【深度】脆弱的神经网络:UC Berkeley详解对抗样本生成机制
选自ML Blog of Berkeley
作者:Daniel Geng、Rishi Veerapaneni
来源:机器之心
参与:陈韵竹、刘晓坤、李泽南
用于「欺骗」神经网络的对抗样本(adversarial example)是近期计算机视觉,以及机器学习领域的热门研究方向。只有了解对抗样本,我们才能找到构建稳固机器学习算法的思路。本文中,UC Berkeley 的研究者们展示了两种对抗样本的制作方法,并对其背后的原理进行了解读。
通过神经网络进行暗杀——听起来很疯狂吧?也许有一天,这真的可能上演,不过方式可能与你想象中不同。显然,加以训练的神经网络能够驾驶无人机或操作其他大规模杀伤性武器。但是,即便是无害的(现在可用的)网络——例如,用于驾驶汽车的网络——也可能变成车主的敌人。这是因为,神经网络非常容易被「对抗样本(adversarial example)」攻击。
在神经网络中,导致网络输出不正确的输入被称为对抗样本。我们最好通过一个例子来说明。让我们从左边这张图开始。在某些神经网络中,这张图像被认为是熊猫的置信度是 57.7%,且其被分类为熊猫类别的置信度是所有类别中最高的,因此网络得出一个结论:图像中有一只熊猫。但是,通过添加非常少量的精心构造的噪声,可以得到一个这样的图像(右图):对于人类而言,它和左图几乎一模一样,但是网络却认为,其被分类为「长臂猿」的置信度高达 99.3%。这实在太疯狂了!

上图源自: Explaining and Harnessing Adversarial Examples,Goodfellow et al
那么,对抗样本如何进行暗杀呢?想象一下,如果用一个对抗样本替换一个停车标志——也就是说,人类可以立即识别这是停车标志,但神经网络不能。现在,如果把这个标志放在一个繁忙的交叉路口。当自动驾驶汽车接近交叉路口时,车载神经网络将无法识别停车标志,直接继续行驶,从而可能导致乘客死亡(理论上)。
以上只是那些复杂、稍显耸人听闻的例子之一,其实还会有更多利用对抗样本造成伤害的例子。例如,iPhone X 的「Face ID」解锁功能依赖神经网络识别人脸,因此容易受到对抗性攻击。人们可以通过构建对抗图像,避开 Face ID 安全功能。其他生物识别安全系统也将面临风险:通过使用对抗样本,非法或不合宜的内容可能会绕开基于神经网络的内容过滤器。这些对抗样本的存在意味着,含有深度学习模型的系统实际上有极高的安全风险。

为了理解对抗样本,你可以把它们想象成神经网络的「幻觉」。既然幻觉可以骗过人的大脑,同样地,对抗样本也能骗过神经网络。
上面这个熊猫对抗样本是一个有针对性的 (targeted) 例子。少量精心构造的噪声被添加图像中,从而导致神经网络对图像进行了错误的分类。然而,这个图像在人类看来和之前一样。还有一些无针对性 (non-targeted) 的例子,它们只是简单尝试找到某个能蒙骗神经网络的输入。对于人类来说,这种输入看起来可能像是白噪声。但是,因为我们没有被限制为寻找对人而言类似某物的输入,所以这个问题要容易得多。
我们可以找到将近所有神经网络的对抗样本。即使是那些最先进的模型,有所谓「超人类」的能力,也轻微地受此问题困扰。事实上,创建对抗样本非常简单。在本文中,我们将告诉你如何做到。用于开始生成你自己的对抗样本的所有所需代码等资料都可以在这个 github 中找到:https://github.com/dangeng/Simple_Adversarial_Examples

