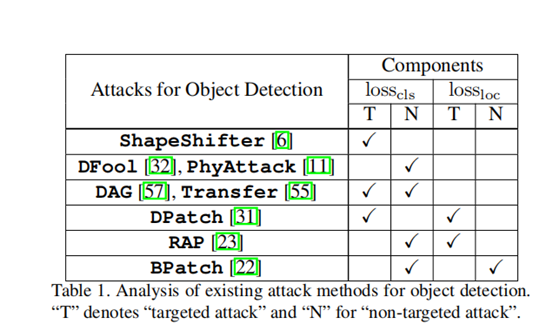
3.2 基于任务损失的检测攻击
对抗性鲁棒检测
4.1 任务损失在鲁棒性中的作用
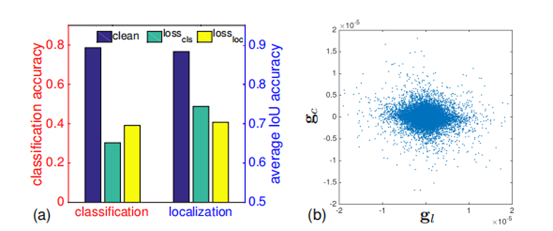
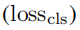 的攻击会降低分类性能并降低定位性能。
同样,定位损失的攻击
的攻击会降低分类性能并降低定位性能。
同样,定位损失的攻击
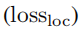 不仅降低了定位性能,还降低了分类性能。
从本质上讲,这可以视为跨任务攻击转移的一种类型。
即,仅使用于分类损失的生成对抗图像,攻击转到定位任务会降低其性能,反之亦然。
这是基于单个任务损失生成的对抗图像可以有效的攻击目标检测器的原因之一。
不仅降低了定位性能,还降低了分类性能。
从本质上讲,这可以视为跨任务攻击转移的一种类型。
即,仅使用于分类损失的生成对抗图像,攻击转到定位任务会降低其性能,反之亦然。
这是基于单个任务损失生成的对抗图像可以有效的攻击目标检测器的原因之一。
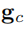 和
和
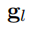 之间的逐点散度图如Figure3(b)所示。
我们有几个观察结果:
i)任务梯度的大小不相同,表示两个任务损失之间可能存在不平衡。
ii)任务梯度的方向不一致(非对角线),这意味着两个任务梯度之间可能存在冲突。
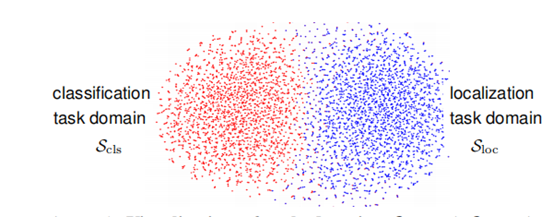
我们在Figure4中永TSNE进一步可视化每一个任务的梯度域。
之间的逐点散度图如Figure3(b)所示。
我们有几个观察结果:
i)任务梯度的大小不相同,表示两个任务损失之间可能存在不平衡。
ii)任务梯度的方向不一致(非对角线),这意味着两个任务梯度之间可能存在冲突。
我们在Figure4中永TSNE进一步可视化每一个任务的梯度域。
4.2 对抗性训练以提高鲁棒性
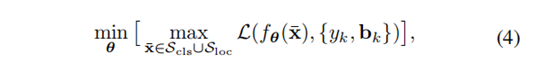
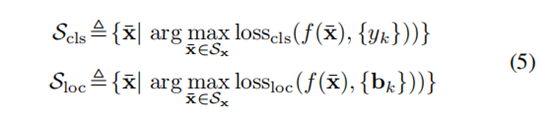
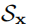 被定义为
被定义为
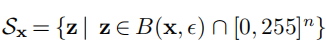 ,以及
,以及
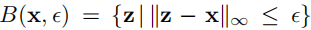 表示干净图像x和和产生的对抗图像z的空间距离被控制在干扰预算
表示干净图像x和和产生的对抗图像z的空间距离被控制在干扰预算
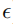 之内。
我们将
之内。
我们将
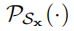 表示为将输入投影到可行域
的投影算子。
重要的是要注意与传统对抗训练相比在分类上的几个重要区别:
不同,我们引入了一种面向任务的领域约束
表示为将输入投影到可行域
的投影算子。
重要的是要注意与传统对抗训练相比在分类上的几个重要区别:
不同,我们引入了一种面向任务的领域约束
 ,该约束将可行域限定为最大化分类损失或定位损失的图像集。
用于训练的最后一个对抗示例是使该集合中的整体损失最大化的例子。
提出的具有任务域约束的公式的关键优势在于,我们可以在每项任务的指导下产生对抗性的例子,而不受它们之间的干扰。
,设置与完整图像对应的边界框的坐标,并为图像分配单个类别标签,则公式(4)会被简化为用于分类的常规的对抗训练设置。
因此,我们可以将提出的鲁棒检测对抗训练看作是传统对抗训练在分类环境下的自然推广。
然而,需要注意的是,虽然这两个任务都有助于根据其整体优势提高模型的预期稳健性,但由于检测任务领域不同于,在生成单个对抗示例的任务之间不存在干扰。
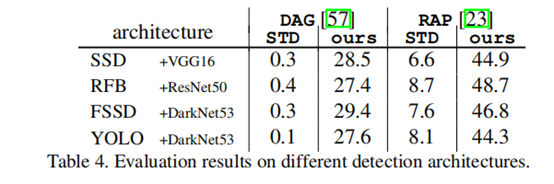
整个算法过程可以被总结为Algorithm1。
,该约束将可行域限定为最大化分类损失或定位损失的图像集。
用于训练的最后一个对抗示例是使该集合中的整体损失最大化的例子。
提出的具有任务域约束的公式的关键优势在于,我们可以在每项任务的指导下产生对抗性的例子,而不受它们之间的干扰。
,设置与完整图像对应的边界框的坐标,并为图像分配单个类别标签,则公式(4)会被简化为用于分类的常规的对抗训练设置。
因此,我们可以将提出的鲁棒检测对抗训练看作是传统对抗训练在分类环境下的自然推广。
然而,需要注意的是,虽然这两个任务都有助于根据其整体优势提高模型的预期稳健性,但由于检测任务领域不同于,在生成单个对抗示例的任务之间不存在干扰。
整个算法过程可以被总结为Algorithm1。





登录查看更多
相关内容
专知会员服务
51+阅读 · 2020年3月31日
Arxiv
6+阅读 · 2018年12月6日
Arxiv
4+阅读 · 2018年9月23日
Arxiv
3+阅读 · 2018年8月2日

相关VIP内容
专知会员服务
51+阅读 · 2020年3月31日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年12月6日
Arxiv
4+阅读 · 2018年9月23日
Arxiv
3+阅读 · 2018年8月2日