对抗样本并非bug,它们只是特征罢了
选自 arxiv
作者:Andrew Ilyas 等
机器之心编译
参与:路雪、思源
对抗样本难道是模型中的 bug 吗?我们是不是可以通过对抗训练或其它方式完全解决这个问题?MIT 的研究者表示,对抗样本仅仅是一些特征,而且从监督学习角度来看,这些稳健或非稳健特征具备同等的重要性。
对抗样本在机器学习领域受到广泛关注,但它们存在和流行的原因却并不明晰。来自 MIT 的一项研究表明,对抗样本的产生可直接归因于非稳健特征的出现:某些来自数据分布模式的特征具备高度预测性,但对于人类来讲是脆弱且难以理解的。
研究者构建了一个理论框架,并在其中捕捉这些特征,从而在标准数据集中建立了它们的广泛存在。最终,研究者展示了一个简单的任务设置,在该设置中研究者将实践中观察到的对抗样本现象,与(人类设定的)稳健性概念和数据内部几何之间的不匹配性严格地联系起来。
论文:Adversarial Examples Are Not Bugs, They Are Features

论文地址:https://arxiv.org/pdf/1905.02175.pdf
什么是对抗样本?
近年来,深度神经网络的脆弱性吸引了大量关注,尤其是对对抗样本现象的担忧:对自然输入进行微小的扰动就会使当前最优的分类器出现错误的预测结果,而这种扰动在人类看来是不影响整体的。
如下图所示给定一张熊猫的图像,攻击方给图片添加了微小的噪声扰乱,尽管人眼是很难区分的,但是模型却以非常高的概率将其误分类为长臂猿。随着机器学习的大规模应用,这类误差对于系统安全显得尤为重要。
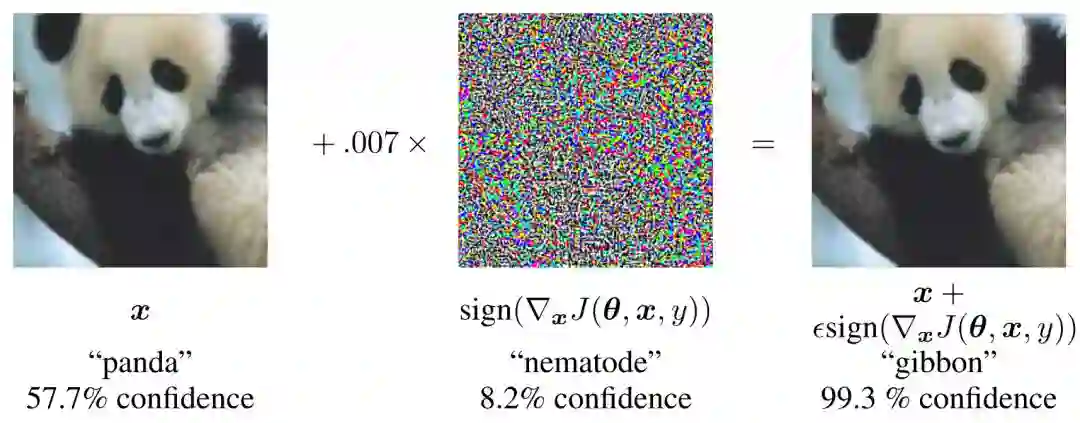
上图为 Ian Goodfellow 在 14 年展示的对抗样本,这种对抗样本是通过一种名为 FGSM 的算法得出。
既然对抗样本的危害这么大,那么理解它的原因就非常重要了。一般而言,该领域之前的研究大多把对抗样本视为高维输入空间产生的畸变,或训练数据中统计波动导致的偏差。
从这个观点来看,将对抗稳健性作为目标是非常顺理成章的,这个目标可以仅通过最大化模型准确率来解决或达到,而最大化准确率可以通过改善标准正则化方法或网络输入/输出的预处理和后处理来实现。
理解对抗样本的新观点
那么到底为什么会有对抗样本?它是不是深度神经网络中的一个 Bug?以前也有很多研究从理论模型解释对抗样本的各种现象,但是它们并不能解释所有观察到的东西。
MIT 的新研究提出了一种新的视角。与之前的模型相反,研究者将对抗脆弱性(adversarial vulnerability)作为主流监督学习机制的基础后果来看待。具体而言,他们表示:
对抗脆弱性是模型对数据中泛化较好的特征具备敏感性的直接结果。
他们的假设也对对抗可迁移性给出了解释,对抗可迁移性即为一个模型计算的对抗扰动通常可以迁移到另一个独立训练的模型。由于任意两个模型有可能学习类似的非稳健特征,因此操控此类特征的扰动可以应用于二者。最后,该研究提出的新观点将对抗脆弱性作为完全「以人为中心」(human-centric)的现象,因为从标准监督学习的角度来看,非稳健特征和稳健特征具备同等的重要性。
该论文表明,通过引入「先验」来增强模型可解释性的方法实际上隐藏了真正「有意义」和具备预测性的特征。因此,生成对人类有意义同时也忠实于底层模型的解释,无法仅从模型训练中获取。
MIT 的主要做法
为证实该理论,研究者展示了在标准图像分类数据集上将非稳健特征和稳健特征分离开来是可能的。具体而言,给定任意训练数据集,研究者能够构建:
稳健分类的「稳健」版本(见图 1a):研究者展示了从数据集中高效移除非稳健特征是可能的。具体做法是,创建一个与原始数据集语义相似的训练数据集,在其上进行标准训练后,模型可在原始未修改测试集上获得稳健的准确率。该发现表明,对抗脆弱性并非一定与标准训练框架有关,也有可能与数据集属性有关。
标准分类的「非稳健」版本(见图 1b):研究者构建一个训练数据集,输入与原始数据集几乎一致,但所有输入都是标注错误的。事实上,新训练数据集中的输入与其标签之间的关联仅通过微小的对抗扰动来维系(从而仅利用非稳健特征)。尽管缺乏有预测性的人类可见信息,但在该数据集上训练后,模型可在原始未修改测试集上获得不错的准确率。
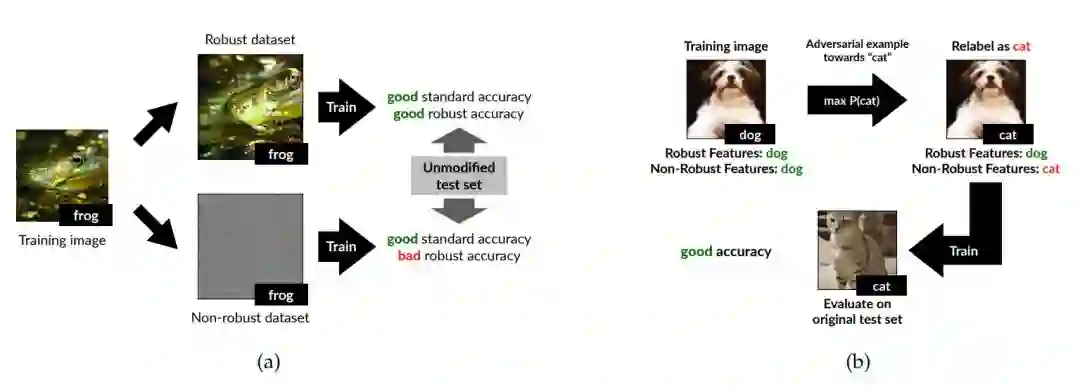
图 1:论文第三章中实验的概念图。在 a 中,研究者将特征分解成稳健和非稳健特征。b 中研究者构建一个数据集,由于对抗样本它对于人类而言是错误标注的,但它能在原始测试集上获得不错的准确率。
最后,研究者使用一个具体的分类任务,严谨地研究对抗样本和非稳健特征之间的联系。该任务包括分割高斯分布,使用模型基于 Tsipras 等人的模型,不过 MIT 研究者从以下几个方面对该模型进行了扩展。
首先,在该研究设置中,对抗脆弱性可以被准确量化为内在数据几何和对抗样本扰动集合的数据几何之间的差异。
其次,稳健的训练得到的分类器利用的是二者结合所对应的几何。
最后,标准模型的梯度会与类内方向产生更大的不匹配性,从而在更复杂场景中捕捉到实践中观测到的现象。
实验
该研究提出的理论框架的核心前提是在标准分类任务中存在稳健性和非稳健性特征,它们都能为分类提供有用的信息。为证实这一点,研究者进行了一些实验,实验的概念描述见图 1。
分解稳健性特征和非稳健性特征