上图展示了对抗样本的效果
MNIST 中的对抗样本
这一部分的代码可以在下面的链接中找到(不过阅读本文并不需要下载代码):https://github.com/dangeng/Simple_Adversarial_Examples
我们将试着欺骗一个普通的前馈神经网络,它已经在 MNIST 数据集上经过训练。MNIST 是 28×28 像素手写数字图像的数据集,就像下面这样:
6 张 MNIST 图像并排摆放
首先,我们需要导入所需的库:
import network.network as networkimport network.mnist_loader as mnist_loaderimport pickleimport matplotlib.pyplot as pltimport numpy as np
其中有 50000 张图像作为训练集,10000 张作为测试集。首先,加载预训练的神经网络(这是我从这个神经网络的介绍中找来的 http://neuralnetworksanddeeplearning.com/):
with open('trained_network.pkl', 'rb') as f:net = pickle.load(f)training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
有些人可能不太熟悉 pickle。这是 python 序列化数据(即,写入磁盘)从而保存类与对象的一种方法。使用 pickle.load() 可以打开保存的神经网络版本。
现在来说说这个预训练神经网络吧。它具有 784 个输入神经元(每个神经对应一个像素,共 28×28 = 784 个像素)、一个含有 30 个神经元的隐藏层,以及 10 个输出神经元(每个数字对应一个神经元)。所有的激活函数都是 sigmoid 类型。它的输出是一个指示网络预测的 one-hot 向量,并且通过最小化均方误差损失来进行训练。
为了证明这个神经网络实际上已经经过训练,我们可以写一个简单的函数:
def predict(n):# Get the data from the test setx = test_data[n][0]# Get output of network and predictionactivations = net.feedforward(x)prediction = np.argmax(activations)# Print the prediction of the networkprint('Network output: ')print(activations)print('Network prediction: ')print(prediction)print('Actual image: ')# Draw the imageplt.imshow(x.reshape((28,28)), cmap='Greys')
该方法从测试集中选择第 n 个样本,将其显示出来,然后使用 net.feedforward(x) 在神经网络中执行。以下是一些图片的输出:
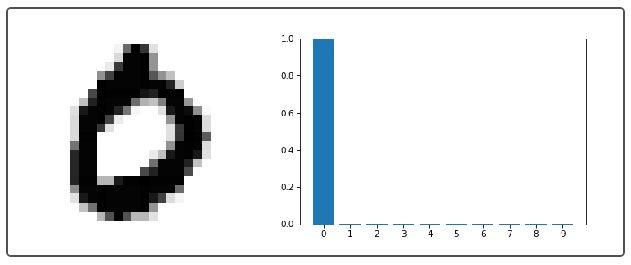


左侧显示的是 MNIST 图像。右侧绘制了神经网络的 10 个输出,称为激活。输出的激活越大,神经网络越有可能认为图像就是这个数字。
好的,所以现在我们有一个预训练的网络了。但是,我们怎么去欺骗它呢?让我们首先从一个简单的无针对性方法开始。然后,一旦我们把这个方法弄清楚,我们就可以用一个很棒的小技巧对此加以修改,从而获得一个针对性的方法。
无针对性攻击(Non-Targeted Attack)
这个想法就是要生成某种图像,使神经网络有确定的输出。例如,我们的目标标签/输出是:

也就是说,我们想要得到这样一个图像,使得神经网络的输出就是以上矢量。换句话说,我们想找到一个使神经网络认为是 5 的图像(记住,我们使用了零索引)。事实证明,我们可以将这作为一个优化问题,就像我们训练一个网络一样。我们将我们想要制作的图像为 ⃗x(一个 784 维矢量,因为将 28×28 像素的图像展平可使计算更容易)。我们将成本函数定义为:

其中,∥⋅∥22 代表 L2 范数的平方。y_goal 是上面的目标标签。在给定神经网络中,图像的输出是
请注意,这个问题与我们如何训练一个神经网络非常相似。其中,我们也定义一个成本函数,然后选择使成本函数最小化的权重和偏差(也称为参数)。在对抗样本生成这一情况下,我们并不通过选择权重和偏差来最小化成本函数,而是将权重和偏差保持不变(实质上保持整个网络不变),并选择一个最小化成本函数的 ⃗x 输入。
为此,我们将采用与训练神经网络完全相同的方法。也就是说,我们将使用梯度下降!我们可以使用反向传播,找到成本函数于输入的偏导数,然后使用梯度下降进行更新,找到最小化成本的最佳值 ⃗x。
反向传播通常用于查找成本函数对权重和偏差的梯度,但从完全一般性的角度,反向传播只是一种算法,可以有效地计算计算图(也就是一个神经网络)中的梯度。因此,它也可以用来计算神经网络中成本函数对输入的梯度。
好的,下面让我们看看实际中生成对抗样本的代码:
def adversarial(net, n, steps, eta):"""net : network objectneural network instance to usen : integerour goal label (just an int, the function transforms it into a one-hot vector)steps : integernumber of steps for gradient descenteta : integerstep size for gradient descent"""# Set the goal outputgoal = np.zeros((10, 1))goal[n] = 1# Create a random image to initialize gradient descent withx = np.random.normal(.5, .3, (784, 1))# Gradient descent on the inputfor i in range(steps):# Calculate the derivatived = input_derivative(net,x,goal)# The GD update on xx -= eta * dreturn x
首先我们创建 y_goal,在代码中被称为「goal」。接下来我们将向量 ⃗x 初始化为一个随机的 784 维向量。有了这个矢量,我们现在可以开始进行梯度下降,实际上这只有两行代码。
第一行 d = input_derivative(net,x,goal)使用反向传播计算∇xC(有些人可能对此代码的原理感到好奇,但是我们不在此描述它,这实际上涉及大量数学计算。如果你想知道反向传播做什么,也就是 input_derivative 做什么,请在以下网站中查看:http://neuralnetworksanddeeplearning.com/chap2.html)
梯度下降循环的第二行,也是最后一行,即 x - = eta * d,实现更新。我们沿着与步长大小 eta 相反的方向进行移动。
下面是每个类别的非针对性对抗样本示例,以及在神经网络中的预测:

左侧是非针对性对抗样本(一个 28×28 像素的图像)。右侧是给出此图像时绘制网络的激活。
难以相信,神经网络认为,一些图像实际上是一个数字,且置信度很高。这个「3」和「5」就是很好的例子。对于其他许多数字而言,神经网络对于每个数字的激活结果都很低,表明它非常混乱。看起来不错!
在这里,可能你会有些困惑。如果我们想做一个对应于 5 的对抗样本,那么我们所希望的是找到一个 ⃗x,当给神经网络一个输入时,输出尽可能接近表示「5」的 one-hot 向量。但是,为什么梯度下降的结果,并非只找到一个「5」的图像?毕竟,神经网络几乎可以肯定地认为,「5」的图像实际上就是「5」(因为它实际上确定是「5」)。关于此事为何发生的一个可能理论如下:
所有可能的 28×28 的图像空间是非常巨大的。一共有 256^(28×28)≈10^1888 种不同可能性的 28×28 像素的黑白图像。为了便于比较,可观测宇宙中原子数量的普遍估计是 10^80 个。如果宇宙中的每个原子包含另一个宇宙,那么我们将有 10^160 个原子。如果宇宙的每个原子包含另一个宇宙,那个宇宙中的每个原子还包含另一个宇宙……这样嵌套约 23 次的话,基本上将可以达到 10^1888 个原子。基本上,可能的图像数量是如此令人难以置信的巨大。
但在这所有的照片中,本质上只有微不足道的一部分在人类看来像「数字」。鉴于有这么多图像,其中有很大一部分对神经网络来说看似是数字(这个问题的部分原因在于,神经网络没有在那些「不像」数字的图像上进行训练,所以如果给神经网络输入一个不像数字的图像,它的输出是非常随机的)。所以,当我们开始寻找对神经网络而言像数字的图像时,我们更有可能找到一个看起来像噪声的图像,而非纯属偶然地找到一个对人类而言和数字类似的图像。
针对性攻击(Targeted Attack)
上述对抗样本的确很不错。但对人类来说,它们看起来像噪声。如果我们的对抗样本在人类看来像是什么别的东西,不是更棒吗?也许一个实际上是 2 的图像,神经网络会认为是 5 呢?事实证明,这是可能的!而且,只需要对我们原来的代码进行非常小的修改。我们可以做的是在需要最小化的成本函数中添加一个项。新的成本函数表示如下:

其中,x_target 是我们希望对抗样本看起来像的那个东西(因此 x_target 是一个 784 维矢量,与我们的输入相同的维度)。所以,我们现在所做的是同时最小化两个项。其中,左边的那项

