文本也有攻防战:清华大学开源对抗样本必读论文列表
机器之心报道
参与:思源、戴一鸣
在自然语言处理领域,对抗样本的攻击与防御近来受到很多研究者的关注,我们希望构建更稳健的 NLP 模型。在本文中,我们简要讨论了攻防的概念,并介绍了清华大学近日开源的 NLP 对抗样本攻防必读论文列表。

自然语言处理方面的研究在近几年取得了惊人的进步,深度神经网络模型已经取代了许多传统的方法。但是,当前提出的许多自然语言处理模型并不能够反映文本的多样特征。因此,许多研究者认为应该开辟新的研究方法,特别是利用近几年较为流行的对抗样本生成和防御的相关研究方法。
使用对抗样本生成和防御的自然语言处理研究可以基本概括为以下三种:1. 用未察觉的扰动迷惑模型,并评价模型在这种情况下的表现;2. 有意的改变深度神经网络的输出;3. 检测深度神经网络是否过于敏感或过于稳定,并寻找防御攻击的方法。
Jia 和 Liang 首先考虑在深度神经网络中采用对抗样本生成(或者「对抗攻击」,两者皆可)方法完成文本处理相关任务。他们的研究在自然语言处理社区很快获得了研究方面的关注。
然而,由于图片和文本数据内在的不同,用于图像的对抗攻击方法无法直接应用与文本数据上。首先,图像数据(例如像素值)是连续的,但文本数据是离散的。其次,仅仅对像素值进行微小的改变就可以造成图像数据的扰动,而且这种扰动是很难被人眼差距的。但是对于文本的对抗攻击中,小的扰动很容易被察觉,但人类同样能「猜出」本来表达的意义。因此 NLP 模型需要对可辨识的特征鲁棒,而不像视觉只需要对「不太重要」的特征鲁棒。
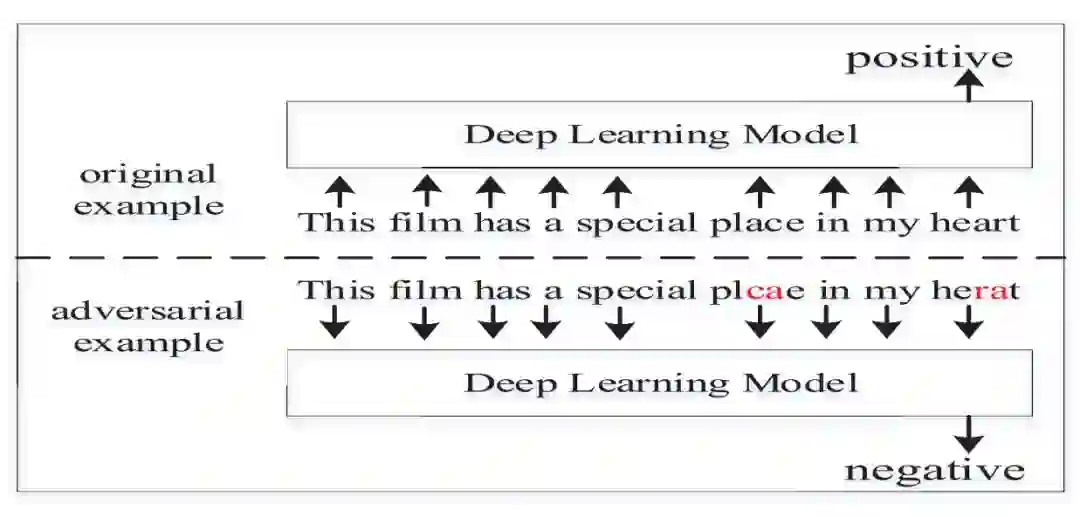
DeepWordBug 的深度网络攻击示例。选自 arXiv:1902.07285