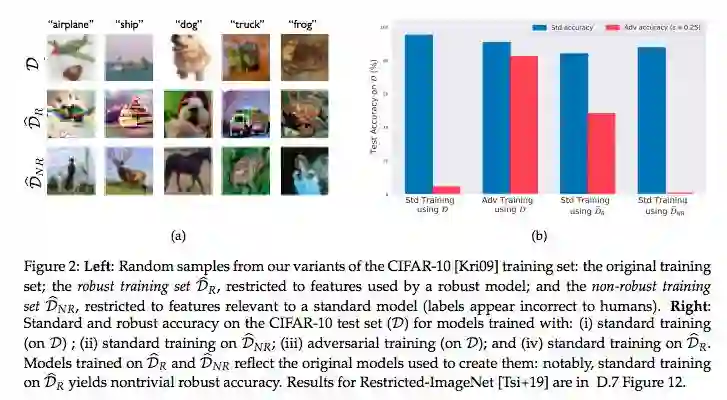
给出新训练集 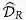
给出新训练集 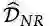
这些发现印证了对抗样本来自数据的(非稳健性)特征的假设。
非稳健性特征足以支持标准分类
仅在非稳健性特征上训练得到的模型能够在标准测试集上得到不错性能吗?研究者进行了实验。
使用对抗扰动 x 和目标类别 t,构建数据集 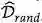

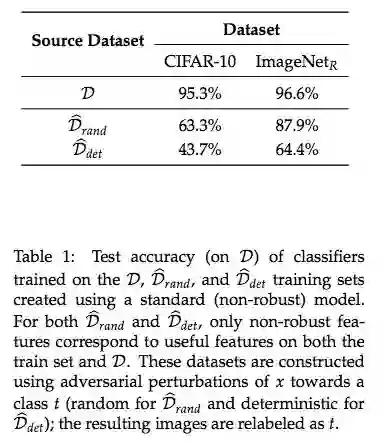
可迁移性
研究者在数据集

论文的核心理论框架
研究者提出了学习(非)稳健性特征的理论框架,但该框架的核心前提是在标准分类任务中存在稳健性和非稳健性特征,它们都能为分类提供有用的信息。在原论文第三章中,研究者提供了一些证据以支持这一假设,他们证明这两种特征是可区分的。
原论文第三章的实验表明,稳健和非稳健特征的概念框架强烈地预测了当前最优模型的经验性行为,而且是在真实数据集上的行为。为了加强对这些现象的理解,MIT 的研究者在具体环境中实例化这个框架,从而从理论上研究对应模型的各种属性。
MIT 研究者的模型与 Tsipras 等人 [Tsi+19] 的模型比较相似,某种意义上该模型包含了稳健性特征和非稳健性特征的二分法,但该研究提出的模型在很多方面对它进行了扩展:
对抗样本的不稳健性能明确地表示为内在数据度量标准和 L2 度量标准之间的差异。
稳健性学习正好对应于学习这两种度量标准的组合。
经过对抗训练后的模型,其梯度更符合攻击者的度量标准。
通过度量标准的不匹配性衡量易受攻击型(非稳健特征)
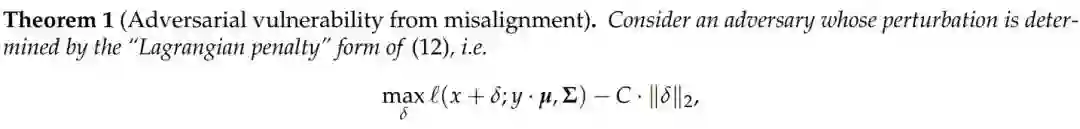
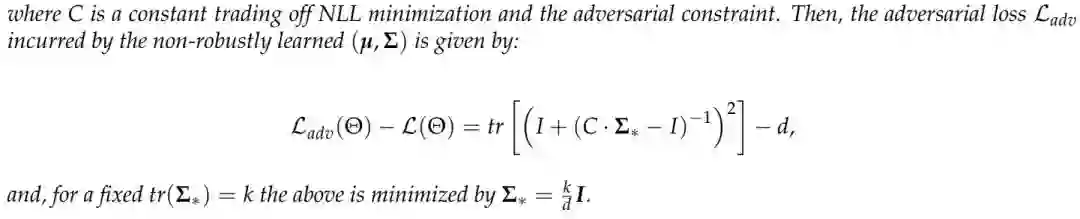
稳健性学习
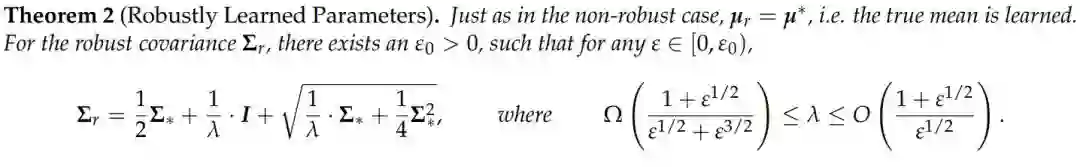
下图 4 展示了,在 L2 约束对抗性下的稳健性优化及其影响的可视化。
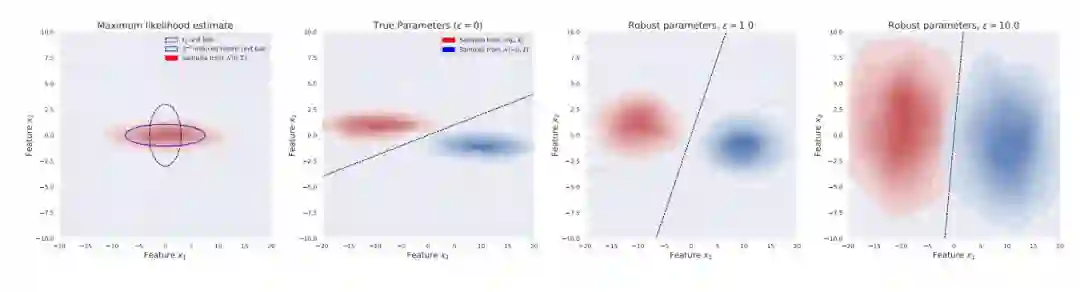
图 4:定理 2 影响的实证性演示,随着对抗扰动 ε 的增长,学习到的均值 µ 仍然为常数,但学习到的协方差「blend」为单位矩阵,有效地为非稳健性特征添加越来越多的不确定性。
梯度可解释性

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