我们之前已经见过。如果将其最小化,将会使得在 ⃗x 给定的情况下,让神经网络的输出接近 y_goal。如果最小化第二项

试图迫使我们的对抗图像 x 尽可能地接近 x_target(因为两个向量越接近,范数越小),这正是我们想要的!前面额外的 λ 是一个超参数,它能指明前后哪个项更重要。与大多数超参数一样,经过大量的试验和错误,我们发现将 λ 设置为 0.05 很不错。
如果你了解岭回归,你会发现上面的成本函数看起来非常熟悉,事实上,我们可以将上述成本函数解释为我们对抗样本中的模型先验。
实现对新的成本函数最小化的代码与原始代码几乎相同(我们将新的代码称为函数 sneaky_adversarial(),因为它使用针对性的样本,进行偷偷摸摸(sneaky)的攻击。命名总是编程中最难的部分……)
def sneaky_adversarial(net, n, x_target, steps, eta, lam=.05):"""net : network objectneural network instance to usen : integerour goal label (just an int, the function transforms it into a one-hot vector)x_target : numpy vectorour goal image for the adversarial examplesteps : integernumber of steps for gradient descenteta : integerstep size for gradient descentlam : floatlambda, our regularization parameter. Default is .05"""# Set the goal outputgoal = np.zeros((10, 1))goal[n] = 1# Create a random image to initialize gradient descent withx = np.random.normal(.5, .3, (784, 1))# Gradient descent on the inputfor i in range(steps):# Calculate the derivatived = input_derivative(net,x,goal)# The GD update on x, with an added penalty# to the cost function# ONLY CHANGE IS RIGHT HERE!!!x -= eta * (d + lam * (x - x_target))return x
我们唯一改变的是梯度下降更新:x -= eta * (d + lam * (x - x_target))。附加项正是对成本函数中新的项的解释。让我们来看看这种新方法的结果:
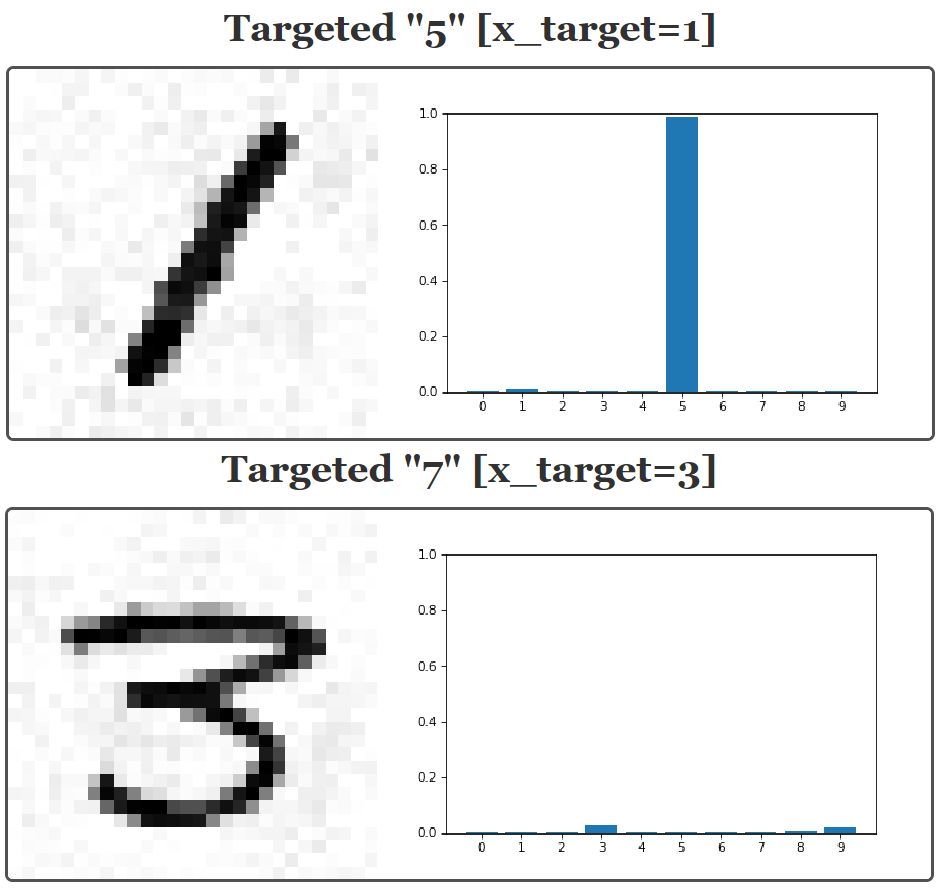
左侧是针对性对抗样本的实例(一个 28x28 的像素图像)。右侧是在给出左图后,神经网络给出的激活。
请注意,与非针对性攻击一样,攻击后可能出现两种行为。一种可能是神经网络完全被欺骗,即我们想要的数字的激活非常高(例如「针对性 5」图像);另一种可能是,对网络进行了混淆,导致所有的输出激活都很低(例如「针对性 7」图像)。有趣的是,现在有更多的图像在前一类,即完全欺骗神经网络,而不是混淆它。看起来,让对抗样本变得更「类似数字」,倾向于在梯度下降时进行更好地收敛。
保护神经网络免受对抗攻击
真棒!我们刚刚创建了能骗过神经网络的图像。我们的下一个问题是,是否可以防范这种攻击。如果仔细观察原始图像和对抗样本,你会发现对抗性示例子有一些淡灰色背景。