与图像领域一样,有进攻就会有防御,目前也有很多研究尝试构建更鲁棒的自然语言处理模型。例如在 CMU 的一篇对抗性拼写错误论文(arXiv:1905.11268)中,研究者通过移除、添加或调序单词内部的字符,以构建更稳健的文本分类模型。这些增减或调序都是一种扰动,就像人类也很可能出现这些笔误一样。通过这些扰动,模型能学会如何处理错别字,从而不至于对分类结果产生影响。
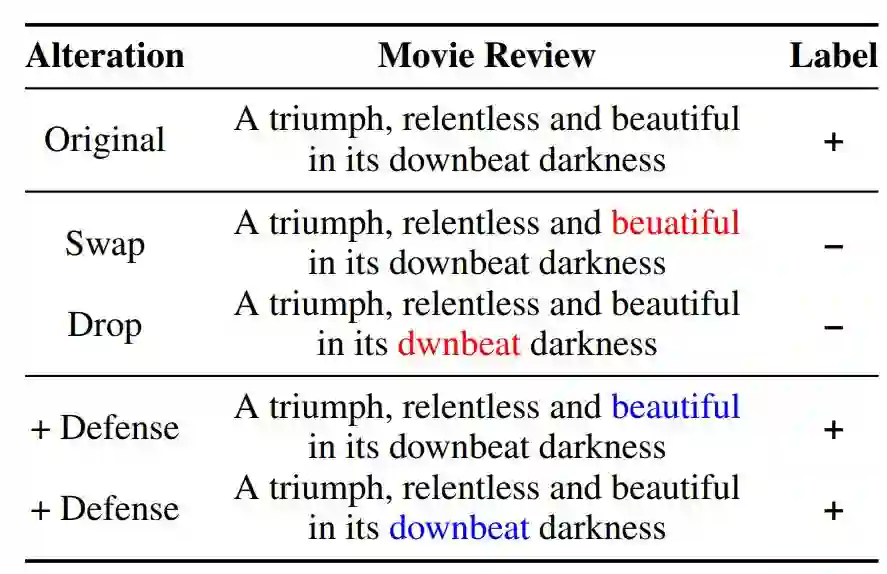
对抗性拼写错误导致的情感误分类,与通过字识别防御手段获得的更稳健模型。选自 arXiv:1905.11268
除了文本分类,也有很多研究者通过对抗训练构建更稳健的翻译系统。清华大学刘洋老师表示,如果我们修改原文的某个字,那么很可能译文就完全变了,目前的 NMT 系统并不是太稳健。
刘洋老师表示,目前比较多的方法是在训练中加入噪声而让 NMT 模型学会抵御随机扰动。如下图所示,X 是正确的输入,会加一些噪声以形成 X'。当我们用神经网络进行学习的时候,会生成两种内部表示 H_x 和 H_x'。我们希望这两种内部表示对于判别器 Discriminator 是不可区分的,如果不可区分,就说明噪声不会对预测做出更大的影响。
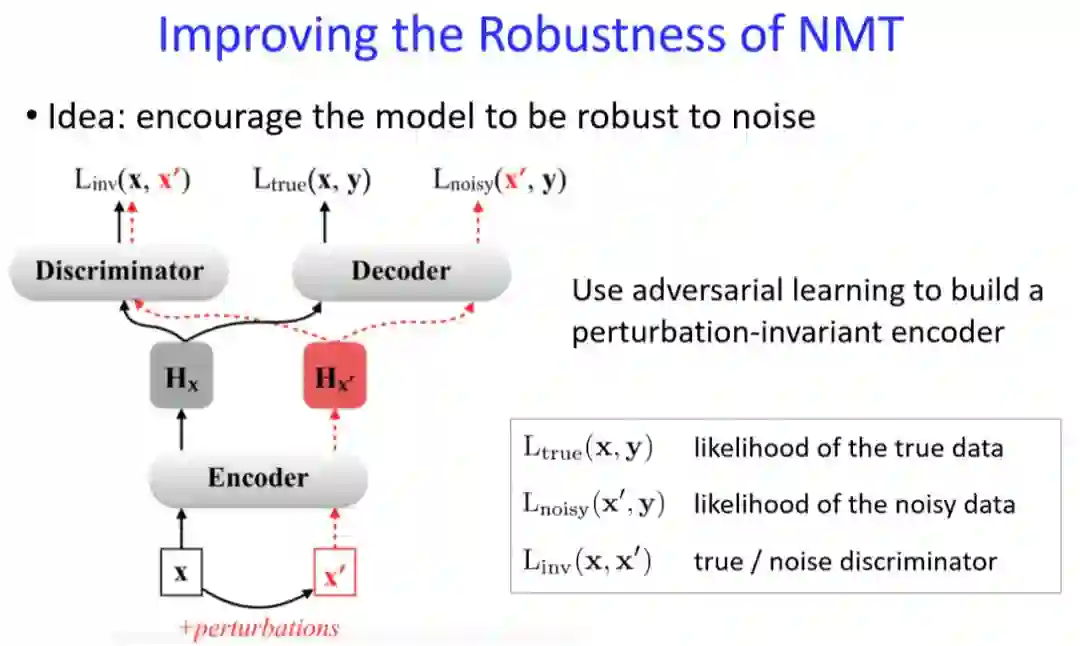
其中噪声可以是从真实数据获取的人类误差,也可以是随机生成的噪声。当机器翻译模型能抵御这些噪声,那么它就非常鲁棒了。
NLP 对抗样本攻防战必读论文
虽然,自然语言领域的对抗攻防仍然有很多困难,但目前已经有一批优秀的论文。最近清华大学杨承昊、岂凡超和臧原同学整理了一份必读论文,其从整体的综述论文到攻击、防御方法介绍了该领域的前沿研究工作。如下仅展示了论文名,具体的论文地址可查看原 GitHub 项目。
项目地址:https://github.com/thunlp/TAADpapers
综述论文
文本攻击与防御的论文概述:
Analysis Methods in Neural Language Processing: A Survey. Yonatan Belinkov, James Glass. TACL 2019.
