学界 | 继图像识别后,图像标注系统也被对抗样本攻陷!
机器之心发布
作者:Hongge Chen
近日,针对深度学习系统的对抗性样本攻击问题,来自麻省理工学院,加州大学戴维斯分校,IBM Research 和腾讯 AI Lab 的学者在 arXiv 上发表论文提出对于神经网络图像标注系统(neural image captioning system)的对抗样本生成方法。实验结果显示图像标注系统能够很容易地被欺骗。
深度学习系统正在越来越广泛地应用于各种场景中,帮助人类完成许多繁琐的工作。但是在很多方面上,计算机科学家们并不完全理解深度学习的工作机理。最近的研究显示,深度学习系统可能将两张人眼看不出任何差别的图片识别成两个完全不同的物体。这些样本的存在让人们对深度学习系统的鲁棒性提出了质疑。关于对抗样本的研究正在逐渐成为近期深度学习的热点方向之一。
与之前的相关研究不同的是,这一篇由来自麻省理工学院、加州大学戴维斯分校、IBM Research 和腾讯 AI Lab 的学者撰写的论文将对抗样本攻击延伸到了图像标注(image captioning)系统领域。图像标注标系统能从给定的图像中自动生成一段描述性文字。这一技术還能够帮助视觉上有障碍的人了解新闻、社交网站等媒体上的图像的含义。图像标注系统中的对抗样本同样有着严重的危害。想象一下,你的图片经过肉眼无法察觉的改造后,自动标注系统可能会对这张图片生成任何无关、完全相反甚至恶意的描述。
与仅由卷积神经网络(CNN)构成的图像识别分类器相比,图像标注系统由于涉及机器视觉和自然语言生成两个方面,结构更为复杂(Encoder-Decoder 结构,CNN+RNN),并且输出值所在的空间也要更大。在这篇文章中,作者设计了三种对抗样本的生成模式:
(1)有目标攻击(targeted attack):对于一张图片和一个目标标注句子,生成一个对抗样本,使得标注系统在其上的标注与目标标注完全一致;
(2)关键词目标攻击(targeted keyword attack):对于一张图片和一组关键词,生成一个对抗样本,使得标注系统在其上的标注含有所有的关键词;
(3)无目标攻击(untargeted attack):对于一张图片,生成一个对抗样本,使得标注系统在其上的标注与原标注无关。
作者通过一个求解优化问题来生成对抗样本,并设计了新颖的损失函数来实现高效的搜索。该方法成功地在 Show-and-Tell 模型和 MSCOCO 数据集上生成了人眼无法识别的对抗样本,并且这些对抗样本还能够迁移到带有 Show-Attend-and-Tell 模型上。

论文中的有目标对抗样本示例。新的标注都是人为指定的目标,而 Show-and-Tell 给出的标注和目标相同。左图中 Show-and-Tell 模型将一个关于纳达尔的对抗样本标注为了「一名女子正在浴室里刷牙。」;右图中 Show-and-Tell 模型将一个关于停车标志的对抗样本标注为了「一只棕色的泰迪熊躺在床上。」

论文中关键词目标攻击的示例。左图中给定「猫」、「狗」和「飞盘」三个关键词,生成了一个蛋糕图片的对抗样本使得 Show-and-Tell 模型给出了「一只狗和一只猫正在玩飞盘。」的标注。右图中给定「足球」、「群」和「玩」三个关键词,生成了一个长颈鹿图片的对抗样本使得 Show-and-Tell 模型给出了「一群年轻人在玩一个足球的游戏。」的标注。

文中无目标攻击的示例。左图中的披萨饼图片对抗样本使得 Show-and-Tell 生成了「几把雨伞坐在草地上。」的标注。右图中火车图片的对抗样本使得 Show-and-Tell 生成了「几只狗躺在地上」的标注。
给定一张图片 I,文中作者将寻找对抗扰动构造为一个由损失函数 loss 和 2-范数构成的优化问题:
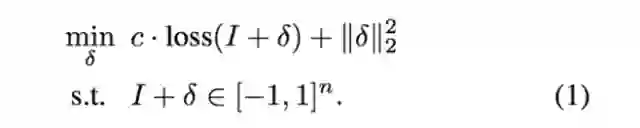
1.有目标攻击
给定一个目标标注句子 S,文中提出了基于未归一化的概率(logits)的损失函数和基于对数概率(log probability)的损失函数形式。
2.关键词目标攻击
给定一组关键词 K,文中也提出了两种损失函数形式,以鼓励所有的关键词都在标注句子中的出现。
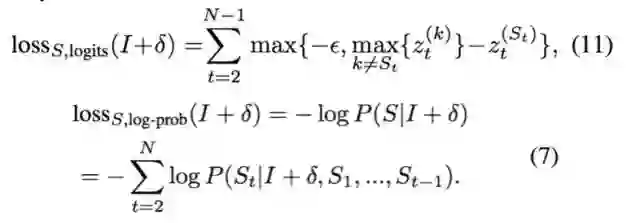
3.无目标攻击
文中还给出了两种用于在没有给定任何目标信息时的无目标攻击损失函数,使得对抗样本的标注和原始图片不同。

在 Show-and-Tell 模型和 MSCOCO 数据集上生成有目标攻击和关键词目标攻击对抗样本的成功率和平均 2-范数畸变

在 Show-and-Tell 模型上生成的对抗样本可以迁移到 Show-Attend-and-Tell 模型上,左图中 Show-and-Tell 模型将一个关于浴室的对抗样本标注为「一名男子在冲浪板上冲浪。」,而同一个对抗样本在 Show-Attend-and-Tell 上的标注结果为「一名男子在空中的冲浪板上。」。右图中 Show-and-Tell 模型将一个关于书桌的对抗样本标注为「一只猫躺在浴室里的盥洗台里。」,而同一个对抗样本在 Show-Attend-and-Tell 上的标注结果为「一只猫坐在浴室盥洗台里。」
论文:Show-and-Fool: 为神经网络图像标注系统设计对抗样本(Show-and-Fool: Crafting Adversarial Examples for Neural Image Captioning)

论文地址: https://arxiv.org/pdf/1712.02051.pdf
论文摘要:当今典型的深度学习图像标注系统(neural image captioning system)主要采用编码-解码的架构,包含两个主要的部分。其一是一个卷积神经网络(CNN),用于对图像特征的提取。其二是一个递归神经网络(RNN),用于标注句子(caption)的生成。我们从关于卷积神经网络的图像分类器对于对抗扰动(adversarial perturbation)的鲁棒性的分析中获得灵感,提出了名为 Show-and-Fool 算法来生成图像标注系统的对抗样本。与图像分类系统中仅有有限的分类标签不同的是,为图像标注系统生成人眼难以区分的对抗样本更加困难,因为可能的标注句子所在的空间几乎是无限大的。在这篇文章中,作者设计了三种对抗样本的生成模式:(1)有目标攻击(targeted attack)(2)关键词目标攻击(targeted keyword attack)(3)无目标攻击(untargeted attack)。我们通过一个求解优化问题来生成对抗样本,并设计了新颖的损失函数来实现高效的搜索。在 Google 的 Show-and-Tell 模型和 MSCOCO 数据集上该方法能够成功生成人眼难以分辨的对抗样本,使得 Show-and-Tell 模型输出给定标注。并且这些生成的对抗样本能够迁移到带有注意力机制的 Show-Attend-and-Tell 模型上。这些对抗样本的出现显示出对于深度学习图像标注系统鲁棒性分析的必要性。尽我们所知,这是第一个为图像标注系统生成有效对抗样本的工作。

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论。