上图是一个背景中带噪声的对抗样本。单击图片可以切换原始图片和对抗样本。
(上图左侧是原始图片,右侧是对抗样本)
我们可以尝试一个非常简单的做法,那就是利用二进制阈值完全清除背景:
def binary_thresholding(n, m):"""n: int 0-9, the target number to matchm: index of example image to use (from the test set)"""# Generate adversarial examplex = sneaky_generate(n, m)# Binarize imagex = (x > .5).astype(float)print("With binary thresholding: ")plt.imshow(x.reshape(28,28), cmap="Greys")plt.show()# Get binarized output and predictionbinary_activations = net.feedforward(x)binary_prediction = np.argmax(net.feedforward(x))print("Prediction with binary thresholding: ")print(binary_prediction)print("Network output: ")print(binary_activations)
以下是结果:

以上展示了二进制阈值对 MNIST 对抗样本的影响。左侧是图像,右侧是神经网络的输出。单击图片可以在二进制图像和对抗样本之间切换。
原来,二进制阈值确实可以防范攻击!但这种防范对抗攻击的方式并不是很好。并非所有图像都有全白的背景。比如,我们可以看看文章一开始提到的熊猫图像。对图像进行二值化阈值处理可能会消除噪声,但也会极大程度地干扰大熊猫的形象。二值化后,网络(和人类)甚至可能都无法区分它是否是熊猫。

对熊猫进行二进制阈值处理会导致图像不稳定
我们还可以尝试一种更一般性的方法。那就是训练一个能在对抗样本和原始训练、测试集中表现都正确的神经网络。执行此操作的代码位于 ipython notebook 中(请注意,大概需要 15 分钟才能运行)。这样做的话,它在所有对抗图像的测试集中,准确率高达 94%,这相当不错。但是,这种方法的也有其局限性。主要原因是,在现实生活中,你无法知道攻击者如何生成对抗样本。
在这篇介绍性的文章中,我们无法一一阐释其他更多防范对抗攻击的方法,不过这个问题仍然是一个开放的研究课题。如果你对此感兴趣,还可以查阅更多关于这个主题的优秀论文。
黑盒攻击
对抗样本中有一个有趣而重要的观察,那就是对抗样本通常不特定于某个模型或架构。针对某个神经网络架构生成的对抗样本可以很好地转换到另一个架构中。换句话说,如果你想欺骗某个模型,你可以先创建自己的模型和基于此模型的对抗样本。那么,这些同样的对抗样本也很可能欺骗另一个模型。
这具有重大的意义。因为,这意味着有可能对一个完全的黑箱模型创建一个对抗样本。对于这个黑箱模型,我们无需了解其中的内部机制。实际上,伯克利的一个小组使用这种方法在商业性的人工智能分类系统中发起了一次成功的攻击:https://arxiv.org/pdf/1611.02770.pdf
小结
随着人类走向未来,日常生活中将会融入越来越多的神经网络和深度学习算法。我们必须小心,要记住,这些神经网络模型极其容易被蒙骗。尽管神经网络在某种程度上受到了生物学的启发,并且在各种各样的任务中具有接近(或超过)人类的能力,但对抗样本告诉我们,它们的操作方法与真实生物体的工作方式不同。正如我们所看到的,神经网络容易以一种对我们人类来说是完全陌生的方式灾难性地失败。
我们没有完全理解神经网络,因此用我们人类的直觉来描述神经网络并不明智。例如,你会经常听到人们说「神经网络将图像分类为猫,是因为橙色皮毛」。事实上,神经网络并不进行人类意义上的「思考」。基本上,它们只是一系列矩阵乘法,还有一些增加的非线性操作。正如对抗样本所表明的,这些模型的输出非常脆弱。我们必须小心,尽管神经网络的确具备人类的某些能力,但不要认为人的特质也属于神经网络。也就是说,我们不能将机器学习模型拟人化(https://blog.keras.io/the-limitations-of-deep-learning.html)。

已训练用于检测哑铃的神经网络「相信」,「哑铃」有时能与脱离身体的手臂配对。这显然不是我们所期望的。(图片来自 Google Research)
总而言之,对抗样本应该让我们感到谦卑。它们表明,虽然我们的技术已经有了很大的飞跃,但是还有许多谜团等待我们去探索。

原文链接:https://ml.berkeley.edu/blog/2018/01/10/adversarial-examples/
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【深度】DeepMind高级研究员:重新理解GAN,最新算法、技巧及应用(59页PPT)