Towards a Robust Deep Neural Network in Text Domain A Survey. Wenqi Wang, Lina Wang, Benxiao Tang, Run Wang, Aoshuang Ye. 2019.
Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey. Wei Emma Zhang, Quan Z. Sheng, Ahoud Alhazmi, Chenliang Li. 2019.
黑盒攻击
PAWS: Paraphrase Adversaries from Word Scrambling. Yuan Zhang, Jason Baldridge, Luheng He. NAACL-HLT 2019.
Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems. Steffen Eger, Gözde Gül ¸Sahin, Andreas Rücklé, Ji-Ung Lee, Claudia Schulz, Mohsen Mesgar, Krishnkant Swarnkar, Edwin Simpson, Iryna Gurevych.NAACL-HLT 2019.
Adversarial Over-Sensitivity and Over-Stability Strategies for Dialogue Models. Tong Niu, Mohit Bansal. CoNLL 2018.
Generating Natural Language Adversarial Examples. Moustafa Alzantot, Yash Sharma, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, Kai-Wei Chang. EMNLP 2018.
Breaking NLI Systems with Sentences that Require Simple Lexical Inferences. Max Glockner, Vered Shwartz, Yoav Goldberg ACL 2018.
AdvEntuRe: Adversarial Training for Textual Entailment with Knowledge-Guided Examples. Dongyeop Kang, Tushar Khot, Ashish Sabharwal, Eduard Hovy. ACL 2018.
Semantically Equivalent Adversarial Rules for Debugging NLP Models. Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin ACL 2018.
Robust Machine Comprehension Models via Adversarial Training. Yicheng Wang, Mohit Bansal. NAACL-HLT 2018.
Adversarial Example Generation with Syntactically Controlled Paraphrase Networks. Mohit Iyyer, John Wieting, Kevin Gimpel, Luke Zettlemoyer. NAACL-HLT 2018.
Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers. Ji Gao, Jack Lanchantin, Mary Lou Soffa, Yanjun Qi. IEEE SPW 2018.
Synthetic and Natural Noise Both Break Neural Machine Translation. Yonatan Belinkov, Yonatan Bisk. ICLR 2018.
Generating Natural Adversarial Examples. Zhengli Zhao, Dheeru Dua, Sameer Singh. ICLR 2018.
Adversarial Examples for Evaluating Reading Comprehension Systems. Robin Jia, and Percy Liang. EMNLP 2017.
白盒攻击
On Adversarial Examples for Character-Level Neural Machine Translation. Javid Ebrahimi, Daniel Lowd, Dejing Dou. COLING 2018.
HotFlip: White-Box Adversarial Examples for Text Classification. Javid Ebrahimi, Anyi Rao, Daniel Lowd, Dejing Dou. ACL 2018.
Towards Crafting Text Adversarial Samples. Suranjana Samanta, Sameep Mehta. ECIR 2018.
同时探讨了黑盒和白盒攻击
TEXTBUGGER: Generating Adversarial Text Against Real-world Applications. Jinfeng Li, Shouling Ji, Tianyu Du, Bo Li, Ting Wang. NDSS 2019.
Comparing Attention-based Convolutional and Recurrent Neural Networks: Success and Limitations in Machine Reading Comprehension. Matthias Blohm, Glorianna Jagfeld, Ekta Sood, Xiang Yu, Ngoc Thang Vu. CoNLL 2018.
Deep Text Classification Can be Fooled. Bin Liang, Hongcheng Li, Miaoqiang Su, Pan Bian, Xirong Li, Wenchang Shi.IJCAI 2018.
对抗防御
Combating Adversarial Misspellings with Robust Word Recognition. Danish Pruthi, Bhuwan Dhingra, Zachary C. Lipton. ACL 2019.
评估
对文本攻击和防御研究提出新的评价方法:
On Evaluation of Adversarial Perturbations for Sequence-to-Sequence Models. Paul Michel, Xian Li, Graham Neubig, Juan Miguel Pino. NAACL-HLT 2019
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

